👉 1. 프로젝트 동기 및 선정
프로젝트 주제 선정을 위해 팀원들이 각자 자기 아이디어를 정리하여 발표하는 시간을 가졌다.
Key point를 이용한 모션 인식, 유치원 내 폭력 행동 감지, 외부인 침입 탐지, 활주로 내 이상 물체 감지 등 안전과 이상 행동 or 객체와 관련된 주제들이 제출되었다. (당시 사건 사고가 기사에 많았음)
팀원들과 상의한 결과, 최종으로 '활주로 내 이상 물체 감지' 주제가 선정되었다.
활주로 내 사고를 일으키는 객체를 이상 객체로 분류하여 탐지하는 Task이다.
👉 2. 사용 기법 및 주요 개념
Computer Vison - Object Detection
본 프로젝트의 Task는 활주로 내에서 이상 객체로 분류된 객체의 위치를 Localization하고, 그 객체가 어떤 카테고리에 속하는지 판별하는 Classification이 요구된다.
Image Classification로 접근할 수 있지만, 한계가 있다. Real-Time으로 영상 프레임 내 이상 객체를 판별해야 하는 Task이므로 Computer Vision의 Object Detection를 채택하였다.
MMDetection - One-Stage Model
MMDetection은 중국 칭화 대학의 주도로 만들어진 Computer Vision Open Source Project인 OpenMMLab에서 개발한 Pytorch 기반의 Object Detection과 관련된 Algorithm 들을 구현해 놓은 Object Detection Open Source이다.
Object Detection의 전체 Pipeline을 모듈화하여 Config 기반으로 이루어진 것이 큰 특징이다.
Object Detection을 사용하기 위해서 MMDetection를 사용하기로 하였다.
Object detection을 위한 pre-trained Model을 가져와 학습 및 추론하기 유용하다는 팀원들의 의견 때문이다.
MMDetection의 model zoo를보면 다양한 목적(Object Detection, Instance Segmentation, Keypoint Detection등)을 위한 model들이 구현되어 있음을 알 수 있다.
그중 우리는 Object Detection을 위한 4가지 모델을 선정하고, Demo로 학습을 진행해 결과를 비교 분석하는 시간을 가졌다.
One-Stage
- SSD, Deformable DETR
Two-Stage
- Faster RCNN(ResneXt-101-FPN), Cascade RCNN(Resnet-50-FPN)
4개의 모델 모두 훌륭한 모델이지만, FPS와 box AP를 비교 분석해봤을 때, FPS와 box AP 모두 준수한 결과를 보인 Deformable DETR로 모델을 결정하였다.
SSD 같은 경우, 30.7 FPS로 높은 Inference Speed를 보이지만,
29.5 box AP의 다소 아쉬운 정확도를 가진다.Faster RCNN 같은 경우, 43.7 box AP로 높은 정확도를 가지지만,
10.9 FPS로 실시간으로는 아쉬운 FPS를 보여준다.
Deformable DETR은 Object Detection 분야에 Transformer 개념을 도입한 DETR 기반 모델이다. DETR 기반 모델이 Object Detection 분야에서 널리 사용되고 있다는 장점이 있다. 그만큼 검증이 되고, fine-tune 하기에도 복잡한 모델보다 수월할 것이라는 의견과 판단으로 프로젝트 Task에 적합하다고 생각했다.
특히, DETR의 큰 단점 2개인 작은 물체에 대한 성능이 낮다는 점, Transformer 특성상 모델이 최적으로 수렴하기에 훈련 시간이 상당히 많이 요구되는 점을 보완한 모델이라서 프로젝트 Task에 적합하다고 판단했다.
