화났었어...😡
한 두달 전에 Weights and Biases의 Sweeps을 사용할 일이 있었는데,
다른 블로그 포스팅을 보더라도 다 개판이고 내가 써먹을 수 없었습니다.
블로그를 그때 한 6시간 뒤져본 기억이 있는데, 다 안돼서 화딱지가 나서 생각나는김에 제가 다시 써봤습니다.
독자 대상은 다른 Weight and Biasese 사용법을 알고 있고, Sweeps을 사용해보고 싶은 사람들입니다.(기본 setting은 건너뜁니다.)
다른 포스팅은 코드 빼먹고 올려서 개열받는데,
저는 그게 너무 싫어서 처음부터 끝까지 다 올립니다. 걱정말고 ㄱㄱ
틀릴 수도 있으니 틀렸으면 피드백 바랍니다...ㅎㅎㅎ
가보자고🥳
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import random
is_cuda = torch.cuda.is_available()
device = torch.device('cuda' if is_cuda else 'cpu')
print('Current cuda device is', device)
# Hyperparameters
batch_size = 1000
learning_rate = 0.001
epoch_num = 10
# Load MNIST dataset
train_data = datasets.MNIST(root='./MNIST_data/',
train=True,
download=True,
transform=transforms.ToTensor())
test_data = datasets.MNIST(root='./MNIST_data/',
train=False,
download=True,
transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(
dataset=train_data, batch_size=batch_size, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
dataset=test_data, batch_size=batch_size, shuffle=True
)
기본 세팅을 해줬습니다.
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(
in_channels=1,
out_channels=32,
kernel_size=(3, 3),
stride=(1, 1),
padding="same",
)
self.conv2 = nn.Conv2d(32, 64, 3, 1, padding="same")
self.dropout = nn.Dropout2d(0.25)
self.fc1 = nn.Linear(3136, 1000) # 7 * 7 * 64 = 3136
self.fc2 = nn.Linear(1000, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return F.softmax(x, dim=1)
CNN 기본 모델을 만들어줍니다.
굳이 설명 안하겠습니다. Sweeps를 사용하는데 필요한 부분만 설명하겠습니다.
슬슬 wandb를 import 해줍시다.
import wandb
def train():
config_defaults = {
'learning_rate' : 0.0001
}
wandb.init(config=config_defaults)
classification_model = CNN().to(device)
wandb.watch(classification_model, log='all', log_freq=1)
optimizer = optim.Adam(classification_model.parameters(), lr=wandb.config.learning_rate)
criterion = nn.CrossEntropyLoss()
for epoch in range(epoch_num):
for data, target in train_loader:
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = classification_model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
wandb.log({'loss': loss})
print('Epoch: {} \tLoss: {:.6f}'.format(epoch, loss.item()))학습하는 함수를 만들어줍니다.
config_defaults = {
'learning_rate' : 0.001
}
wandb.init(config=config_defaults)wandb.init()을 통해 wandb를 초기화해줍니다.
처음 다른 블로그 보고 개열받았던건 이게 뭔지 설명을 잘 안해주더라고요.
아니 근데 config_defaults로 파라미터를 전달해줘도, 이거는 안써요.
걍 hyperparameter가 뭐가 들어있는지만 알려주는거 같습니다.
여기서는 그냥 "내가 넘겨줄 hyperparameter는 learning_rate이야~" 가 되겠죠?
암튼 train함수에 맨 위에 wandb.init()을 넣어줍니다.
classification_model = CNN().to(device)
optimizer = optim.Adam(classification_model.parameters(), lr=wandb.config.learning_rate)
criterion = nn.CrossEntropyLoss()할 때마다 새로운 모델을 생성해야겠죠?
(안하면 원래 학습된거에다가 또 하니까)
저는 learning_rate을 바꿔줬으니까, optimizer Adam의 lr을 건드려줘야 합니다.
wandb.config 파일에 자신이 정한 hyperparameter를 불러오면 됩니다. 굳?
wandb.watch(classification_model, log='all', log_freq=1)wandb.watch()는 생성한 model의 gradient, parameter를 기록해줍니다.
log = 'all'은 모든 것을 기록하겠다는 뜻이고, log_freq는 몇 epoch마다 기록할지를 정해줍니다.
