2021.10.21 TIL
6-2. 회귀분석
관찰된 연속형 변수들에 대해 변수들 사이 모형으로 적합도를 측정, 독립변수 정보를 이용해 종속변수 예측.
y=β0 + β1x 꼴로 선형 회귀 모델이 세워진다.
단순 선형 회귀 분석
1) 회귀선 찾기
y=β0 + β1x꼴의 선을 찾아 최소 제곱법을 통해 최선의 직선을 찾아 구해진 선과 데이터 사이의 오차를 최소화 한다.
2) 검정
H0는 X변수가 Y변수와 선형관계가 없다, 즉 기울기 β1이 0이다.
H1은 X변수가 Y변수와 선형관계가 있다, 즉 기울기 β1이 0이 아니다.
로 수립한다. 검정통계량을 F검정,t검정을 이용해 설정하고 유의성을 검정한다.
- 선형회귀분석의 4가지 가정
-선형성 : 종속변수 Y는 독립변수 X에 대하여 선형적인 관계
-독립성 : 오차는 독립적이고 동일하게 분포하는 확률분포다.
-등분산성 : 분산 σ2는 모든 X에 대해 일정한 상수다.
-정규성 : 오차는 모두 평균이 0이고 분산이 σ2인 정규분포다.
선형회귀 모델 평가
- 잔차 분석
잔차를 시각화해 선형회귀분석 4가지 가정을 이용해 분석한다.- 유의성 검정
p-value를 이용해 선형관계를 확인한다.- Goodnes of fit
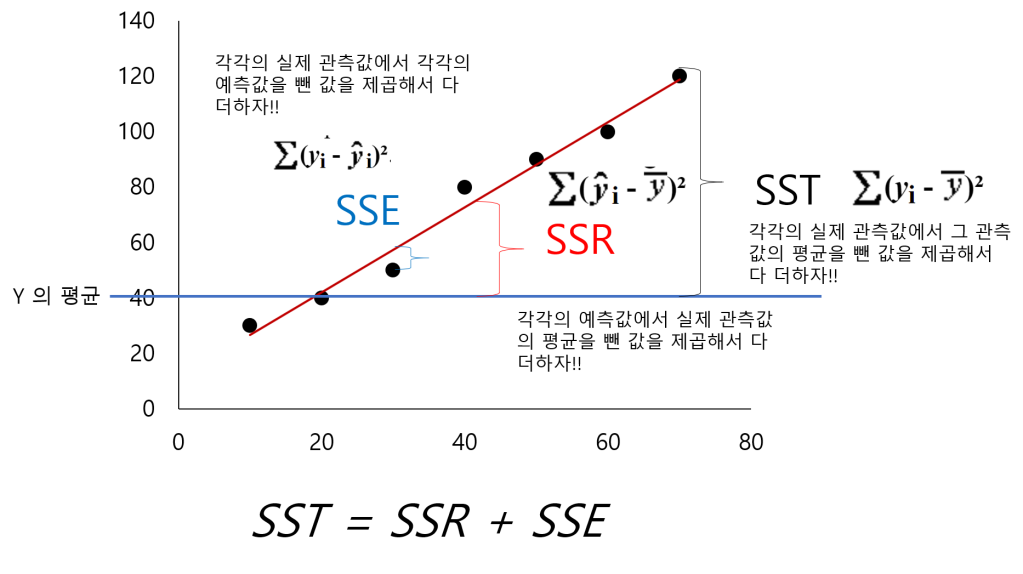
결정계수 R²을 이용한다. 결정계수 R²는 SSR(희귀모형에 의해 설명되는 변동)/SST(총 변동) 으로 계산한다.
출처 : https://agronomy4future.com
실제 관측량과 추정한 선형의 모형의 값을 비교한 수치로 적합성을 확인한다.
하지만 R²은 완전한 지표가 아니며, 다른 평가 지표와 함께 사용해야 한다.- Error Metrics
주요 지표들
출처:https://tex.stackexchange.com/questions/170372/increase-vertical-space-in-table

회구분석의 분류
- 차수에 따라 : 다항비선형회귀분석, 다항 선형회귀분석
- 독립변수의 개수에 따라 : 단순,다중회귀분석
- 종속변수의 개수에 따라 : 단변량,다변량 회귀분석
회귀모형평가의 기준
1)해석력 : 해석의 용이함
2)효율성 : 모형의 단순함
3)예측력 : 예측의 정확도
4)안전성 : 자료의 변함에 일정한 결과
7.머신러닝 개요/ 모형 평가
7-1. Machine Learning : Overview
머신 러닝의 종류
- 지도 학습 / Supervised learning
-학습 데이터 안에 입력값에 대한 출력값이 함께 제시되고 알고리즘이 입,출력값 사이의 관계를 설명하는 모델을 찾는다.
-해당 모델을 사용해 새로운 입력값에 대한 예측을 수행한다.
