1.데이터 베이스란?
여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합이다.
1-1.데이터베이스의 이점
- 주목적) 데이터의 크기와 상관없이 데이터를 안정적으로 저장하고 빠르게 검색할 수 있음
- 한 번에 여러 개의 테이블을 가질 수 있기 때문에 대용량에 유리함
1-2.데이터 베이스 요약
- 데이터 베이스는 데이터를 저장하고 관리할 목적으로 만들어졌다.
- MySQL은 현업에서 사용하는 여러 데이터 베이스 중 하나다.
- 데이터베이스에서 데이터를 관리하기 위해서는 SQL을 써야 한다.
1-3.데이터 베이스의 종류
- SQL 관계형 데이터베이스relational database와 소통하는 언어
- 구조화된 쿼리 언어 structured query language
- 관계형 데이터베이스RDB 데이터 구조가 고정된 데이터베이스
- Query 쿼리란, 질의문(검색어), 저장된 정보를 필터하기 위한 질문
- 모든 기업, 공공기관에서 데이터베이스 시스템을 구축하면 비효율적이므로, 데이터 보관/관리시스템을 운영하는 회사가 제공하는 시스템DB 사용
- 예시 MySQL, 오라클, MsSQL, PostgreSQL, SQLite 등
- NoSQL 비관계형 데이터베이스non-relational database와 소통하는 언어
- 예시 mongoDB, DynamoDB, couchDB
- ORM 프로그래밍언어(파이썬)를 SQL로 바꿔주는 시스템
- 예시 파이썬(장고ORM), 라라벨(eloquent ORM), node.js(sequelize, type ORM)
- SQL을 몰라도 ORM을 통해 개발할 수 있지만, 데이터베이스와 언어체계에 대한 이해도가 있다면 모델링에도 도움이 되고 더 빠르게 작업할 때나, 안될 때 대처할 수 있음
2.관계형 데이터 베이스
“데이터를 테이블의 형태로 저장하는 데이터베이스를 의미”
2-1.관계형 데이터 베이스 특징
- 관계형 데이터베이스는 테이블의 관계를 사용하여 데이터를 저장합니다.
- 관계형 데이터베이스는 표준화된 언어인 SQL을 사용하여 데이터를 조작합니다.
- 관계형 데이터베이스는 데이터의 정규화를 사용하여 데이터의 중복을 줄이고 데이터의 일관성을 보장합니다.
3.SQL(Structured Query Language)이란?
구조적 쿼리 언어(SQL)는 데이터베이스에 쿼리를 보내 원하는 데이터만을 가져올 수 있게 해주는 데이터베이스 용 프로그래밍 언어
3-1.SQL의 특징
- SQL은 관계형 데이터베이스를 조작하는데 사용되는 표준화된 언어입니다.
