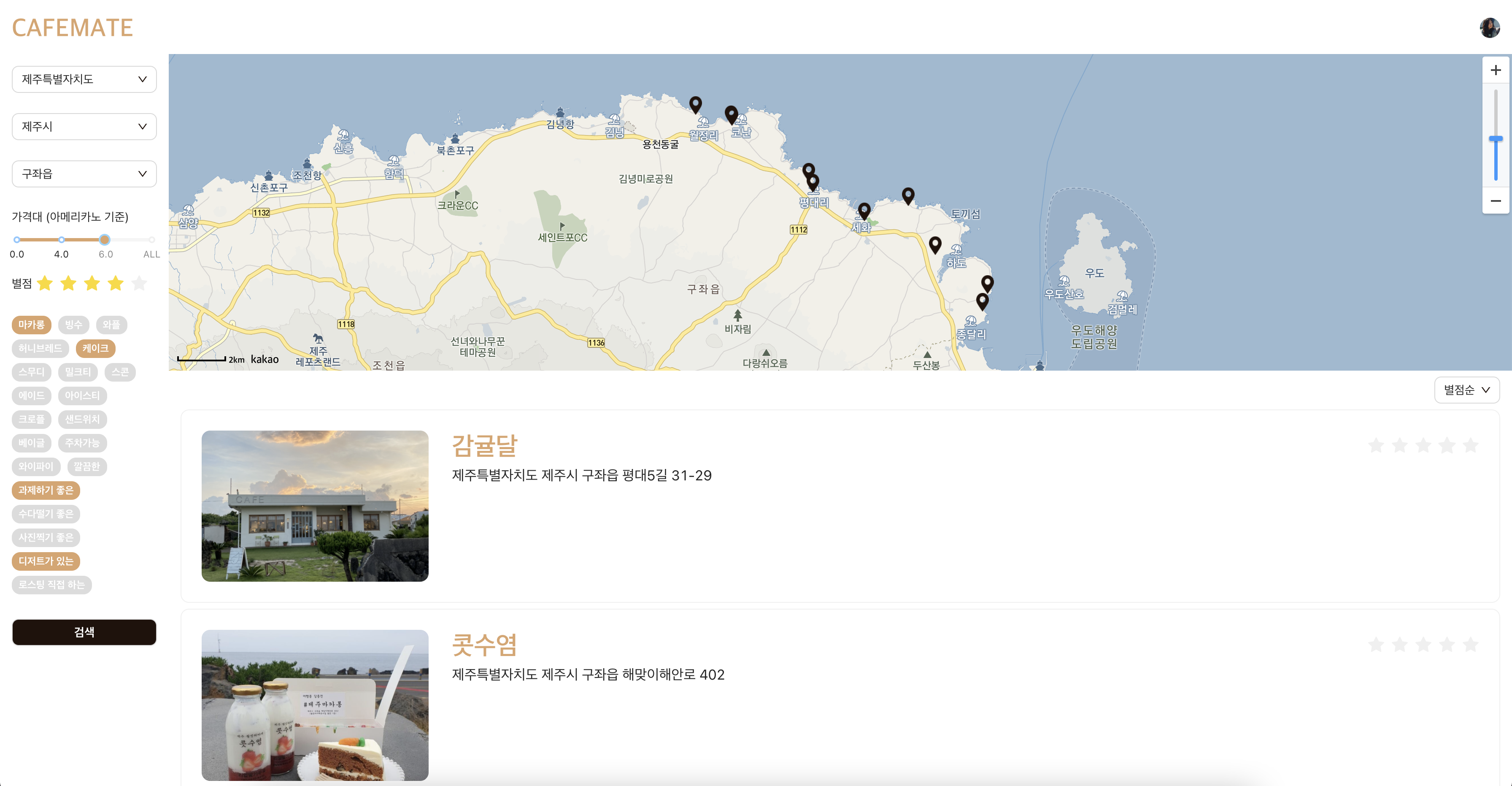
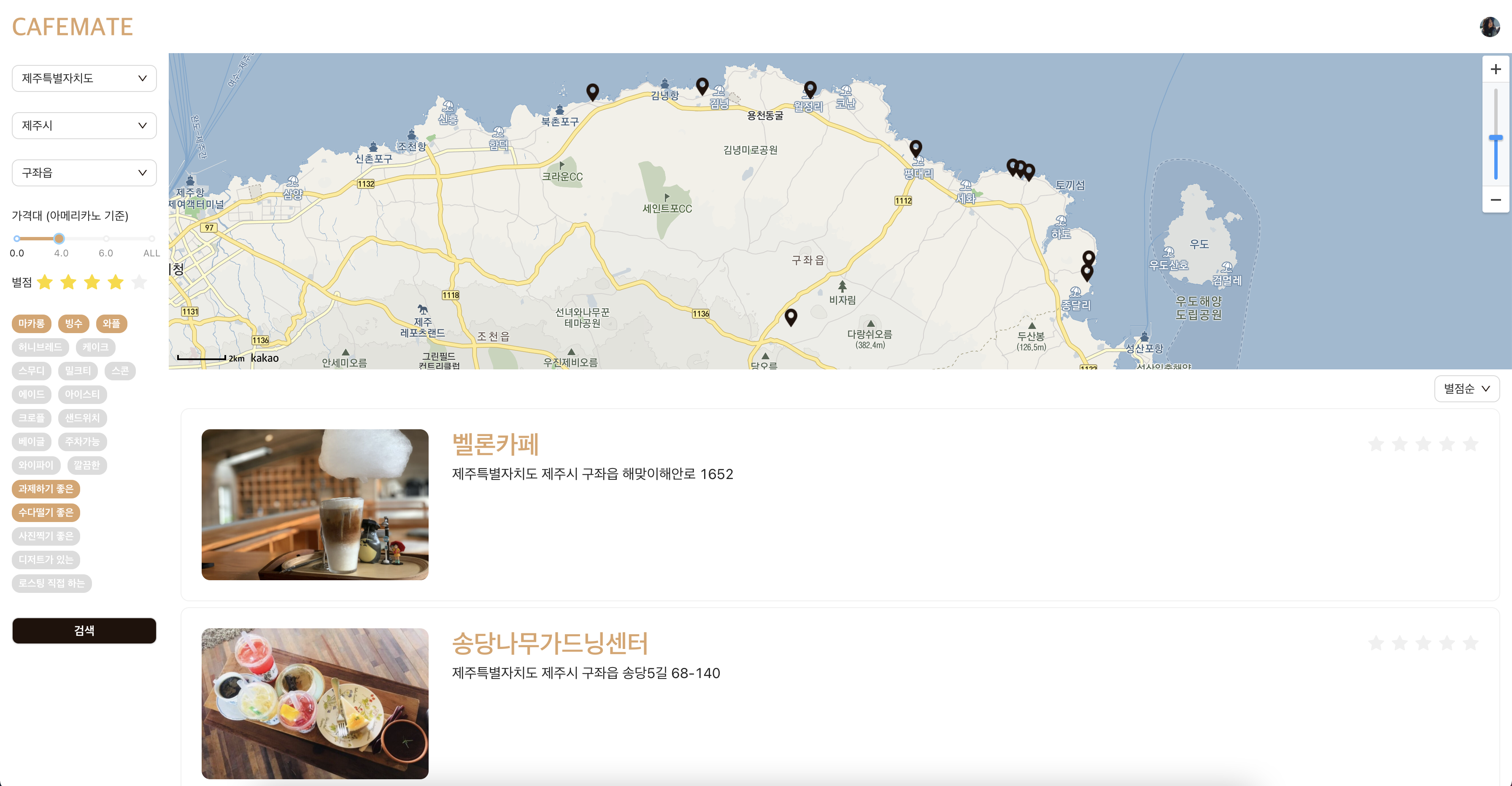
카페메이트팀은 지난 8월부터 6주간 '카페메이트' 라는 카페 데이터를 크롤링하여 '분위기가 좋은, 초코음료가 존재하는' 등의 필터링으로 맞춤 카페를 찾아주는 웹사이트를 개발하였다. 2명의 프론트엔드(React) 개발자와 2명의 백엔드(Spring) 개발자가 기획부터 DB 설계, API 설계, 개발, 배포를 진행하였다. 4명의 개발자 뿐만아니라 설계를 돕는 Project Manager와 TA(코드 리뷰) 2명이 함께하는 참여형 수업(카우치코딩 6주 포트트폴리오 수업)으로 진행되었다.