Model 배포
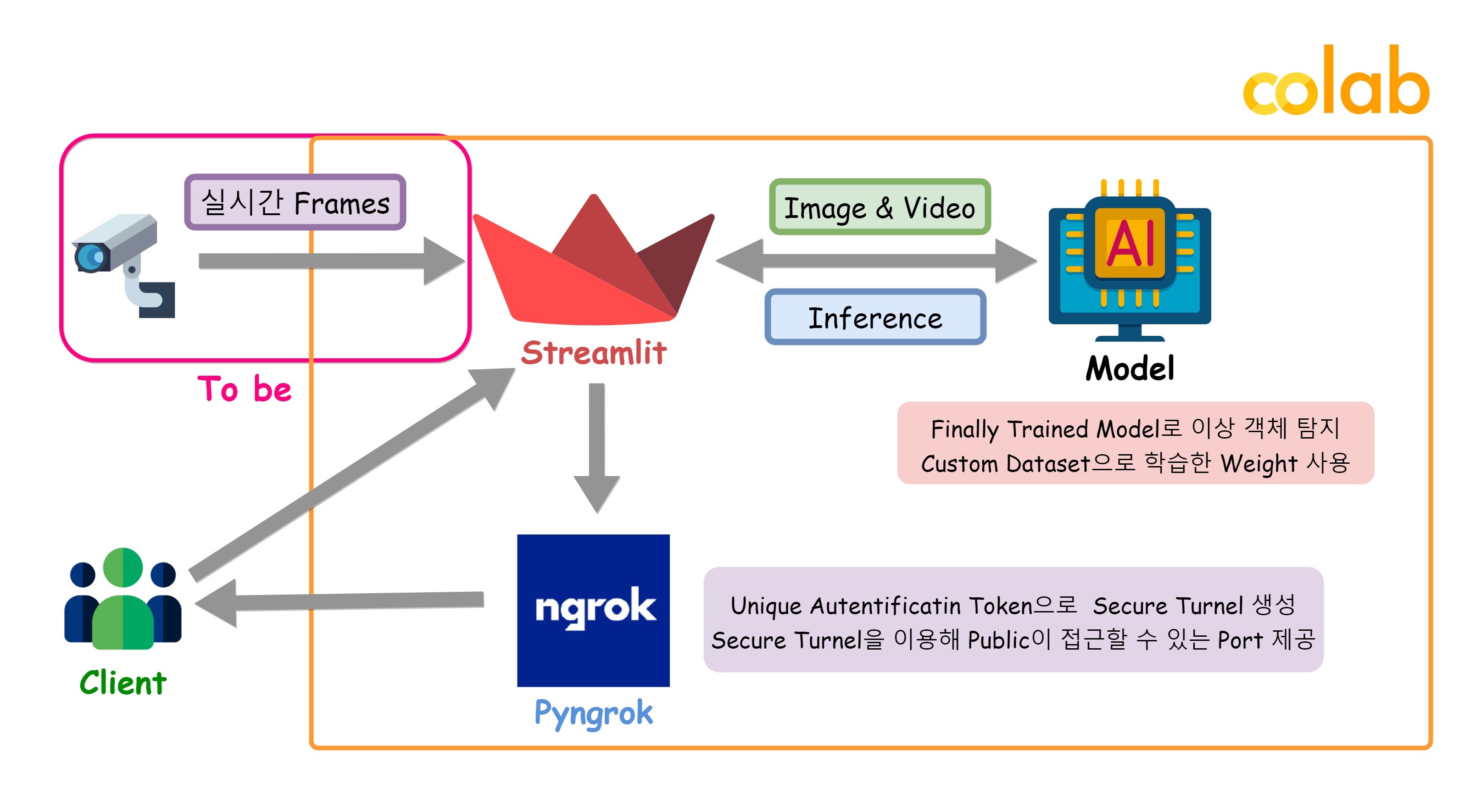
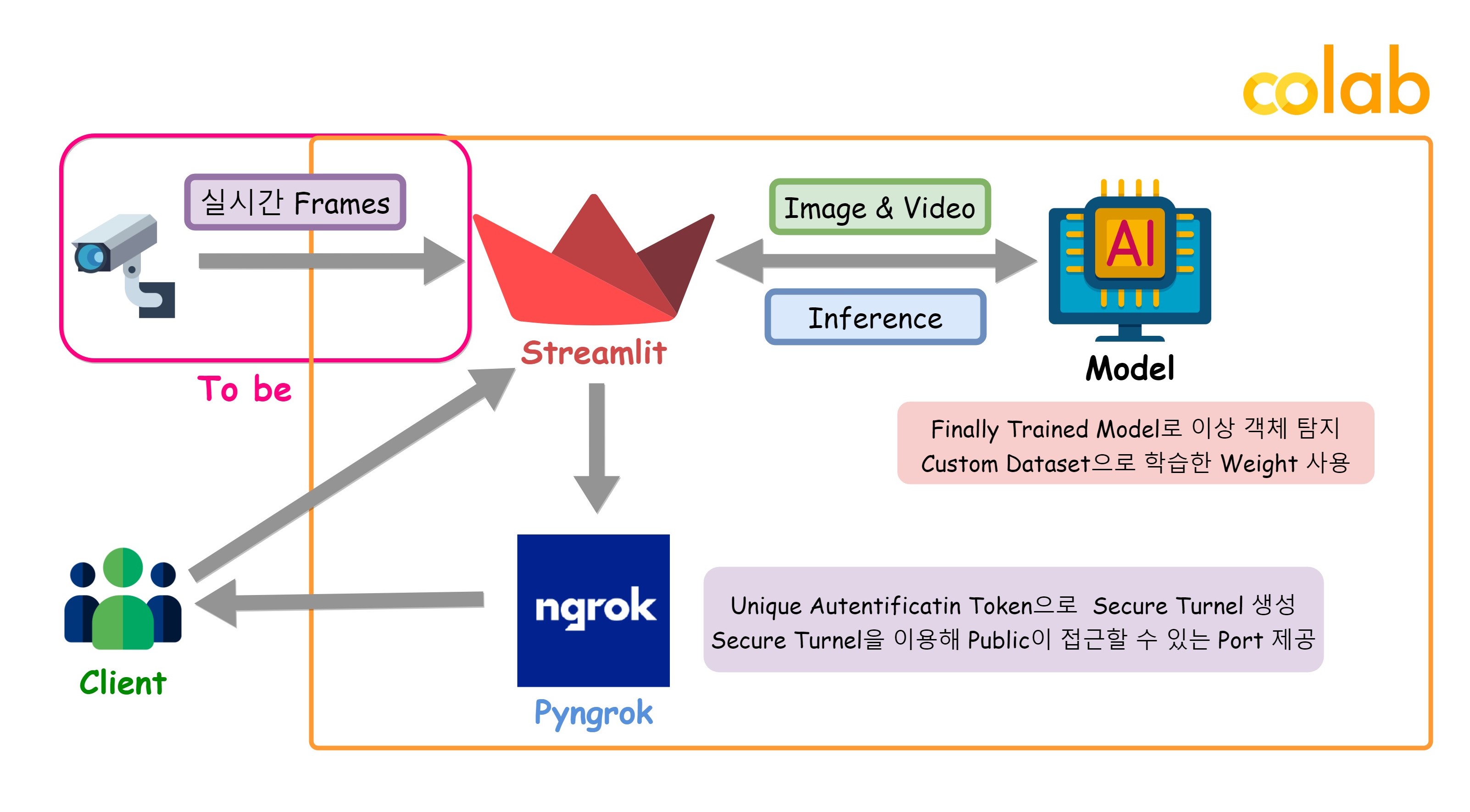
궁극적인 시나리오는 하드웨어로 모델을 배포하여 실시간으로 탐지하는 서비스를 제공하는 것이었으나, 하드웨어적인 한계로 인해서 Image와 Video를 Inference를 하고, 그에 관한 결과를 반환하는 서비스를 구상하였다.
이를 위해, Colab에서 Pyngrok과 Streamlit을 활용해 Web Application을 구현했다.
👉 3. 전체 프로젝트 구조 및 환경
구조
환경 및 사양
GPU
NVIDIA Tesla P100 16GB * 1
CUDA runtime version : 11.1 / CUDA driver version : 11.2
CUDNN version : 8302
NVIDIA driver version : 460.32.03
Deep Learning
Back-end : Python 3.7.14
Deep Learning Framework : Pytorch 1.11.0+cu113
Object Detection Open Source Libary : MMDetection 2.25.1 / MMCV 1.6.1
Inference (Server)
O.S : Ubuntu 18.04.5 LT (Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic)
Web Server : Steamlit, Pyngrok
ETC
SCM : Github, Wandb
Cloud : Google Colaboratory