- SQL을 사용하면 데이터베이스의 데이터를 검색, 추가, 수정, 삭제할 수 있습니다.
- SQL은 실시간 데이터 분석을 위해 데이터를 집계, 조인, 그룹핑 등의 다양한 방법으로 조작할 수 있는 다양한 기능을 제공합니다.
3-2.SQL 종류
- DDL(Data Definition Language) : 오브젝트(테이블)를 정의할 때 사용되는 언어 /
CREATE(테이블생성),DROP(테이블제거) - DML(Data Manipulation Language) : 데이터를 변경할 때 사용되는 언어 /
INSERT(레코드추가),DELETE(레코드삭제),UPDATE(레코드변경) - DCL(Data Control Language) : 데이터베이스의 접근권한과 관련된 문법 / ****
GRANT(권한부여),REVOKE(권한가져가기) - DQL(Data Query Language) : 정해진 스키마 내에서 쿼리하는 언어, DML의 일부 /
SELECT(질문) - TCL(Transaction Control Language) : DML을 거친 데이터의 변경사항 수정 /
COMMIT(DML작업내용기록),ROLLBACK(커밋내용취소)
3-3.데이터베이스의 활용
- 데이터 적재(데이터모델링)
- 데이터모델링이란, 1) 데이터의 규칙을 정하고(ID 중복치없을것, 회사는 문자열), 2) 데이터베이스의 관계를 정하기(1:1, 1:N 등)
- 데이터 조회(쿼리날리기)
3-4.SQL JOIN 의 종류
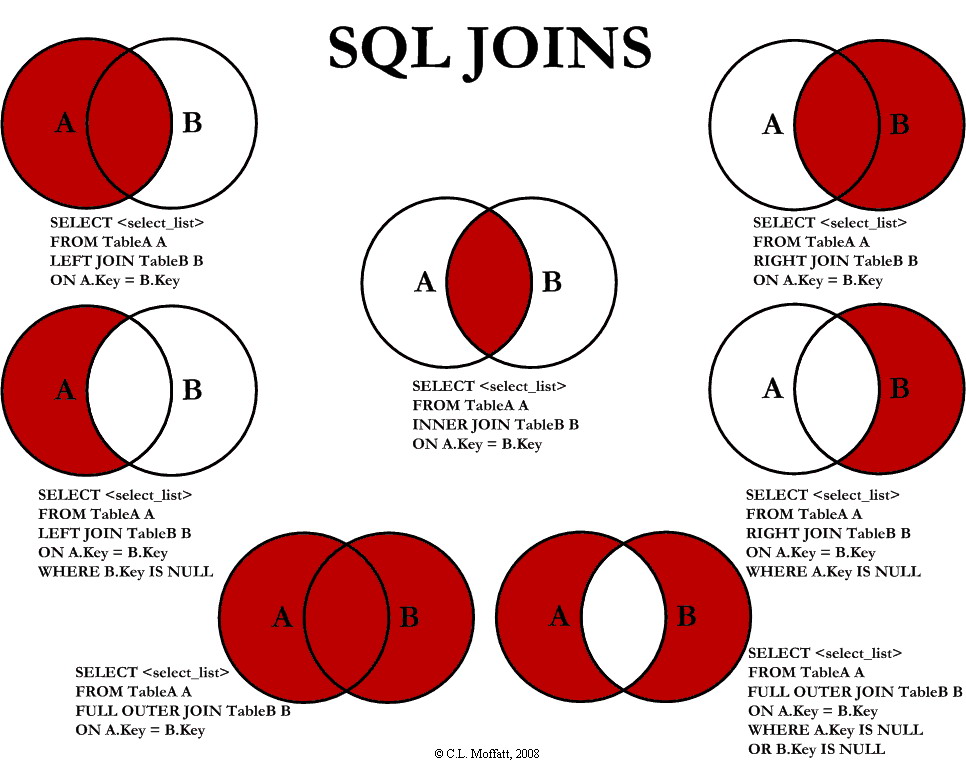
4.스키마란?
데이터베이스에서 데이터가 구성되는 방식과 서로 다른 개체(엔티티) 간의 관계에 대한 설명입니다.
스키마 강의자료
4-1.관계형 데이터베이스의 키워드
- 데이터 : 각 항목에 저장되는 값입니다.
- 엔티티 : 고유한 정보의 단위(DB에서 테이블로 표현됨)
- 테이블 : 사전에 정의된 행과 열로 구성되어 있는 구조화된 데이터입니다.
- 필드 (혹은 column) : 테이블의 열을 가리킵니다.
- 레코드 (혹은 tuple) : 테이블의 한 행의 저장된 정보입니다.
- 키 : 테이블의 각 레코드를 구분할 수 있는 값. 각 레코드마다 고유값이어야 하며 기본키 (primary key) 와 외래키 (foreign key) 등이 있을 수 있습니다.
4-2.데이터 베이스의 관계
테이블 간 관계는 다음과 같이 나눌 수 있습니다:
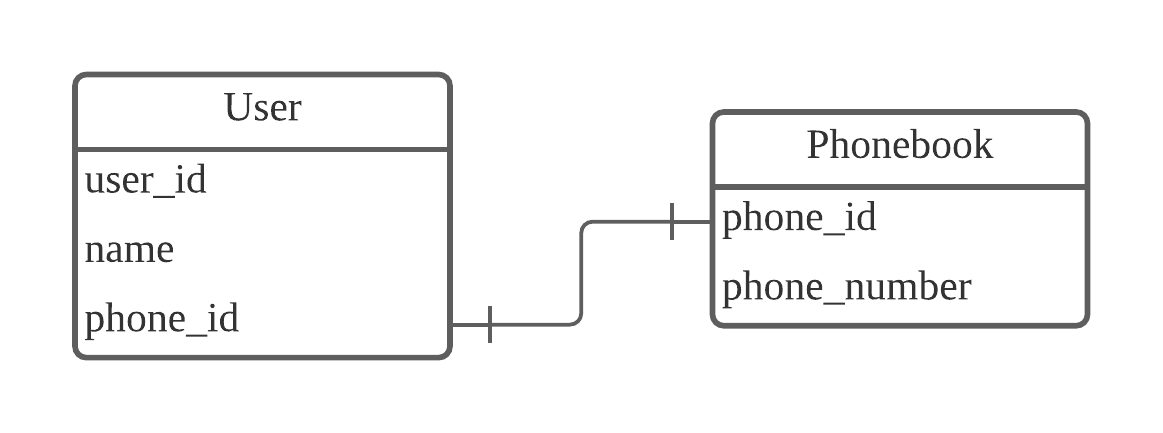
- 1:1 관계
- 1대1로 연결되어 있는 상태
- 유저 테이블에서는 유저의 이름과 'phone_id' 라는 외래키를 가지고 있습니다.