짜잔🙌 웹사이트 링크 : http://cafemate.shop
먼저 개발에 앞서 기술 스택을 아래와 같이 정했다. 팀원들이 써보고 싶었던 기술과 각 수준을 고려한 결론이었다.
- Front
- HTML, CSS, Javascript, React, redux, ant design
- Back
- Java - version 11, SpringBoot, Spring Data JPA, Gradle, MySQL, AWS - EC2, RDS
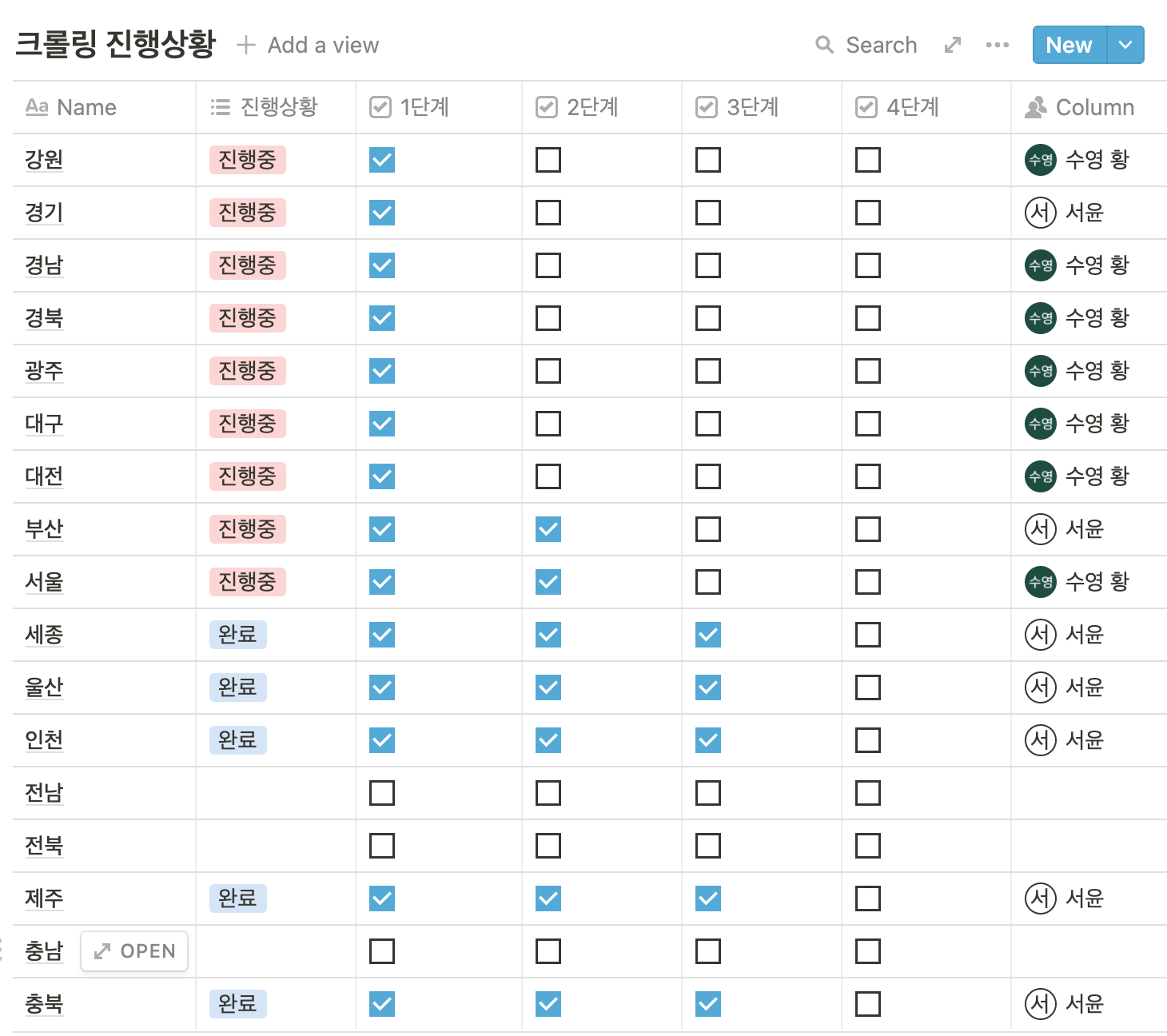
그 다음은 크롤러를 만들어서 카페 기본 데이터인 주소, 메뉴종류, 가격, 오픈시간, 전화번호 등을 수집하였다. 우리의 초기 계획은 서울 뿐만 아니라 경기, 경남, 경북 등 전국이었으나 데이터 수집 시간이 생각보다 오래걸리는 현실에 서울과 제주도에 한에서 크롤링을 하기로 타협하였다.