-출력값이 수치형이면 회귀, 범주형이면 분류 문제로 나뉜다.- 비지도 학습 / Unsupervised learning
-학습 데이터 안에 출력값이 없어 알고리즘이 학습 데이터 특징만을 활용해 목표 결과를 산출한다.
-적절한 군집을 찾고 변수 복잡성을 낮추는 차원 축소 등도 포함된다.
7-2. Machine Learning Workflow
분류 모델 - 예측 대상이 범주형 데이터인 경우
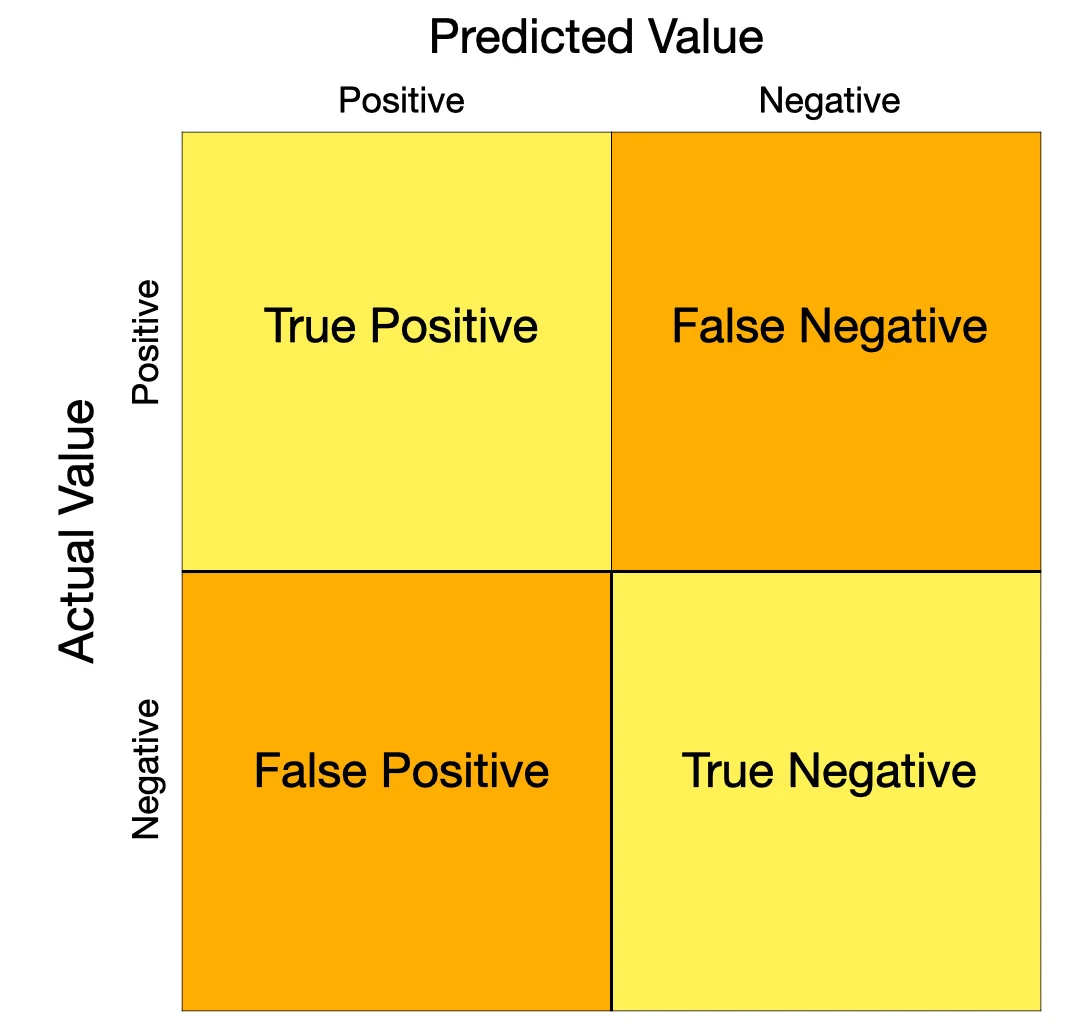
출처 : https://thehill.com/changing-america/well-being/prevention-cures/496651-false-positive-and-false-negative-coronavirus
해당 표를 통해 분류 후 Precision , Recall , Accuracy 세 지표로 평가한다.

출처 : StatsResource.github.io
Accuracy는 Actual Value의 참 , 거짓의 불균형이 있을 경우 과대평가될 가능성이 있다.
Recall은 타입1오류를 줄이기 위해 중요한 지표이다. Recall을 올리려 할 경우 Precision 이 줄어들 수 있지만 타입 1에러를 줄이는 것이 중요한 경우와 타입2 에러를 줄이는 것이 중요한 경우를 판단하여 설정해야 한다.