나중엔 이렇게 볼 수 있습니다.
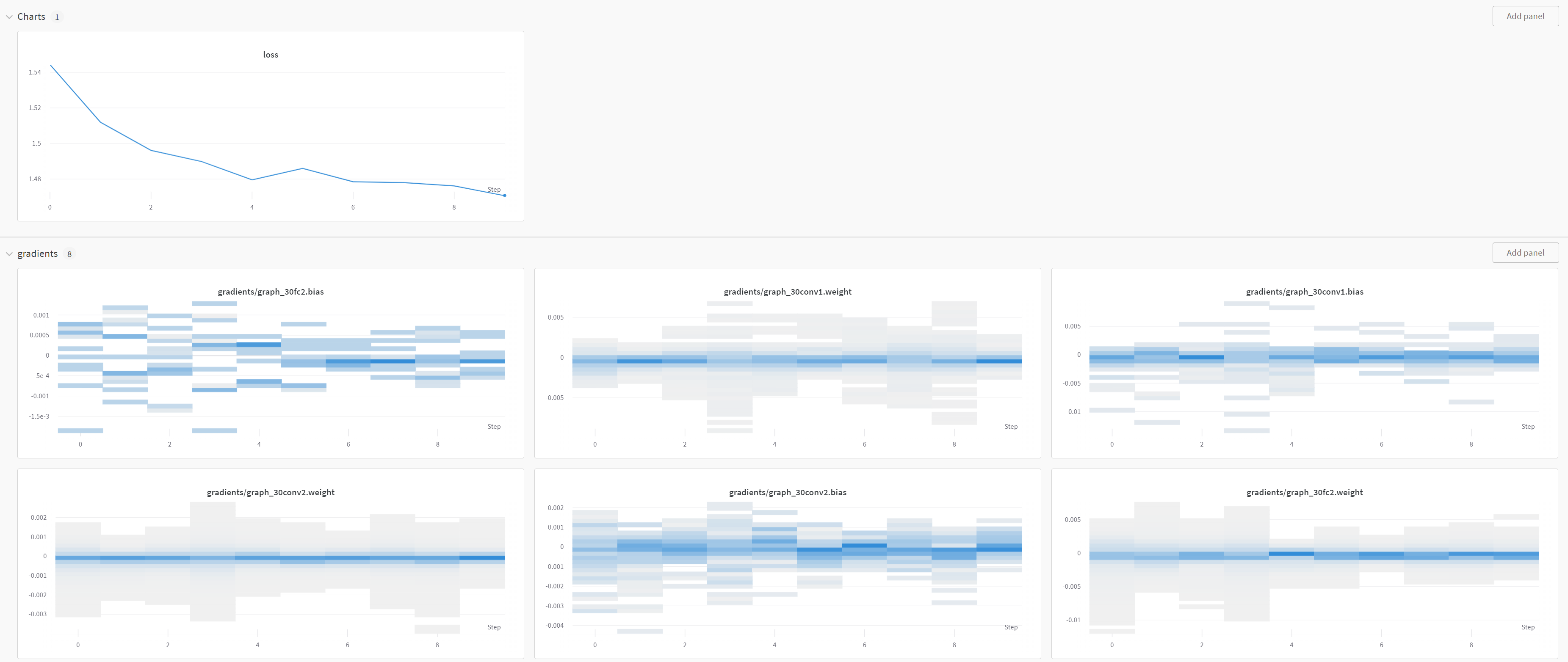
wandb.log({'loss': loss})wandb.log()를 통해 loss를 기록해줍니다.
자 이제 어떤 hyperparameter를 바꿔줄지 정해줍니다.
근데 사실 default로 learning_rate만 바꿔줬으니까, 그냥 learning_rate만 바꿔줘야 합니다.
sweep_config = {
'method': 'grid',
'parameters': {
'learning_rate': {
'values': [0.001, 0.01, 0.1]
}
}
}저는 이렇게 할게요.
이렇게 넘겨주면 learning_rate을 알아서 바꿔주면서 학습을 시켜줍니다.
import wandb
sweep_id = wandb.sweep(sweep_config, project="sweep_test", entity="daehwa")project에는 자신이 원하는 이름을 넣어주면 됩니다.
entity는 자신의 wandb 계정 이름을 넣어주면 됩니다.
wandb.agent(sweep_id, function=train)이렇게 만들어진 sweep_id를 wandb.agent()에 넣어주면 됩니다.
function에는 어떤 작업을 hyperparameter를 바꿔가면서 할지를 넣어주면 됩니다.