우리는 카카오 맵 API 를 통해 카페 데이터를 수집하고 키워드 추출하였다. 총 3단계로 아래와 같이 진행하였다.
1단계 : 카카오맵에 검색해서 상세페이지 url 따기
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
df = pd.read_csv(r"incheon.csv")
# 숫자 바꾸기
df = df[30000:40000]
df = df [(df ["상권업종중분류명"] == "커피점/카페")]
df = df[["상호명","지점명","시도명","시군구명","행정동명","도로명","도로명주소","경도","위도"]]
df.columns = ["name","sub","sido","sigungu","dong","address1","address2","long","lat"]
def search_url(keyword):
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
urlbase = "https://map.kakao.com/?q="
driver.get(urlbase + keyword)
soup = BeautifulSoup(driver.page_source, "html.parser")
url = soup.find("a", {"data-id": "moreview"})
driver.close()
if url:
return url["href"]
else:
return 0
for index, row in df.iterrows():
# 확인용
print("index: ", index)
address = "".join(row["address1"].split(" ")[2:])
name = row["name"] if pd.isnull(row["sub"]) else row["name"] + row["sub"]
url = search_url(address + " " + name)
if url:
df.loc[index, "url"] = url
else:
# 카카오맵에서 검색결과가 없는 곳은 삭제
df = df.drop(index)
# 뒤에 숫자 바꾸기!!!!!!!!!!!!!!!!!!!!!!!!1
df.to_csv("url_인천_4.csv")
2단계 : 상세페이지 방문해서 상세정보 추출하기
import time, re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
df = pd.read_csv(r'url_인천_4.csv')
df = df.iloc[: , 1:]
def search_info(url):
menu_list = []
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(3)
soup = BeautifulSoup(driver.page_source, "html.parser")
# 분류 확인
cate = soup.find("span", {"class": "txt_location"}).text
if "카페" in cate or "커피전문점" in cate:
# 대표번호
phone = soup.find("span", {"class": "txt_contact"})
if phone:
phone = phone.text
# 영업시간
hours = soup.find("span", {"class": "time_operation"})
if hours:
hours = hours.text
# 블로그 리뷰 링크들
review_links = []
reviews = soup.find_all("a", {"class": "link_review"})
for review in reviews:
review_links.append(review["href"])
# 시설 정보
tags = []
if soup.find("span", {"class": "ico_wifi"}):
tags.append("와이파이")
if soup.find("span", {"class": "ico_parking"}):
tags.append("주차가능")
menu_tags = ["마카롱", "빙수", "허니브레드", "케이크", "스무디", "밀크티", "에이드", "샌드위치", "아이스티", "와플", "크로플", "스콘", "베이글"]
dessert = ["마카롱", "빙수", "허니브레드", "케이크", "와플", "크로플"]
# 메뉴
menu = soup.find_all("div", {"class": "info_menu"})
for m in menu:
menu_name = m.find("span", {"class": "loss_word"})
menu_price = m.find("em", {"class": "price_menu"})
# 메뉴 이름, 가격 모두 있는 경우
if menu_name and menu_price:
menu_list.append(menu_name.text + ":" + menu_price.text.split(" ")[1])
for ex in menu_tags:
if ex in menu_name.text and ex not in tags:
tags.append(ex)
if ex in dessert and "디저트가 있는" not in tags:
tags.append("디저트가 있는")
# 메뉴 이름만 있는 경우
elif menu_name:
menu_list.append(menu_name.text)
for ex in menu_tags:
if ex in menu_name.text and ex not in tags:
tags.append(ex)
# 대표 이미지 URL
img = soup.find("span", {"class": "bg_present"})
if img:
img = re.findall(r"'//(.*?)'", img["style"])[0]
else:
# 카페가 아닐 경우
driver.close()
return False, []
driver.close()
return True, [phone, hours, review_links, menu_list, img, tags]
for index, row in df.iterrows():
# 확인용
print(index)
url = row["url"]
isCafe, info = search_info(url)
if isCafe:
df.loc[index, "phone"] = info[0]
df.loc[index, "hours"] = info[1]
df.loc[index, "reviews"] = ",".join(info[2])
df.loc[index, "menu"] = "/".join(info[3])
df.loc[index, "img"] = info[4]
df.loc[index, "tags"] = ",".join(info[5])
else:
# 카페가 아닌 항목은 삭제
df = df.drop(index)
df.to_csv("info_인천_4.csv")3단계 : 블로그 리뷰들 들어가서 키워드(태그) 추출하기
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from bs4 import BeautifulSoup
df = pd.read_csv(r'info_인천_4.csv')
desserts = ["마카롱", "빙수", "허니브레드", "케이크", "와플", "크로플", "디저트"]
themes = {
0: "과제하기 좋은",
1: "수다떨기 좋은",
2: "사진찍기 좋은",
3: "로스팅 직접 하는",
4: "깔끔한"
}
words_list = [
["조용", "스터디", "넓은 공간", "넓은 책상", "콘센트", "과제", "공부"],
["친구", "모임", "그룹", "수다"],
["인생샷", "인생 사진", "포토존", "소품", "분위기 좋", "좋은 분위기", "인테리어", "감성", "사진 찍기 좋은"],
["로스팅", "로스터기", "로스터리"],
["깔끔", "청결", "깨끗"]
]
def search(url, count):
hasDessert = False
# 네이버 블로그 일때만
if "naver" in url:
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
driver.get(url)
driver.implicitly_wait(10)
# 블로그 글 삭제된 경우
try:
WebDriverWait(driver, 3).until(EC.alert_is_present(),
'Timed out waiting for PA creation ' +
'confirmation popup to appear.')
alert = driver.switch_to.alert
alert.accept()
return hasDessert
except TimeoutException:
pass
driver.switch_to.frame("mainFrame")
r = driver.page_source
soup = BeautifulSoup(r, "html.parser")
# 블로그 본문 글만 저장
paragraphs = soup.find_all("p", "se-text-paragraph")
text = ""
for p in paragraphs:
text += p.text
for i, words in enumerate(words_list):
for word in words:
if word in text:
count[i] += 1
for dessert in desserts:
if dessert in text:
hasDessert = True
break
return hasDessert
for index, row in df.iterrows():
reviews = row["reviews"]
tags = row["tags"]
# 확인용
print(index)
# 리뷰 주소들이 있는 경우
if not pd.isna(reviews):
reviews = reviews.split(",")
new_tags = []
count = { 0: 0, 1: 0, 2: 0, 3: 0, 4: 0}
for url in reviews:
hasDessert = search(url, count)
if hasDessert:
new_tags.append("디저트가 있는")
# 제일 많이 나온 테마만 선택하기
max_i = max(count, key=count.get)
new_tags.append(themes[max_i])
# 기존에 태그가 있었던 경우
if not pd.isna(tags):
tags = tags.split(",")
new_tags = list(set(tags + new_tags))
# 기존에 태그가 한개도 없었던 경우
else:
new_tags = list(set(new_tags))
# 태그 업데이트
df.at[index, "tags"] = ",".join(new_tags)
# 불필요한 columns 정리
df = df.iloc[: , 1:]
df.drop(["url","reviews"],axis=1,inplace=True)
df.reset_index(drop=True)
df.to_csv('final_인천_4.csv')크롤링을 통해 수집한 데이터의 결과값(일부)은 아래와 같았다.
