대학교를 졸업하고 취준을 하는중에 평소 관심이 있었던 인공지능에 대해서 요 2주정도 공부해본것을 정리해볼까 합니다.
아직 불완전한 감이 있는 지식을 velog에 쓰는 것을 많이 망설이기도 했습니다.
그러나, 적어놓지 않으면 금방 휘발될것 같기도 하고, velog라는 사이트를 처음 이용해보는 글감으로서 적당하다고도 생각되어 적어봅니다.
이 글은 저처럼 컴퓨터학과를 졸업했고, 인공지능에 대해 약간의 궁금증을 갖고 있으며 적당히 인공지능에 대해 주워들은 것은 많지만 명확히는 모르겠는 사람들이 읽기에 적당하다고 생각합니다.
1. 인공지능이란 무엇인가?
일반적으로 인공지능이란
사람처럼 학습할 수 있는 컴퓨터
를 말한다고 생각한다.
2. 학습이란 무엇인가?
사람은 뇌를 갖고 있다. 이 뇌로 생각을 하고 경험을 통해 학습을 한다.
즉, 학습이란 생각하는 능력 + 경험
을 말하는 것이라고 할 수 있을 것이다.
예를 들어 생각해보자.
사람은 어떻게 고양이 그림을 보고 고양이라고 알 수 있을까?
그것은 뾰족한 귀를 갖고, 눈코입이 있으며, 털을 갖고 있는 생물은 고양이라는 것을 학습했기 때문이다.
즉, 여러번의 경험을 통해 이런 것이 고양이다라는 정보를 갖고 있으며
그 경험을 바탕으로 고양이라는 것이 어떤 특징을 갖고 있는지를 학습했다고 볼 수 있다.
고양이 그림을 보고 "이것은 고양이야" 라고 말하는 과정을 단계별로 살펴보자.
1단계 : 고양이 그림 A를 본다 (뇌에 입력이 들어온다)
2단계 : 생각한다. (뇌가 활성화된다)
3단계 : A는 고양이 그림이라고 결론을 내린다 (결과가 나온다)
4단계 : "A는 고양이야" 라는 결론에 맞다 또는 틀리다는 판정을 받는다 (판정 과정)
5단계 :
- 맞다는 판정을 얻었다 -> A는 고양이라는 정보를 뇌에 반영한다.
- 틀리다는 판정을 얻었다 -> A는 고양이가 아니라는 정보를 뇌에 반영한다.
사람은 이와 같은 과정을 일상속에서 무수히 많이 겪게되면서
나중에는 그 경험을 바탕으로 점점 올바른 결정을 내리게 된다.
그렇다면 인공지능은 어떨까?
당연히 인공지능이라고 해서 다르지 않다.
3. 인공지능의 구조
인공지능의 학습을 알아보기전에 먼저 그 구조를 살펴보자.
사람의 뇌는 세포체, 시냅스, 축색돌기, 수상돌기 등으로 이루어져있다.
인공신경망은 사람의 뇌를 바탕으로 만들어졌기에 위의 4가지와 대응되는 부분들이 존재한다.
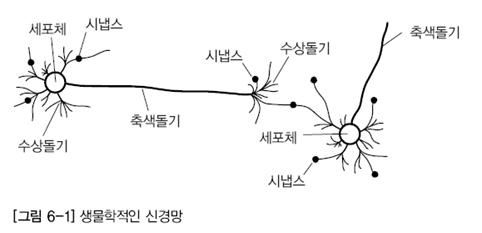
이 그림이 사람의 뇌다.
사람의 학습방법을 이 뇌구조의 동작과 연결지어 생각해보자면 다음과 같다.
1단계 : 고양이 그림 A를 본다 (수상돌기로 입력이 들어온다)
2단계 : 생각한다. (세포체가 활성화된다)
3단계 : A는 고양이 그림이라고 결론을 내린다 (축색돌기로 결과가 나온다)
4단계 : "A는 고양이야" 라는 결론에 맞다 또는 틀리다는 판정을 받는다 (판정 결과)
5단계 :
- 맞다는 판정을 얻었다 -> A는 고양이라는 정보를 뇌에 반영한다. -> 해당 세포체의 시냅스가 강화된다
- 틀리다는 판정을 얻었다 -> A는 고양이가 아니라는 정보를 뇌에 반영한다. -> 해당 세포체의 시냅스가 약화된다
만약 틀리다라는 판정을 받았다면 다음부터 A그림을 볼때 고양이라는 선택지는 별로 떠오르지 않을 것이다.