- 보통 하나의 테이블로 합치기 때문에 잘 발생하지 않음
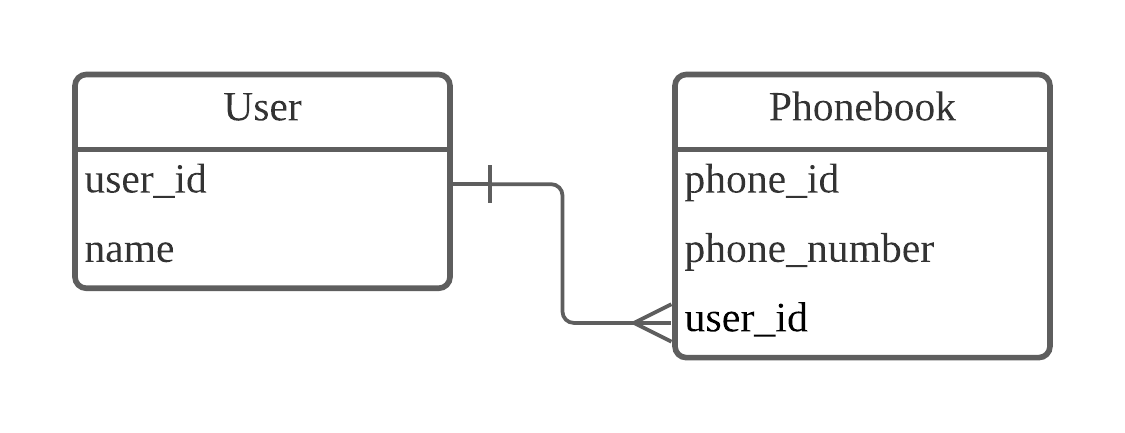
- 1:N 관계
- N의 테이블에 1의 테이블을 입력하여 중복없이 하나의 값으로 지정
- 테이블의 한 레코드가 다른 테이블의 여러개 레코드와 연결된 경우
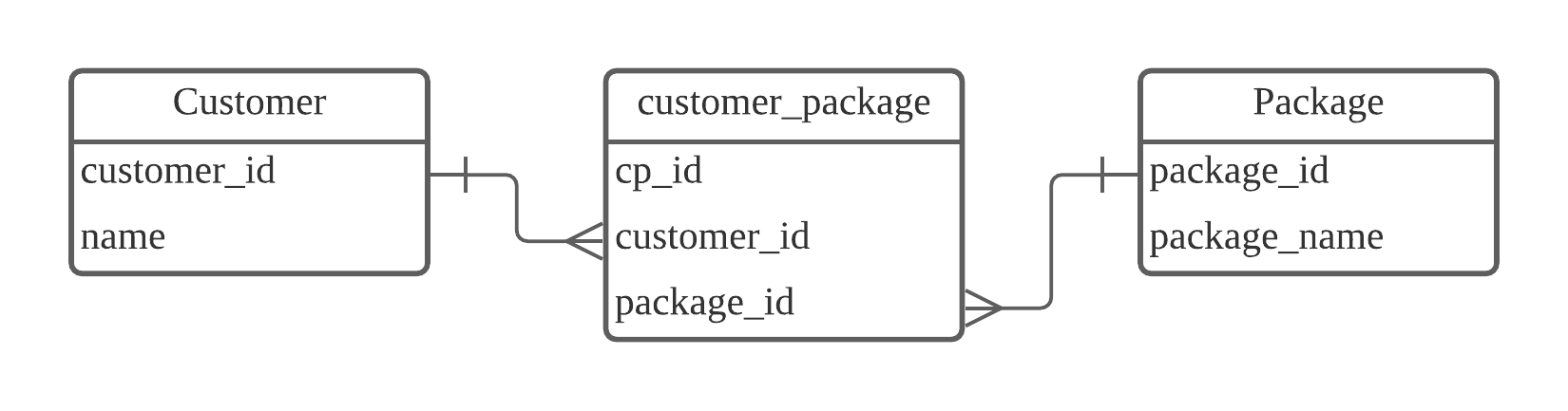
- N:N 관계
- • 여러개의 레코드가 다른 테이블의 여러개 레코드와 연결되는 경우
- *자기참조 관계 (Self Referencing Relationship)*
- • 테이블 내에서 필드끼리 관계를 가지는 경우
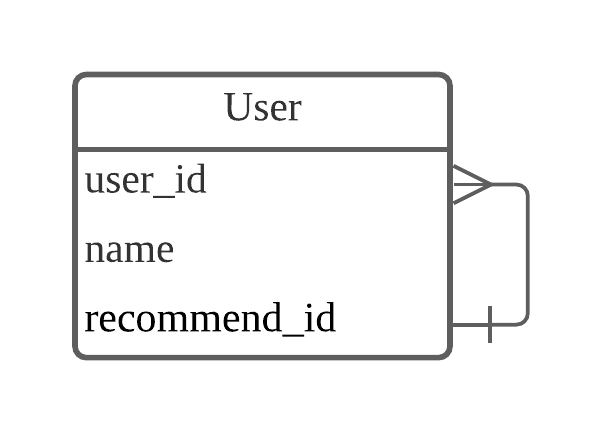
5.**SQLite DB언어**
CREATE TABLE
- 데이터베이스의 자료형
- INTEGER 숫자형(정수)
- VARCHAR(120) 문자열(120바이트까지)
- 적절한 데이터타입을 지정하지 않으면 오류 생길 수 있음
# 기본키칼럼에 조건 부여하고 싶을 때, 작성순서 주의
CREATE TABLE movies (
id INTEGER PRIMARY KEY NOT NULL,
title TEXT,
director TEXT,
year INTEGER,
length_minutes INTEGER
);
# 테이블 삭제
DROP TABLE TeacherPRIMARY KEY
# 기본키 자동부여
CREATE TABLE Teacher(
id INTEGER Primary key AUTOINCREMENT #미지정시 자동부여
name VARCHAR(30),
subject VARCHAR(10) NOT NULL,
salary INTEGER
);
# 기본키 2개로 지정하는 경우
CREATE TABLE Student(
teacher_id INTEGER NOT NULL,
student_id CHAR(4) NOT NULL,
age INTEGER NOT NULL,
Primary KEY(teacher_id, student_id)
)추가적인 개념
- ALTER TABLE https://extbrain.tistory.com/39
- NOT NULL
- UNIQUE
- FOREIGN KEY
- DEFAULT
- Auto Increment
- DATES
6.SQLite 쿼리문
※ 주석 ,,, ※ 세미콜론; : 명령 하나가 종료되었다 / 여러개 쿼리 짤 경우 ※ SQL 대소문자 : 명령어는 대소문자 구분안하나(프로그램 따라), 문자열에선 대소문자 구분
- “SQL이 대문자인 이유" ※ INT와 INTERGER은 다름
SELECT조회, FROM테이블선택
SELECT 'hello world';
SELECT 1+3;
SELECT *
--와일드카드 * = all 전체선택의 의미
SELECT Album.Title FROM Album;
-- = SELECT Title FROM Album;
# As 사용
SELECT a.Title FROM Album As a
# As 없이
SELECT a.Title f FROM Album a
# 별명 한글 가능
SELECT DATETIME 시간 FROM ANIMAL_INS
ORDER BY DATETIMEWHERE조건
- 문자열은 대소문자 구분, 따옴표'' ""로 묶어야 함
# 특정값을 가진 레코드(행)의 필드(열)값 가져오기
SELECT a.Name FROM Artist As a
WHERE Name='AC/DC'
# 날짜조건 검색
SELECT EmployeeId FROM employees e
WHERE e.HireDate < '2013-01-01'
Order by LastName
# 조건이 여러개일때
Select Invoiceid From Invoices
Where customerid in(29, 30, 63) and Total between 1 and 3
# = 특정값을 가진 레코드(행) 전체 가져오기 (반대 !=, <>)
SELECT * FROM Artist As a
