
📝5회차 회고록ㅣBEYOND SW캠프
🖥️ 5회차 학습 (25.10.20 ~ 25.10.24)
첫 번째 미니 프로젝트가 어느덧 마무리되고 다음 단계를 위한 한 주가 시작됐다. 주말 간 그동안 못자둔 잠을 푹 자고 돌아오니 컨디션이 나쁘지 않았다. 이번 주 과정은 아래와 같다.
Chap01. 개요 및 개발환경 구축
Chap02. 변수
Chap03. 연산자
Chap04. 메소드와 API
Chap05. 제어문
Chap06. 배열
Chap07. 클래스와 객체
Chap08. 상속
보다시피 기본적인 내용부터, 상속까지 수업을 이어갔고, 다음 주부터는 난이도가 급상승한다. 하루로는 도저히 안될 것 같은 내용들을 날마다 다루고 넘어갈 예정이다. 이를 대비하여 이번주에 예습을 충분히 했어야 했지만... 불가피한 일정들로 충분한 예습을 하기에 빠듯했다. 다 핑계고, 준비 됐든 안됐든 부딪혀야 하니 주어진 상황에서 최선을 다해야 하는 것은 변함없다. 오늘도 어김없이 KNPT로 회고 작성하겠다.
👍 KEEP
- Java 수업 리뷰
Java를 대학교 2학년 객체지향언어 강의 이후 프리코스를 통해 정말 오랜만에 들었었는데, 솔직히 깔끔하게 이해하기보단 다 아는 내용이라 치부하고 제대로 안들었었다. 하지만 이번 강의를 통해 강사 님과 천천히 하나하나 짚어가며 공부하니 예전에 깔 끔하게 이해가 안되었던 부분들과 프리코스 때 이해가 잘 안됐지만 지나간 부분들도 잘 이해할 수 있어 서 좋았다.
✏️ NEW
0. Tips.
0.1 IntelliJ 디버깅
IntelliJ 디버깅에 대한 방법을 배웠다.
- 좌측 원하는 줄 인덱스를 클릭하여 중단점을 생성한다.
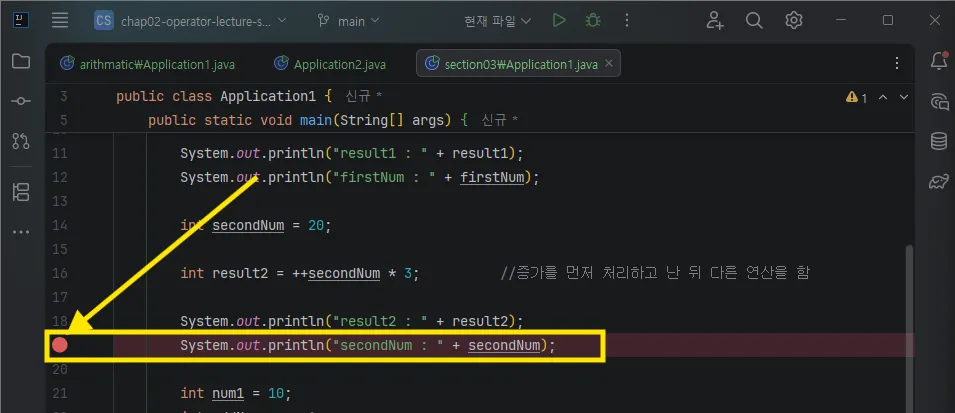
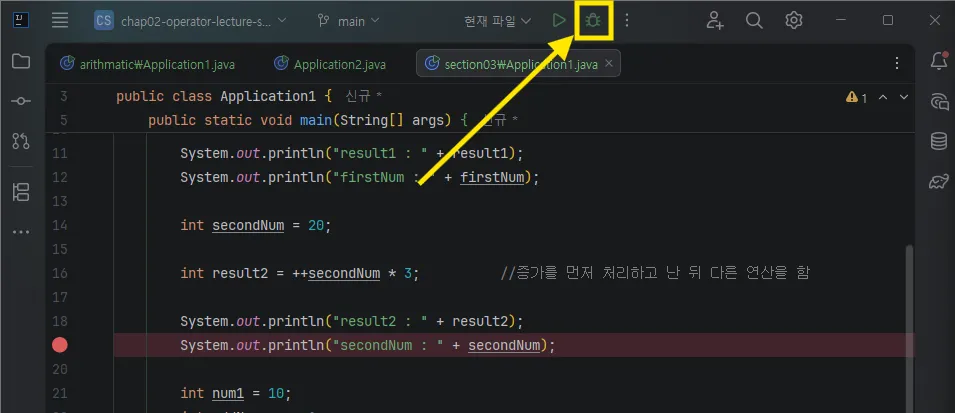
- 상단 벌레를 클린한다.