,name,sub,sido,sigungu,dong,address1,address2,long,lat,phone,hours,menu,img,tags
0,카페리아이올라,,인천광역시,남동구,간석3동,인천광역시 남동구 백범로248번길,인천광역시 남동구 백범로248번길 27,126.721646821902,37.4620123624663,032-463-3733,,,,
1,커피에반하다,당하점,인천광역시,서구,검단4동,인천광역시 서구 원당대로,인천광역시 서구 원당대로 676,126.676421125738,37.5932798776524,032-568-2932,,카라멜마끼아또/리얼과일스무디/프라페/아메리카노/카페라떼/에이드/민트초코라떼/허니브레드/허니브레드볼/미숫가루,t1.kakaocdn.net/thumb/T800x0.q80/?fname=http%3A%2F%2Ft1.daumcdn.net%2Fplace%2FF98D07A7512A46E5805B83EBB4C4D66E,"스무디,에이드,허니브레드,과제하기 좋은"
2,란비케이카페,,인천광역시,부평구,부평1동,인천광역시 부평구 경원대로,인천광역시 부평구 경원대로 1357,126.719811566412,37.4914112340736,,,,,
3,커피홉,,인천광역시,부평구,부평1동,인천광역시 부평구 광장로,인천광역시 부평구 광장로 16,126.723337286585,37.4895572235053,032-515-8513,,"아메리카노:2,000/카페라떼:2,500/오곡라떼:3,000/꿀녹차:3,000/딸기청라떼:4,000",t1.kakaocdn.net/thumb/T800x0.q80/?fname=http%3A%2F%2Ft1.daumcdn.net%2Fplace%2F07FA28DCA6F04429B79405887AFDB879,과제하기 좋은 또 항상 토이 프로젝트를 할 때마다 디자인이 아쉬웠는데, 이번 프로젝트에서는 언제나 예상 이하의 디자인을 개선하기 위해 Figma 라는 현업 디자이너 툴을 직접 사용하였다. 결과적으로 훨씬 깔끔한 웹 사이트 개발이 가능했다.
Figma 를 사용한 UI 기획서 📩
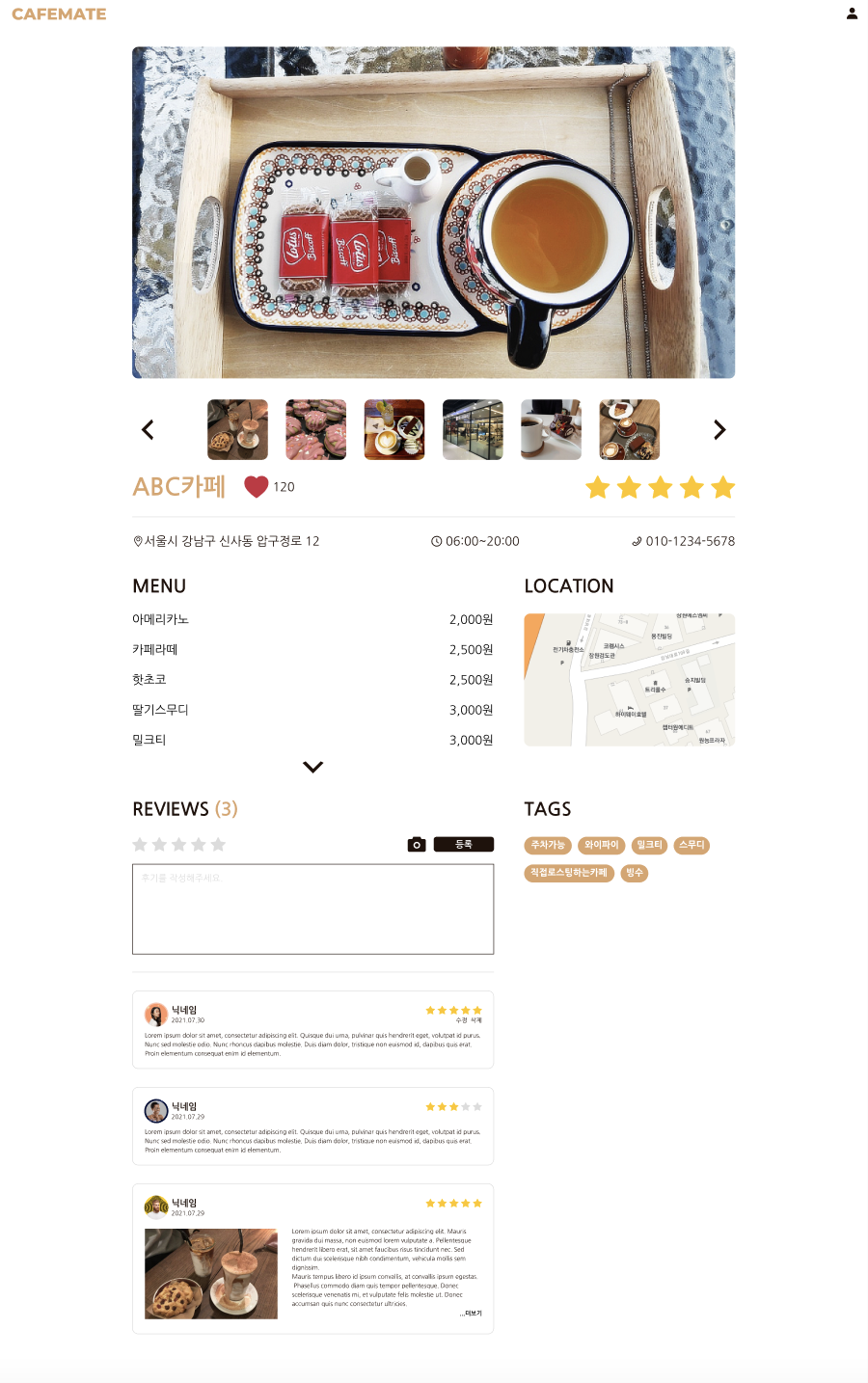
맞춤 카페 추천 웹사이트에 어떤 기능을 추가할 지 고민하면서 개발 범위를 정했는데 관심있는 기술스택(리액트, 스프링) 공부를 하면서 재밌는 프로젝트를 만들어서 취업하자는 우리의 취지에 맞게 아래와 같이 개발 범위를 정했다.