WHERE Name='AC/DC'
# <> 고객테이블에서 lisbon출신 제외한 고객의 전체레코드(행) 가져오기
SELECT * from Customer WHERE City <> 'Lisbon'
# BETWEEN AND : 이상이하inclusive
SELECT * FROM movies
Where year NOT BETWEEN 2000 and 2010 #이상 이하(inclusive)
# IN : 리스트내의 값에 포함된 값(반대 NOT IN)
SELECT * FROM movies
Where year IN (2000, 2001)
Select i.invoiceid From Invoices i
Where i.BillingCity In('Stuttgart','Oslo','Redmond')
Order by i.InvoiceId;
# LIKE : 특정문자열과 비슷한 값 (% 혹은 *)
SELECT * FROM movies
Where Title Like "%Toy Story%"
SELECT * FROM movies
Where Title Like "Toy Story%" #토이스토리로 시작하는 값만
SELECT * FROM movies
Where Title Like "%Toy Story" #토이스토리로 끝나는 값만
SELECT Albumid FROM ALBUMS a
Join Artists ar
on a.Artistid = ar.Artistid
WHERE Name Like "%the%"
SELECT * FROM movies
Where Director NOT LIKE "John Lasseter"
# IS NULL : is는 null 등의 값 찾을 때 사용
SELECT * FROM employees
WHERE employees.ReportsTo is NULL;
SELECT * FROM employees
WHERE employees.ReportsTo is NOT NULL;ORDER BY정렬
- 기본정렬은 오름차순asc / 내림차순desc
SELECT * from Customer
WHERE CustomerID > 10
Order by FirstName ;
SELECT * FROM movies
Order by Year DESC
LIMIT 4;LIMIT, OFFSET상위(하위), 컷
- LIMIT 돌려받는 데이터 결과의 개수 / 마지막에 추가해야 함
- OFFSET n개 건너뛴 후의 레코드
# 상위 4개만
SELECT * FROM movies
Order by Rating DESC
LIMIT 4;
# 하위 4개만
SELECT * FROM movies
Order by Rating
LIMIT 4;
# 상위 4,5위만
SELECT * FROM movies
Order by Rating DESC
LIMIT 2
OFFSET 3;DISTINCT고유값
# 직책 리스트 추출(고유값만)
SELECT DISTINCT employees.Title FROM employees;
# 감독 리스트 추출
SELECT DISTINCT Director FROM movies
Order by Director;
# 고유값 개수만
Select g.Name genre_name, count(DISTINCT i.customerid) Num_total From invoice_items ii
# 여러 특성의 고유조합(유니크한 조합)만
# 남 A형, 남 B형, 여 A형, 여 B형...
SELECT DISCTINCt gender, blood_type FROM studentsGROUP BY그룹핑(고유값)
- DISTINCT와 비슷하게 사용될 수 있으나 조금 다름
Select count(c.Country) Num_Total From customers c
Group by Country;INSERT Into