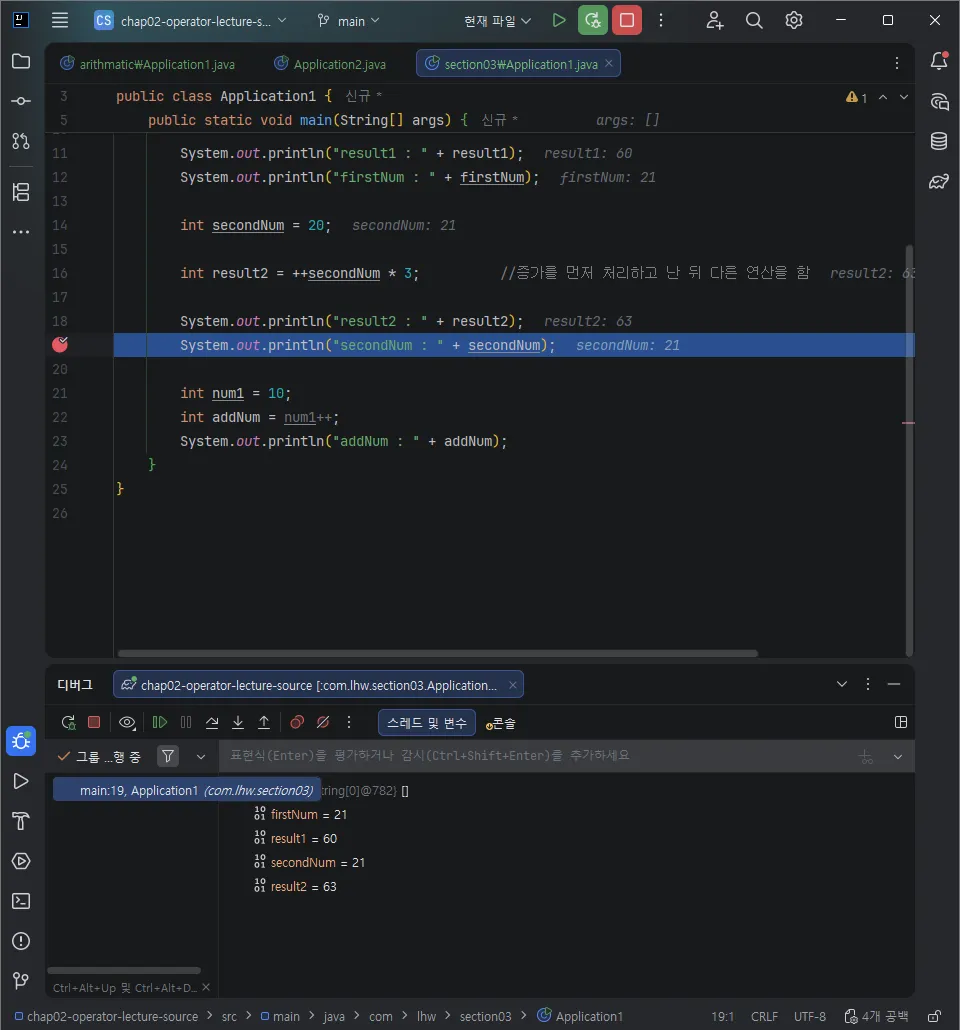
- 중단된 화면이다.