- 기본 CRUD
- 로그인/회원가입(구글 oAuth)
- 리스트 페이지
- 상세 페이지
- 입력 페이지
- 검색/필터링
- 페이징(인피니트스크롤링)
- 지도 API 사용(위치기반)
- 크롤러(데이터수집)
이제 위의 기능들을 위한 DB 와 API 설계를 진행하였다.
UI 페이지 기획서를 보면서 필요한 API를 리스트업하였고 중복되는 것은 없는지 토론을 통해 설계를 다듬어 나갔다. 결과물은 어래와 같다 :)
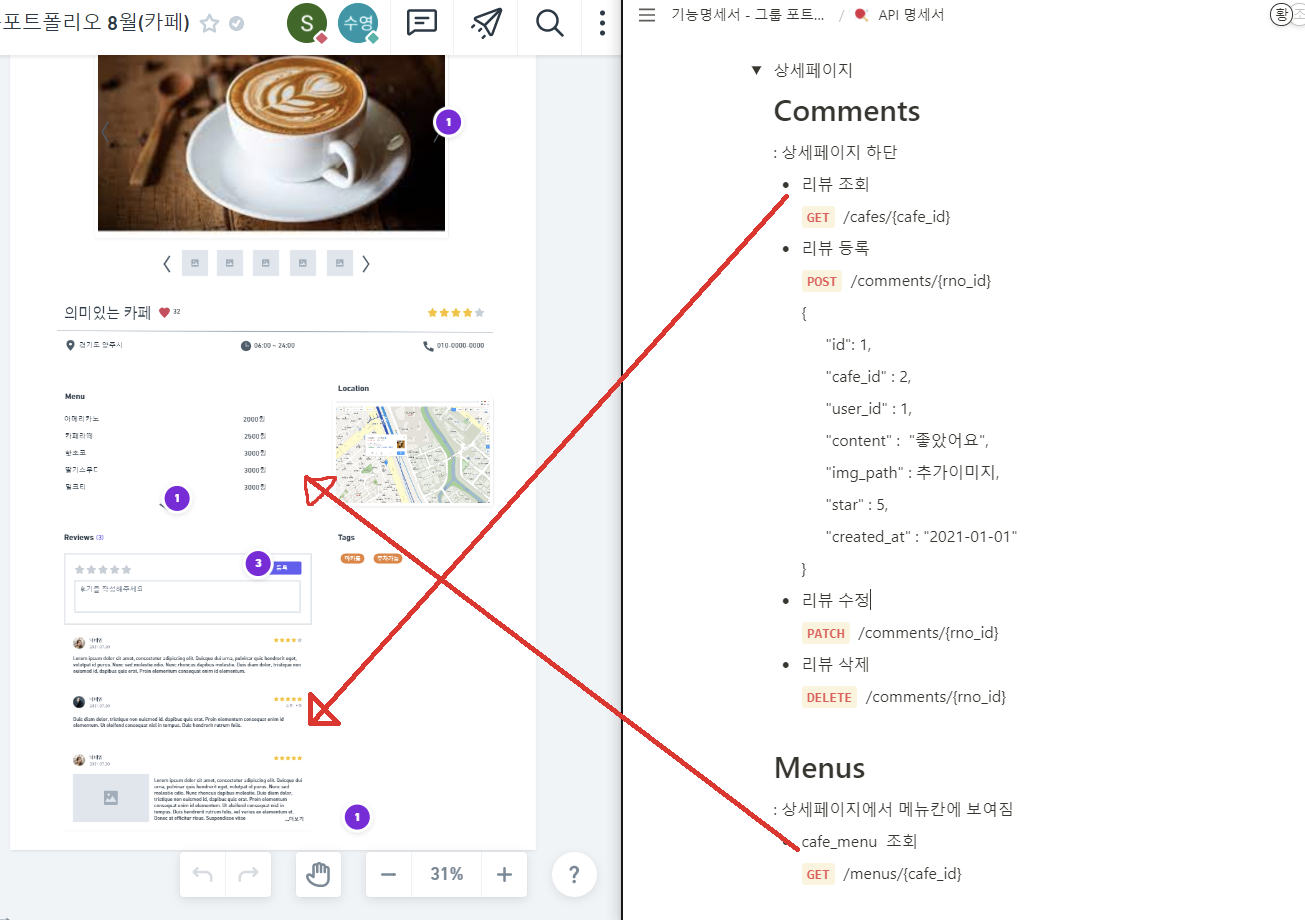
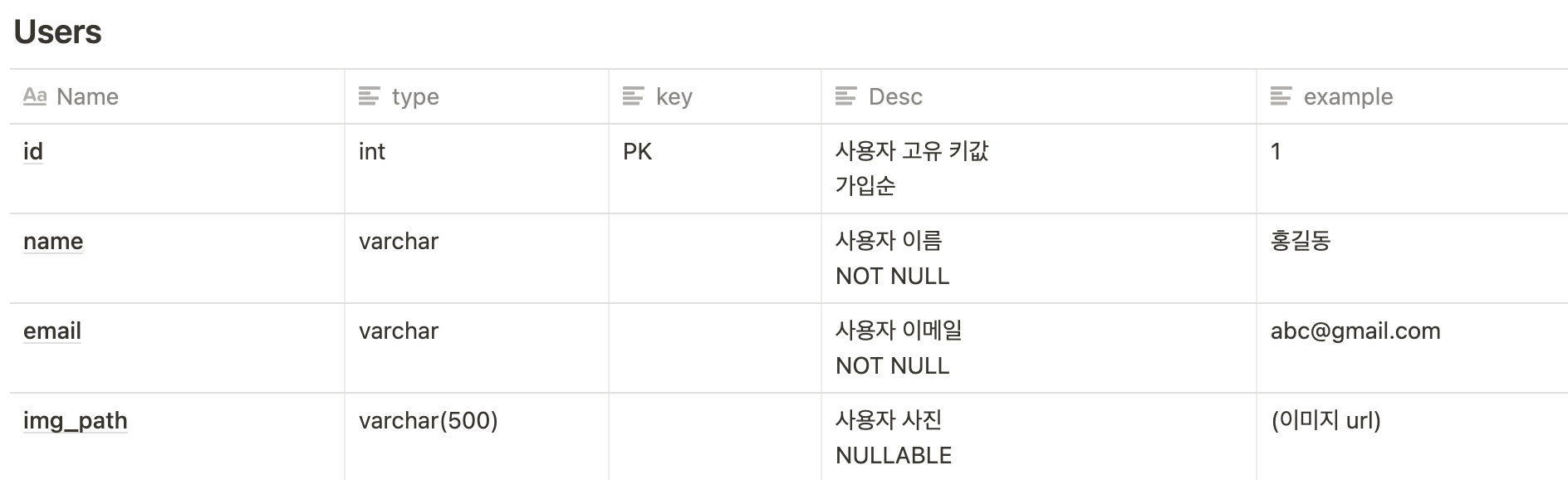