# 기본키 AUTOINCREMENT(자동지정)의 경우, 기본키값이 비어있어도 무결성을 해치치 않음 = 추가가능
# AUTO 미지정의 경우, 기본키 값 비어있으면 에러 발생
INSERT into Teacher(name, subject, salary) VALUES ('Spongebob', 'Math', 3500);COUNT, DATE
Select g.Name genre_name, count(DISTINCT i.customerid) The_Number_of_customer_ID From invoice_items ii
Join invoices i
on i.Invoiceid = ii.invoiceid
Join tracks t
on t.Trackid = ii.trackid
Join Genres g
on g.genreid = t.genreid
Group by g.Name
Select i.id, i.customer_id, date(i.invoice_date) 날짜, i.invoice_amt From Customers c
RIGHT Join Invoices i
on c.id = i.customer_id
Order by i.invoice_amt desc, i.invoice_date, i.idJOIN
- LEFT JOIN(=LEFT OUTER JOIN)
- SQLite는 RIGHT OUTER JOIN, FULL OUTER JOIN 지원하지 않음
- 차집합은 트리키한 코딩테스트에서 나옴
#아티스트아이디가 아닌 이름으로 보고 싶을 때 / 가수이름과 타이틀명만
Select a.Title, ar.Name
From Album a
JOIN Artist ar
ON a.ArtistID = ar.ArtistID;
SELECT Distinct building_name, e.Role FROM Buildings b
Left Join Employees e
On b.building_name = e.building
Select c.id, c.name, i.invoice_amt From Customers c
Left Outer Join Invoices i
on c.id = i.customer_id
Where i.invoice_amt IS NULL|| 칼럼 결합, SUBSTRING문자열추출, rowid인덱스칼럼 생성
# 칼럼 결합 추가 / 대문자화
SELECT Customerid, Upper(City || ' ' || Country) c FROM customers c
# 칼럼 결합 / 정렬순서 지정 시
SELECT (c.FirstName || c.LastName || i.InvoiceId) FROM invoices i
JOIN customers c
ON i.CustomerId = c.CustomerId
ORDER BY c.FirstName, c.LastName, i.InvoiceId
# 칼럼의 문자열값 추출 / 소문자화
SELECT LOWER(SUBSTRING(FirstName, 1, 4) || SUBSTRING(LastName, 1, 2)) newid FROM customers c
# 번호순서대로(인덱스순서대로) 값 가지는 칼럼 추가
SELECT teacher_id, student_id, rowid '전체 학생순서' FROM Student
# 그룹화하여 순서부여하는 칼럼 추가
SELECT teacher_id, student_id,
ROW_NUMBER () OVER (PARTITION BY teacher_id) '선생님별 학생순서'
FROM Student서브쿼리
# ALBUM이름이 unplugged이거나 track이름이 outbreak인 경우
Select Name From tracks
WHERE ALBUMid IN (SELECT ALBUMID FROM Albums WHERE albums.title = 'Unplugged')
OR albumid in (SELECT Albumid from tracks WHERE tracks.Name = 'Outbreak')