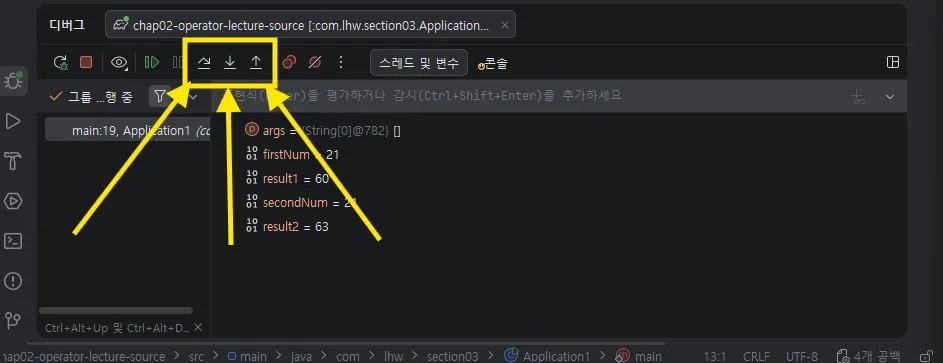
- 화살표 기준 각각 한 줄 넘기기, 상세 정보 보기, 위로 돌아가기 이다.
- 디버깅을 완료 했다면 위 버튼을 눌러 전체 실행을 돌린다.
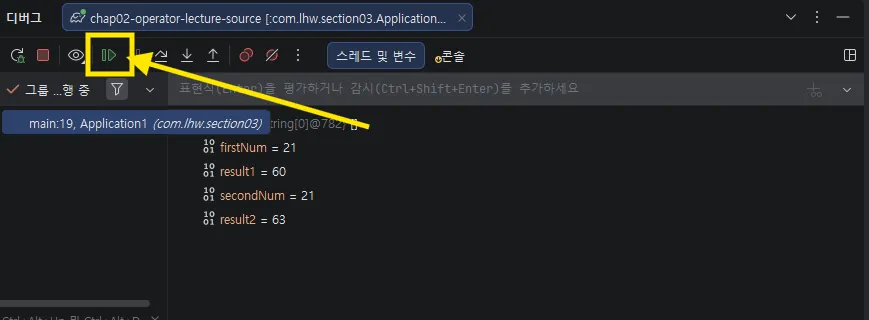
- 중단 시킬 수도 있다.
0.2 Build 파일의 쓰임새
source 파일이 아닌 build 파일에 있는 내용은 변경되지 않는다. 컴파일된 파일이기 때문이다.
이 파일은 배포할 때 쓰인다. source를 사용하지 않고 build를 사용하는 이유는 정해진 파일만 배포 작업에 쓰여야 하기 때문이다.
0.3 Switch
새로운 형태의 switch 문이라고 한다.
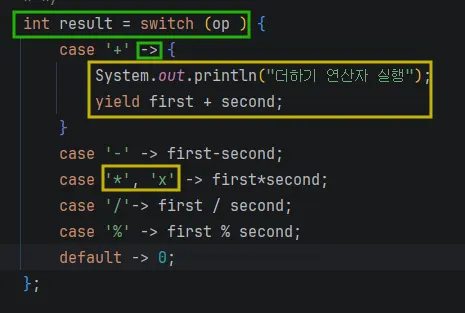
- switch문의 초기화
→로 case 표현{ 지역 설정 가능 }- case에
“,”로 입력 가능
1. 변수
1.1 형변환
형변환은 리터럴 타입의 변화가 일어나는 것.
- 자동형변환: 컴파일러가 리터럴의 타입 변환을 해주는 것(데이터 손실없을 경우)
작은 자료형 → 큰 자료형: 방향으로 변환이 이루어짐
- 강제 형변환: 데이터 손실 가능성이 있는 자료형 변경을 강제로 실행한다.