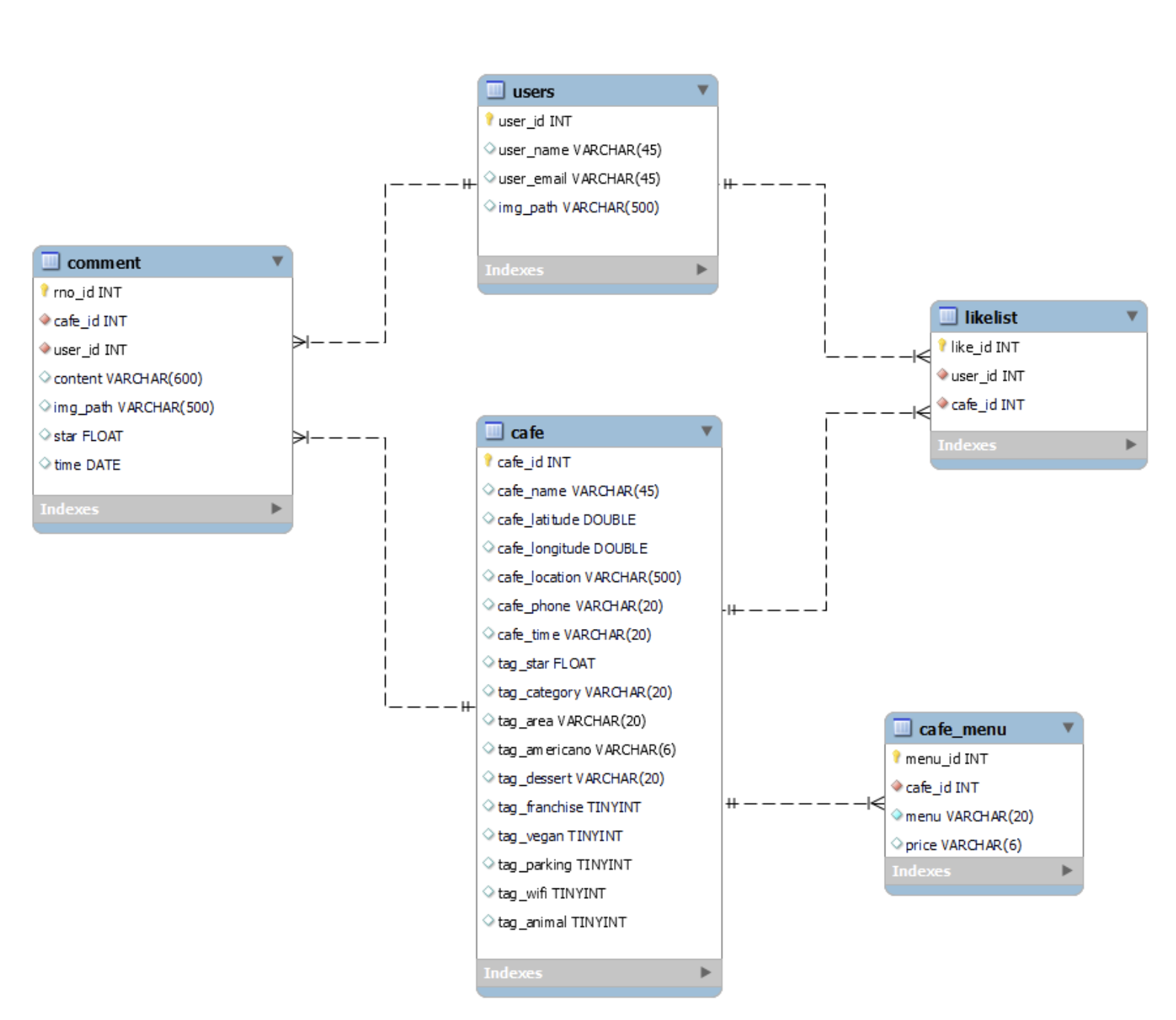
DB 명세서(일부)와 ERD
API 명세서

API 명세서 전문이 궁금하시거나 참고하시려면 아래 링크 참고하세요! :)
https://www.notion.so/API-f730b73b41b249a8a394cbbc4dc18213
이렇게 1-2주간의 웹사이트 기획과 설계가 끝나고 GitProjects 를 통해 Task Ticket을 생성하여 역할 분담을 나눴다. 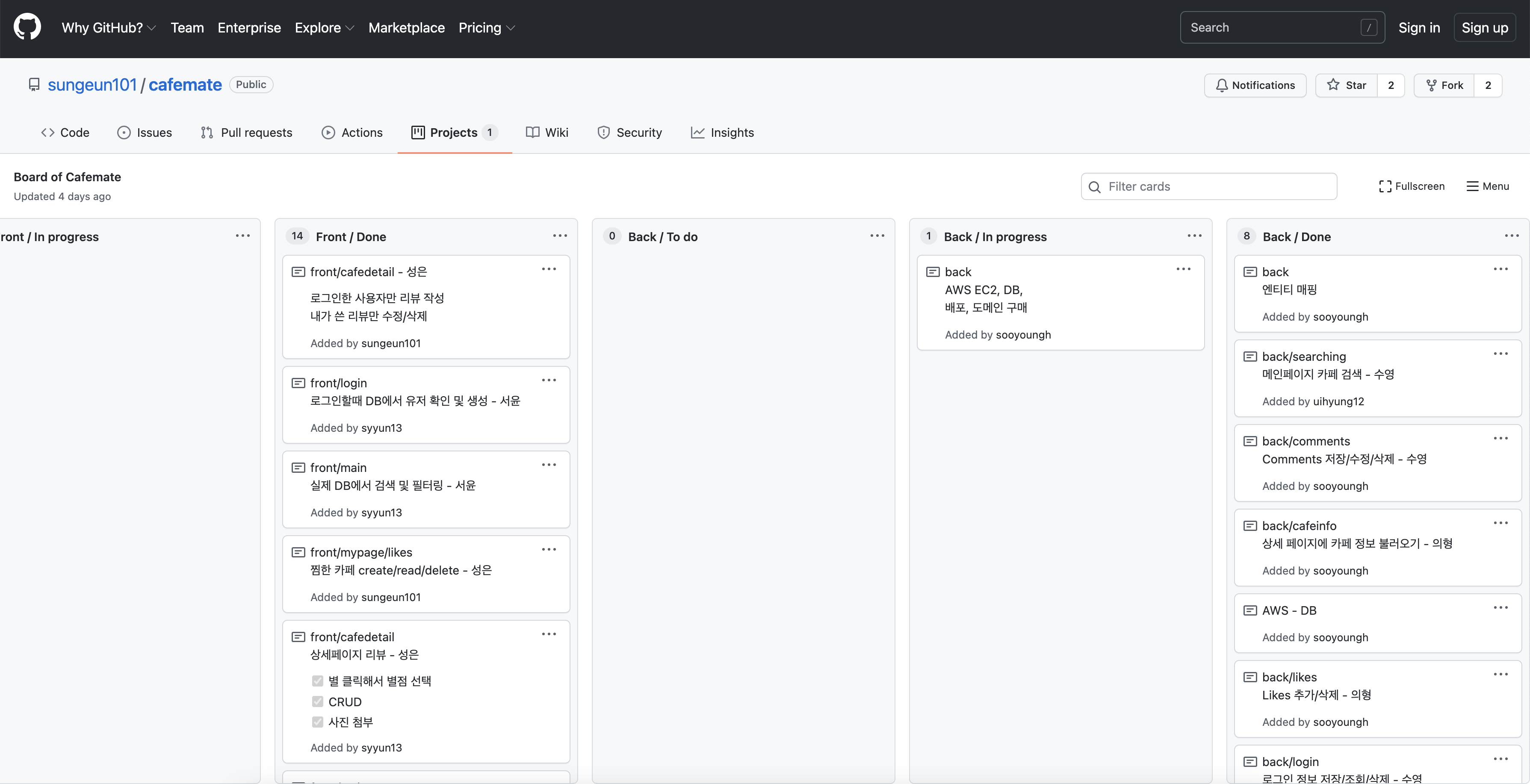