끝입니다 돌려볼까요?
결과💜
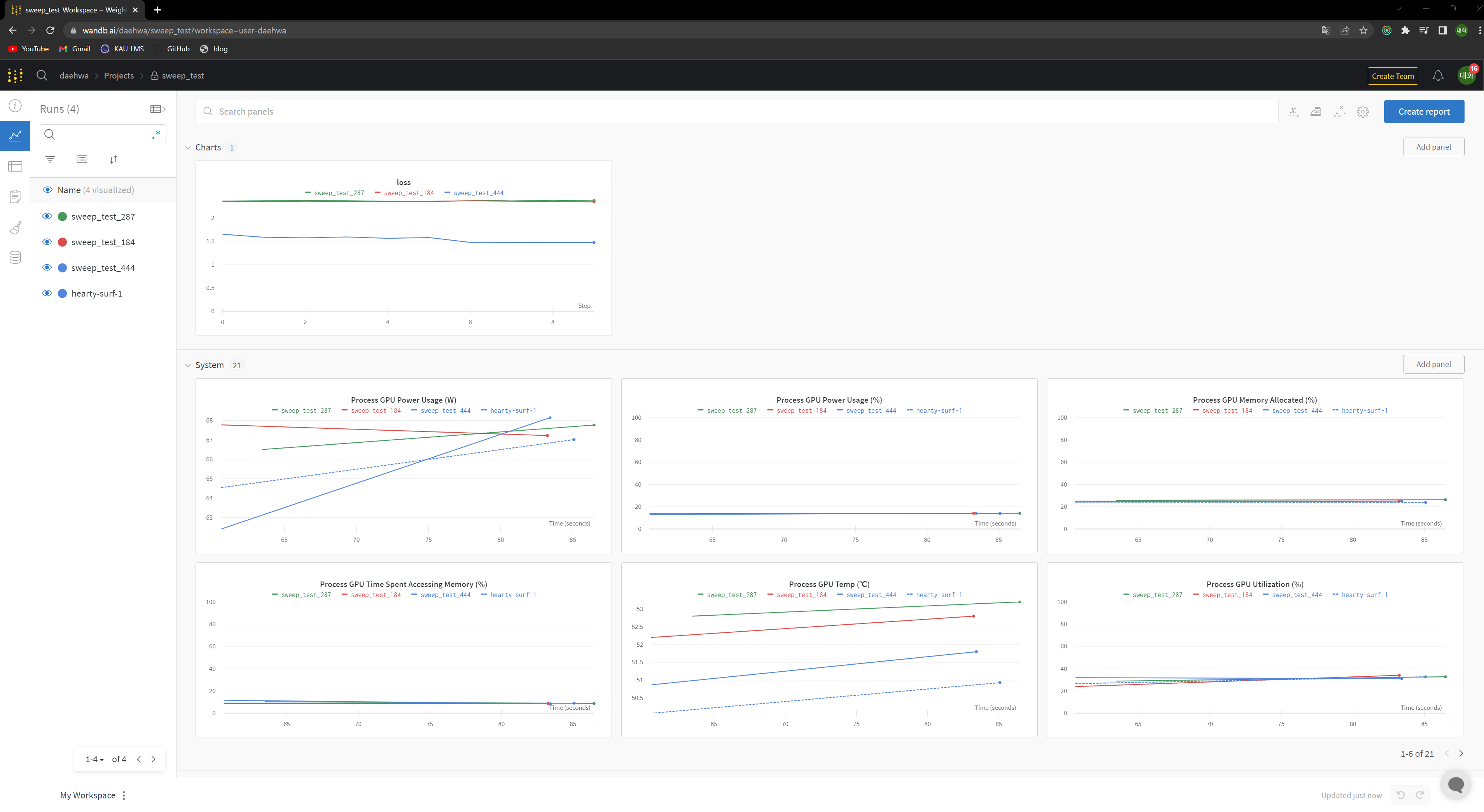
잘됩니다!