큰 자료형 → 작은 자료형: 작은 자료형이 담을 수 없는 정보에 대한 값 손실 발생 가능
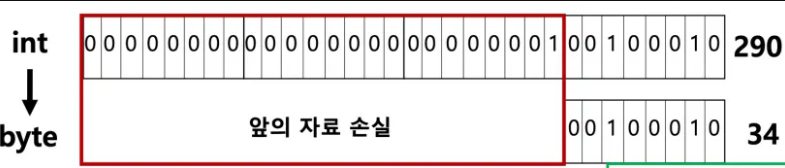
자동형변환 & 강제 형변환 시 주의사항
- 다른 타입끼리의 계산
- 연산 전체 결과를 강제 형변환! (int) (inum+lnum)
- 둘 중 하나만 형변환하여 타입을 맞춤 inum + (int) lnum;
- 결과를 연산의 결과에 맞춤 long result = inum+lnum;
- 의도한 데이터 손실 → 소숫점 제외하고 출력
2. 연산자
2.1 우선순위표
연산자 우선순위표이다. 사실 자주 보는 표이긴 하지만, 어떤 종류가 있고 어느 게 우선순위가 높은지는 기억하고 있지 않기 때문에 자주 들여다 보자.
2.2 논리 연산자와 우선순위
AND연산과OR연산의 특징
(논리식) && (논리식): 앞 결과가False이면 뒤를 실행하지 않는다.
(논리식) || (논리식): 앞 결과가True이면 뒤를 실행하지 않는다.
2.3 삼항연산자
(조건식)?(참일 때 반환):(거짓일 때 반환)
result = A ? B : C;
이와같이 result에 값을 반환할 수도 있다.
A 가 참일 경우 result = B
A 가 거짓인 경우 result = C3. 메소드
3.1 접근제어자
접근 제어자 는 메소드에 접근할 수 있는 범위를 정해준다.
- public : 어디서나 접근 가능하다.
- protected : 상속관계이거나 같은 패키지에서 접근 가능하다.
- default(생략가능) : 같은 패키지에서 접근 가능하다.
- private : 같은 클래스 내부에서만 접근 가능g하다.
3.2 메소드 호출
3.2.1 Static 메소드 호출
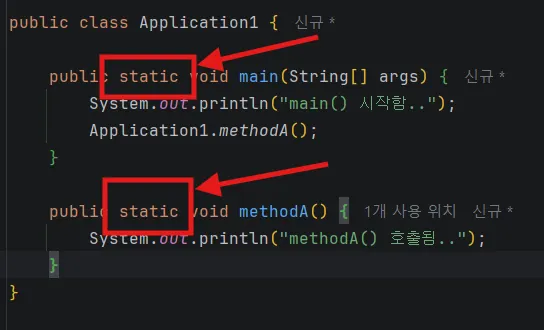 stack, heap, static 중 static 공간에 저장한 메소드를 호출한다. static 공간의 생성 시점은 프로그램이 최초 실행될 때 함께 실행되어, 프로그램의 실행과 동시에 자원을 점유하고, 프로그램이 종료될 때 소멸한다.
stack, heap, static 중 static 공간에 저장한 메소드를 호출한다. static 공간의 생성 시점은 프로그램이 최초 실행될 때 함께 실행되어, 프로그램의 실행과 동시에 자원을 점유하고, 프로그램이 종료될 때 소멸한다.
같은 클래스의 내의 static 메소드를 사용할 때는 클래스명 생략이 가능하다.