이번 프로젝트에서는 개발 단계에서 2가지를 추가하였는데,
- TA(teaching assistant)를 각각 프론트엔드, 백엔드 1명씩 코드리뷰를 긴밀하게 진행하였다. 그 결과 프로젝트 개발 속도 향상 뿐 만아니라 코드 퀄리티가 50%이상 개선되었다.
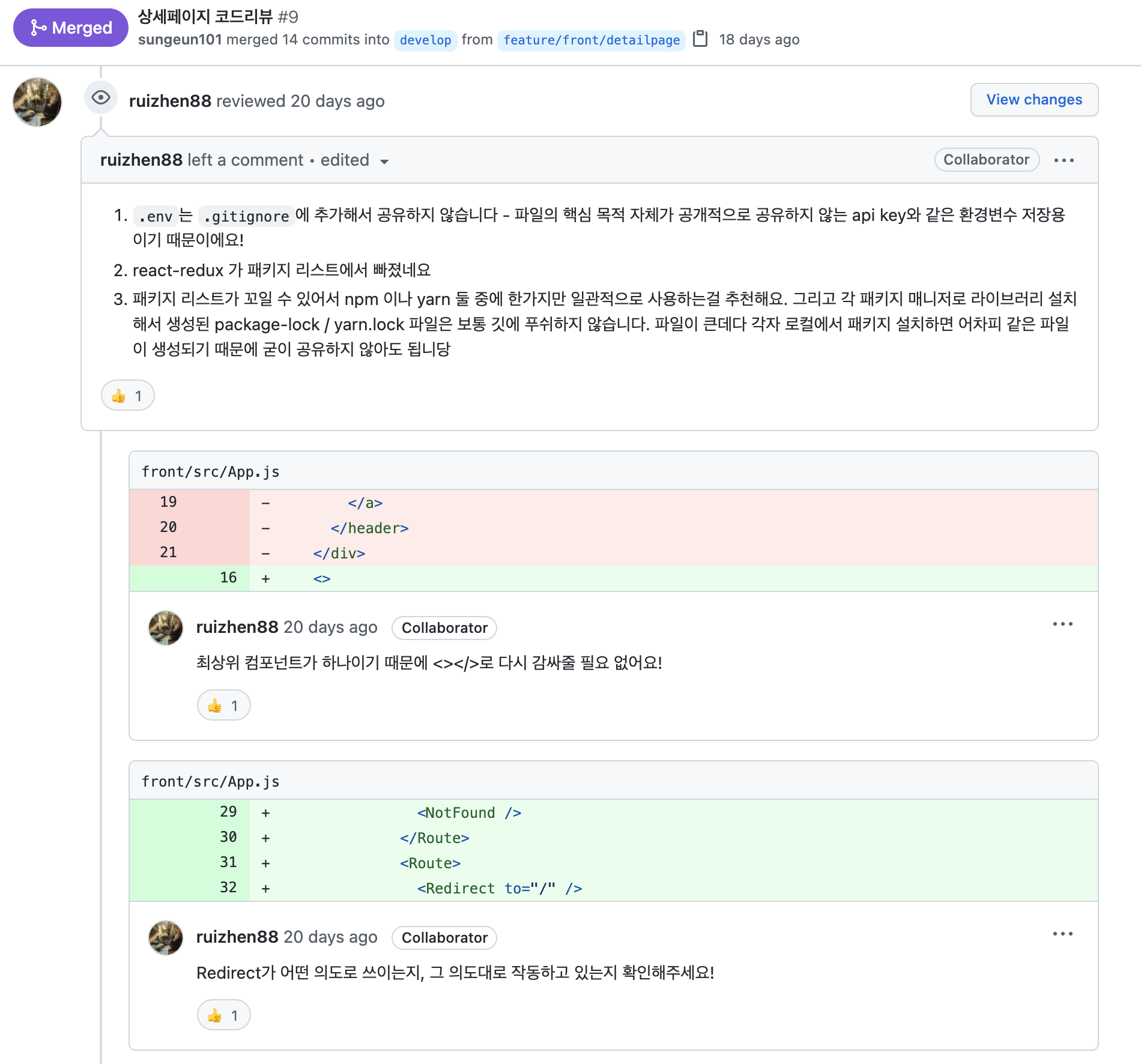
-
매일 팀별 스탠딩 미팅을 10분 내외로 하여 빠르게 개발 상황과 이슈를 체크했다. 3명 이상이 되면 커뮤니케이션 비용이 발생하는데 매일 빠르게 체크하여 커뮤니케이션이 빠르게 개선됬다는 느낌이었다.