왜냐면 해당 시냅스가 약해져서 고양이로 가는 생각의 끈이 얇아졌기 때문이다.
이제 인공신경망의 구조를 살펴보자.
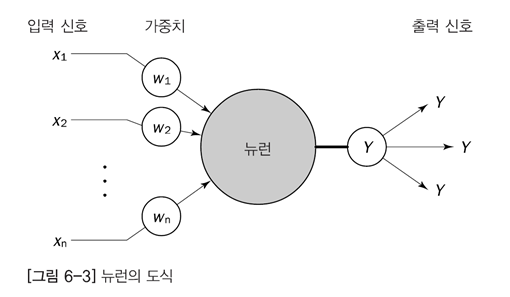
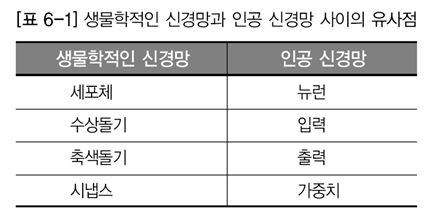
표를 유심히 살펴보고 이해하자.
이해했는가?
다시 위의 예를 생각해보자.
이번에는 인공신경, 즉 컴퓨터가 "오늘 뭐먹지"에 대한 결정을 내릴 것이다.
자, 시냅스는 가중치다. 이것에 주목하면서 살펴보자.
1단계 : 고양이 그림 A를 본다 (x로 입력이 들어온다)
2단계 : 생각한다. (뉴런이 활성화된다)
3단계 : A는 고양이 그림이라고 결론을 내린다 (y로 고양이가 맞다는 결론이 나온다)
4단계 : "A는 고양이야" 라는 결론에 맞다 또는 틀리다는 판정을 받는다 (내 예측결과와 실제 결과가 얼마나 다른지에 대한 오차를 얻는다)
5단계 :
- 맞다는 판정을 얻었다 -> A는 고양이라는 정보를 뇌에 반영한다. -> 오차가 신경망에 반영되어 해당 뉴런의 가중치가 강화된다
- 틀리다는 판정을 얻었다 -> A는 고양이가 아니라는 정보를 뇌에 반영한다. -> 오차가 신경망에 반영되어 해당 뉴런의 가중치가 약화된다
4. 인공신경망의 학습
즉, 인공신경망에서 제일 중요한 개념은 다음의 두가지다.
가중치
오차
인공신경망의 학습이란 한 문장으로 축약하면 다음과 같다.
입력에대해 에측한 결과와 실제결과의 오차를 줄여나가는 식으로 인공신경망의 가중치를 수정해나가는 과정
아주 간단하군!
그런데 세상에는 굉장히 다양한 인공신경망이 존재한다.
이렇게 간단한데 대체 왜??
그 이유 또한 간단하다.
2단계 : 뉴렁이 활성화된다
4단계 : 예측결과와 실제결과가 얼마나 다른지 오차를 얻는다
5단계 : 해당 오차를 신경망에 반영한다.
이 3가지 과정을 구현하는 새롭고 효율적인 방법이 계속 등장하기 때문이다.
또한 입력받는 데이터에 따라서 이 단계를 구현하는 최적의 방법이 다 다르다.
이미지에는 CNN, 간단한 판별에는 MLP 등
그렇다면 이제부터 위의 예시를 바탕으로 신경망을 조금더 자세히 알아보도록 하자.
실제 신경망을 배우게 되면 접하게 되는 용어 위주로 MLP신경망에 대해서 알아보자.
(아래 단계는 일반적인 신경망의 단계와는 다르다. 예시 기반이기 때문이다)
(찾아보면 이것보다 간단한 뉴런 한개 짜리 AND계산만 하는 단일 Percentron 신경망이라는 것도 존재한다)
- MLP = Multi layer perceptron
5. 인공신경망의 학습 (심화)
위의 그림은 아래의 그림과 같은 그림이다.
위의 그림의 뉴런은 아래 그림의 선형결합과 하드리미터, 임계값을 포함하고 있다.