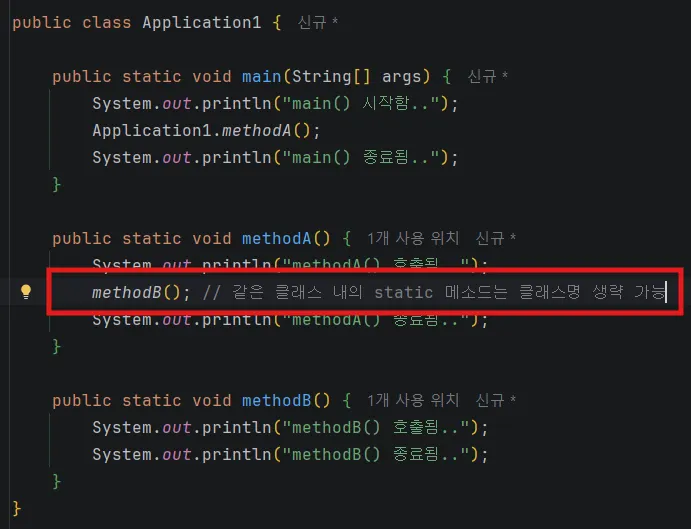
3.2.2 클래스 간 메소드 호출 시
클래스 간 메소드를 호출한다면 다시 반환을 받아야 한다.
전달 인자와 매개변수 또한 클래스간 이동한다.
3.3 패키지
클래스나 인터페이스의 소스파일(.java)의 최상단에 선언되어야 한다.
클래스 명명규칙과 다르게 소문자로만 작성하는 것을 원칙으로 한다.
패키지 명을 지정하지 않으면 자동적으로 이름 없는 패키지에 속하게 된다.
패키지가 없다면 어느 폴더로 어디로 찾아가라는 명시가 없기 때문에 해당 파일을 찾아갈 수 없게 된다.
→ “경로” 역할이자 “클래스 이름” 역할을 하는 것
- 예시
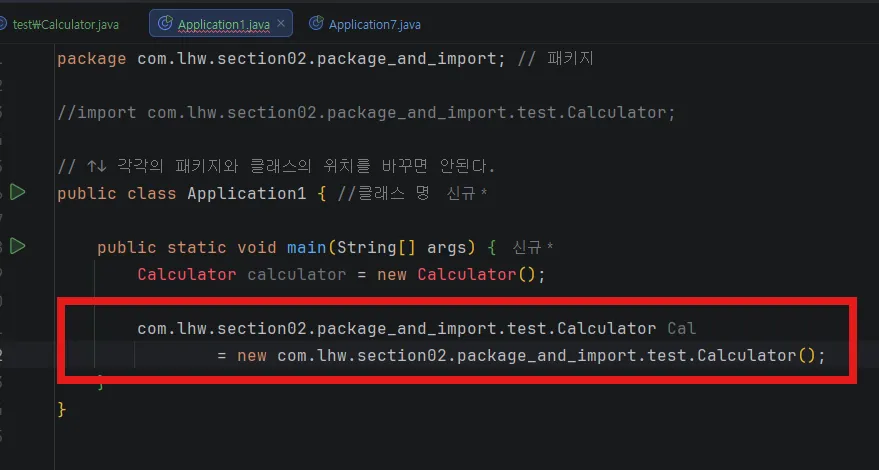
패키지를 import없이 적용하고 싶다면 다음과 같이 풀 패키지명을 입력시키면 된다.
3.4 임포트
3.4.1 풀 클래스 명
서로 다른 패키지에 존재하는 클래스를 사용하는 경우 패키지명을 포함한 <전체 클래스 이름>을 사용해야 한다. 하지만 매번 다른 클래스의 패키지명 까지 기술하기는 번거롭다. 그래서 패키지 명을 생략하고 사용할 수 있도록 한 구문이 import 구문이다.
import문 이 없으면 위 사진처럼 풀 클래스 명을 작성해야 한다.
3.4.2 import 생략가능한 패키지
Java에는 import문을 생략해도 되는 패키지가 있다. java.lang 의같은 기본적인 패키지는 컴파일러가 추가해주는 몇 가지의 패키지가 존재한다.
아래와 같이 풀 패키지 명을 표기할 수도 있다.