-
TA 2명과 PM 총 3명의 멘토가 질의응답과 멘토링을 진행하여 막히는 순간 빠르게 대처가 가능했다. 특히 개발 막바지 일정 압박과 체력 소모로 자신감이 떨어지고 포기하고 싶어지는데 그럴 때 마다 서로 cheer up 을 하며 1:1 상담을 하며 끝까지 함께 프로젝트를 완성하였다.
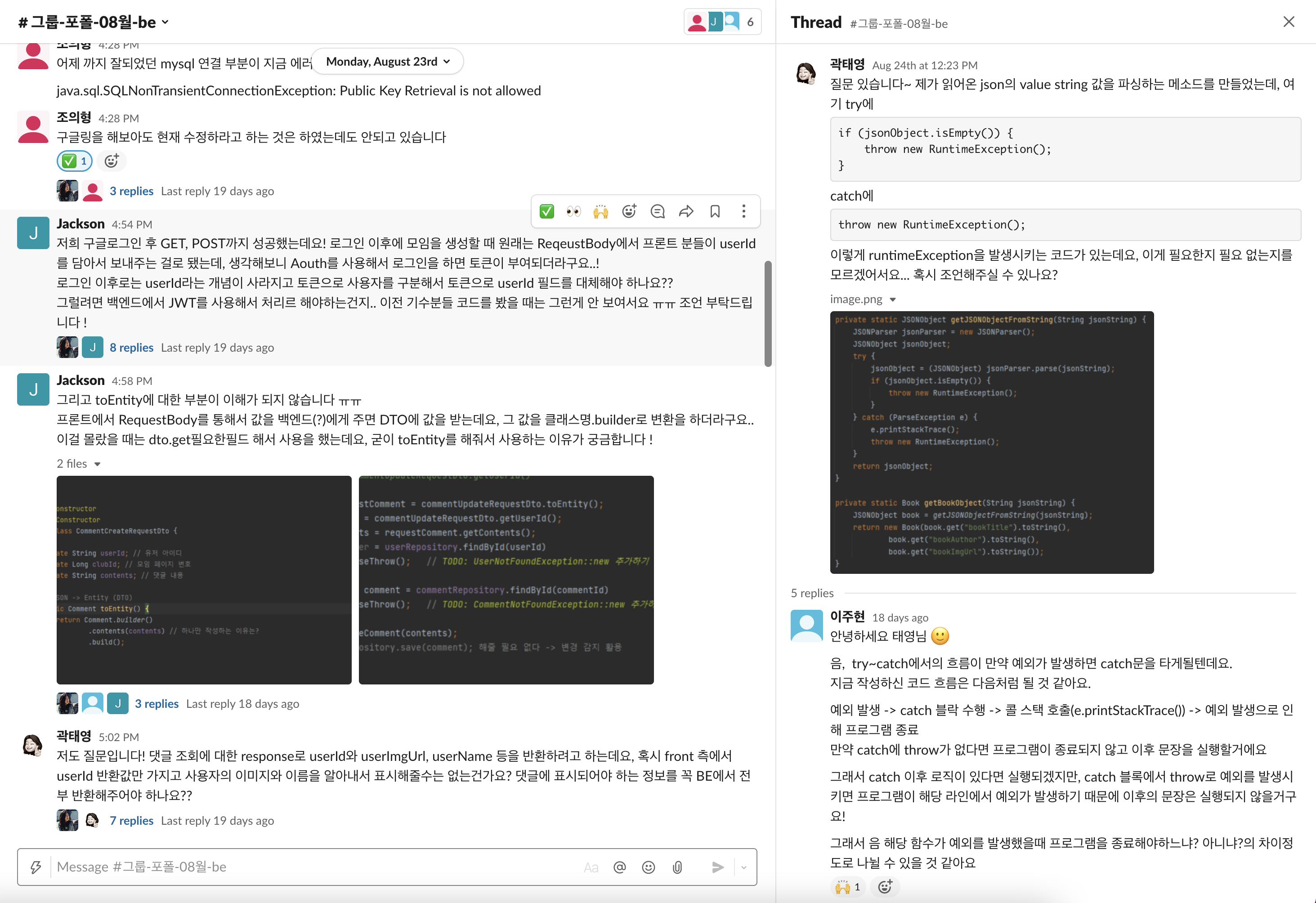
AWS 인스턴스에 배포를 하고 가비아 도메인을 연결하여 6주간에 치열하게 고민하고 밤낮없이 코딩했던 시간이 끝났다. 마지막 회고 시간에서 2명이 울었고 서로 커뮤니케이션을 하는 과정에서 오해와 힘든 점을 나누면서 말 그대로 '회고' 하였다. ㅎㅎ 프로젝트에 참여했던 수영, 의형, 성은, 서윤 모두 주니어 개발자로의 항해를 잘 준비하여 시작하였으면 좋겠다. 우리가 6주간 열심히 배웠고 토론하고 울고 웃었고 뿌듯함을 나눴던 6주의 시간이 개발자로 kick off 하는 모두에게 많은 도움이 되었으면 좋겠다.
끝~!💕
카페메이트, 맞춤 카페 찾기 웹사이트 🙌
웹사이트 주소 : http://cafemate.shop
Git 주소 : https://github.com/sungeun101/cafemate
기능 명세서 : https://www.notion.so/4241cfb8aab64592af099f34b2ccb938
UI 페이지 기획서 : https://www.figma.com/file/1FrTtdMDvn53kDvS93GHBL/%EC%B9%B4%ED%8E%98?node-id=0%3A1
DB 명세서 : https://www.notion.so/DB-45d7f01cbc334d40968bd39d2dfe84ad
API 명세서 : https://www.notion.so/API-f730b73b41b249a8a394cbbc4dc18213
이 프로젝트는 Project Manager와 TA(코드 리뷰) 2명이 함께하는 참여형 수업(카우치코딩 6주 포트트폴리오 수업)으로 진행되었습니다.