# ALBUM이름이 unplugged이거나 outbreak인 경우
Select Name From tracks
WHERE ALBUMid IN (SELECT ALBUMID FROM Albums WHERE albums.title in('Unplugged', 'Outbreak'))
## 변수화
## SQLite (Select ~~)
## mySQL decalreCASE
# 그룹으로 묶은 칼럼 생성
SELECT name, subject, salary, CASE
WHEN salary < 3000 THEN 'Low'
WHEN salary < 4000 THEN 'Mid'
ELSE 'High'
END '월급 그룹'
FROM Teacher t중앙값median
# 중앙값 / median() 미사용시
SELECT student_id, age'중앙값'
FROM Student
ORDER BY student_id
LIMIT 1
OFFSET (SELECT COUNT(*)
FROM Student) / 2
# 중앙값 / 변수화 + SELECT median()
SELECT student_id, age FROM Student
WHERE age = (SELECT Median(age) FROM Student)
# 참고
SELECT median(sallary) over (partition by dept_id) FROM mydb.dept_sallary# 에러구문
SELECT student_id, median(age) '중앙값' FROM Student
# studentid는 중앙값이 아닌 첫번째값이 나옴
# median은 select에선 사용할 수 있지만, in에선 사용할 수 없음복잡 구문
# 구매평균이 전체평균보다 큰 고객군의 정보
## JOIN 사용예시
SELECT i.CustomerId, AVG(Total) AS avg_total
FROM invoices AS i
LEFT JOIN customers AS c
ON i.CustomerId = c.CustomerId
GROUP BY i.CustomerId
HAVING AVG(Total) > (SELECT AVG(Total) FROM invoices)
ORDER BY avg_total DESC;
## 서브쿼리 사용예시
SELECT CustomerId
FROM customers
WHERE CustomerId IN
(SELECT CustomerId
FROM invoices AS i
GROUP BY CustomerId
HAVING AVG(Total) > (SELECT AVG(Total) FROM invoices)
);
#### GROUP BY 사용예시 생각해보기
# 고객별 정보 및 타겟칼럼 생성(전체평균보다 큰지 아닌지 여부)
## 분류 지도학습모델에서 활용 가능
SELECT CustomerId, BillingCountry, BillingCity, AVG(Total),
AVG(Total) > (SELECT AVG(Total) FROM invoices) AS Target
FROM invoices i
GROUP BY CustomerId;
# 인보이스 발행날짜가 2011년 이전인 고객의 정보 반환
## 서브쿼리 사용예시
SELECT c.CustomerId
FROM customers AS c
WHERE c.CustomerId IN(
SELECT i.CustomerId
FROM invoices AS i
WHERE i.InvoiceDate < '2011-01-01'
);
## 서브쿼리 미사용예시
SELECT c.CustomerId
FROM customers AS c, invoices AS i
WHERE i.InvoiceDate < '2011-01-01'
## JOIN ON 사용예시
SELECT c.CustomerId
FROM customers AS c
JOIN invoices AS i ON i.CustomerId
WHERE i.InvoiceDate < '2011-01-01'
ENTJ 데이터 분석가 준비중입니다:)