3.4.3 Non-Static & Static Class의 메소드 호출
-
방법 1

static호출의 경우 클래스명을 호출해서 가져와야 한다. 객체로 가져온다면stack영역에 존재하기 때문에 자원이 낭비된다. -
방법 2
import static com.{경로..}.Calculator.*스태틱 영역의 메소드를 가져올 때 선언할 수 있는 두 번째 방법이다. 이런식으로 선언 후 필드에서 클래스명 없이 메소드명을 자유롭게 사용할 수 있다.
3.4.4 임포트 클래스 이름 중복 불가

임포트 클래스 이름이 중복되면 사용할 수 없다. 따라서 동일한 이름의 클래스 이름이 존재한다면 풀네임을 가져와 사용해야 한다.
4. API
java.lang.Math
min,max,random등 다양한 수학 메소드를 사용할 수 있다.
-
random()사용 시 원하는 범위를 구할 때 꿀팁

-
util.Random은 조금 다르다.(int)필요 없음.

-
난수 구하는 공식
구하려는 수의 (최대값) - (최소값) + 1 = (곱할 값) ( ... Math.random() * (곱할 값)) + (발생할 난수 개수);
4.1 Scanner
Scanner또한Java.lang.util패키지에 포함된 클래스이며, 사용 시 객체를 선언하여 사용한다.
-
주의사항 1
Scanner클래스의 메소드next()이후nextLine()을 사용할 때 생기는 문제가 있다.next()는 enter키가 포함되어 있지 않기 때문에next가 버커에 값을 올리고 사용 후 바로 사라지지 않는데, 다음 오는nextLine()이 이전에 업데이트 해놓은 버커 값을 그대로 가져오는 경우가 생긴다. -
주의사항 2
메도스next()이후nextInt()등 파싱을 해주지 않는 경우의 메소드를 이어서 사용할 때, 공백이 들어가고 자료형이 맞지 않을 경우 예외가 발생한다.
Scanner sc = new Scanner(System.in);
String inputS = sc.next(); --> 안녕 하세요 (공백 전까지 읽음)