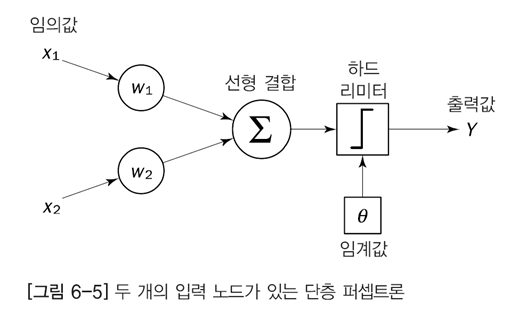
1단계 : 고양이 그림 A를 본다 (x로 입력이 들어온다)
2단계 : 생각한다. (뉴런이 활성화된다)
3단계 : A는 고양이 그림이라고 결론을 내린다 (y로 고양이가 맞다는 결론이 나온다)
4단계 : "A는 고양이야" 라는 결론에 맞다 또는 틀리다는 판정을 받는다 (내 예측결과와 실제 결과가 얼마나 다른지에 대한 오차를 얻는다)
5단계 :
- 맞다는 판정을 얻었다 -> A는 고양이라는 정보를 뇌에 반영한다. -> 오차가 신경망에 반영되어 해당 뉴런의 가중치가 강화된다
- 틀리다는 판정을 얻었다 -> A는 고양이가 아니라는 정보를 뇌에 반영한다. -> 오차가 신경망에 반영되어 해당 뉴런의 가중치가 약화된다
맨처음, 위의 가중치와 임계값은 전부 임의의 값으로 초기화 하고 시작한다
1단계 : 입력값을 받는다
이미지 픽셀단위로 들어오게된다. 고양이 그림이 28x28 픽셀의 그림이라면
28x28=784
총 784개의 입력값이 들어오게 된다. 즉, x의 개수는 784개 w의 개수도 784개가 된다.
2단계 : 뉴런으로 들어간다
뉴런의 첫단계 선형결합 단계를 거친다.
x1 w1 + x2 w2 + ... x784 * w784 = X두번째 단계 활성화 함수를 거친다. 이 활성화 함수가 바로 인공신경망의 종류를 가르는 척도가 되기도 한다. 입력값과 목적에 맞게 활성화함수를 사용하는 것이 중요하다. 여기서는 relu함수를 쓴다고 가정한다.
relu함수는 큰값은 그대로, 일정 값 이하는 0으로 수렴하게 하여 정규화 함수라고도 불린다.
3단계 : 출력값을 정규화한다
출력값과 목표출력값을 비교할 수 있게 출력으로 나온 값을 정규화한다.
이 단계는 2단계에 포함되는 경우가 많다.
4단계 : 오차를 계산한다
cross entropy 함수나 최소제곱법을 이용해서 오차를 구하게 된다.
이 오차를 구하는 함수에도 굉장히 많은 종류가 존재한다. 이 함수를 잘 사용하는 것도 인공지능 개발자의 중요 업무이다.
5단계 : 오차를 반영해 가중치를 수정한다
사실 5단계는 두단계로 나뉘어져 있다.
가중치를 수정하기 때문에 update 단계라고도 불린다.
- 5-1단계 : 오차가 최소가 되는 곳을 구한다.
이때 사용하는 방법은 경사하강법 (Gradient Descent) 로 거의 통일되어있다고 봐도 좋다.
이 함수에 오차를 넣어서 해당 오차가 가장 적어지는 가중치값을 찾아낸다.- 5-2단계 : 가중치값을 수정한다.
이 가중치 값을 수정하는 것을 back propagation 오류 역전파라고 부른다. 뒤에서 부터 신경망의 가중치를 차례대로 수정하기때문에 이런 이름이 붙었다. 이 가중치를 수정해주는 방식에도 학습을 빠르게 하기위한 여러가지 꼼수와 방식과 구조가 존재한다.
6. 마무리 하며
이렇게 인공지능이란
입력과 목표로 하는 결과가 명화한 데이터를 갖고,
인공신경망의 가중치를 수정하면서,
목표를 모르는 입력이 들어왔을때,
올바른 목표값을 출력해주는 컴퓨터를 말한다.
참고로 위의 방식으로 고양이를 인식해내는 인공신경망을 만든다?
불가능하다.
위의것은 학습과정을 설명하기위해서 예시로 적당히 쓴것이다.
입력값으로 고양이와 오랑우탄만 들어올것이라면 가능할지도 모르지만
엄청나게 많은 동물들이 입력으로 들어오고 그중에 고양이 그림만을 고양이라고 판별하라고 하면
절대 불가능하다고 단언할 수 있다.
그렇다면 어떻게 해야 수많은 그림속에서 고양이 그림만을 고양이 그림이라고 판별할 수 있는가?
이 부분에 대해서는 아주 깊숙히 인공지능에 대해 공부해야 알 수 있을 것이라고 짐작해본다.
나중에 또 시간이 나면 더 공부해 봐야지