Int inputI = sc.nextInt(); --> "하세요" 넘어옴 -> INT 라 에러 발생5. 배열
5.1 배열의 정의
배열의 정의 형식은 다음과 같다.
int arr[] = new int[5];int : 배열 타입
arr[] : 배열 레퍼런스 변수
new : 힙 메모리 영역에 할당
int : 타입
[5] : 배열의 길이

arr에는 주소값이 들어간다. arr을 프린트해보면 아래와 같이 나온다.
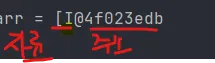
-
[I: Integer형 array가 -
@4f023edb: 해당 주소에 저장되어 있다. -
아래 사진처럼 arr의 이름은 stack에, 주소값은 Heap 영역에 저장된다.
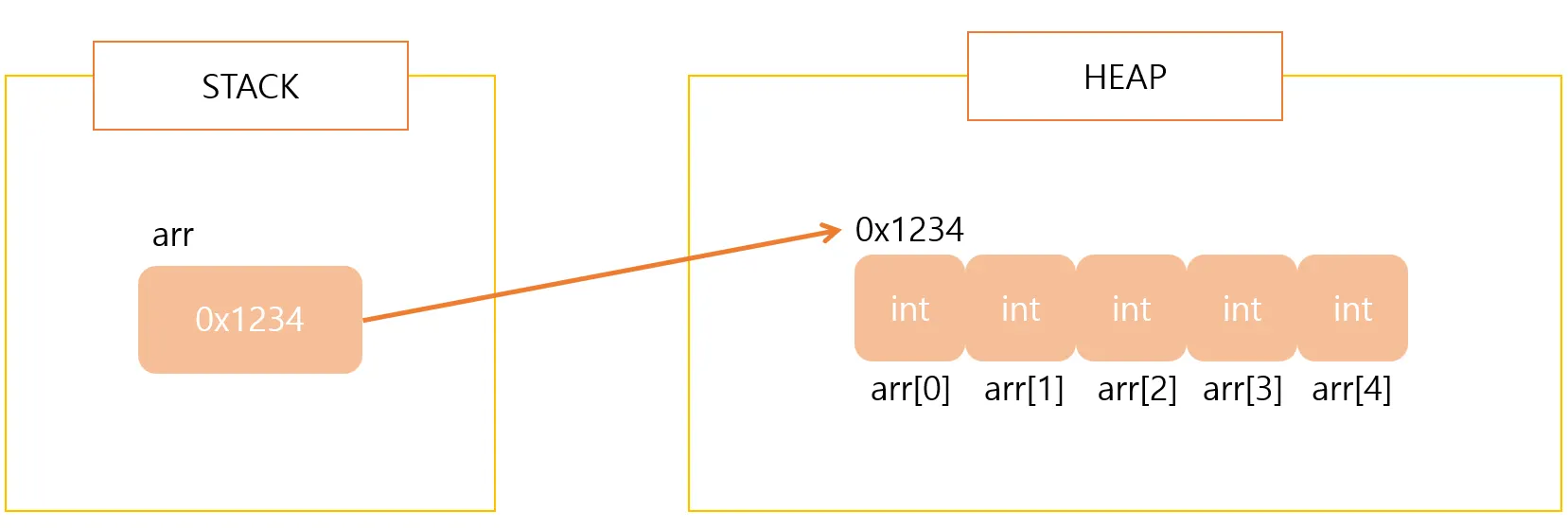
5.1.1 배열 할당
/*배열 선언: Stack에 배열 주소 보관*/
int [] iarr;
double [] darr;
iarr = new int[5];
darr = new double[5];먼저 배열을 선언하고 레퍼런스 변수(iarr)에 배열을 할당할 수 있다.
반환된 주소는 레퍼런스 주소에 저장된다.
↳ 이를 참조 자료형이라 한다.
- Heap 영역은 이름으로 접근하지 않고 주소값을 통해 접근한다.
- Stack 영역에 주소값을 레퍼런스 변수에 저장하여 필요할 때 주소값을 통해 Heap에 저장된 배열의 정보를 찾아볼 수 있다.
5.1.2 배열 사용 시 필요 정보
- 레퍼런스 변수에 대한 이해(stack-heap-주소값이동)
.hashCode(): 주소값을 10진수로 변환하여 반환ref변수.length: 배열의 길이 확인- 배열 수정은 안됨 → 새로 new 할당해서 덮어쓰기 밖에 안된다.
5.1.3 ⭐⭐⭐초기화 : null 로 초기화
null로 초기화하면 주소값이 사라지기 때문에 더 이상 접근할 수 없게 된다.
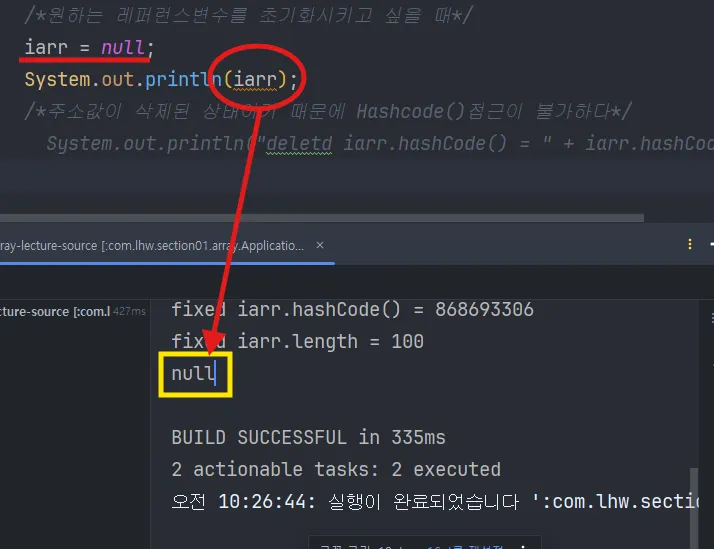
Null 이라는 값에다가 참조 연산자 . 사용 시 java.lang.NullPointerException 발생
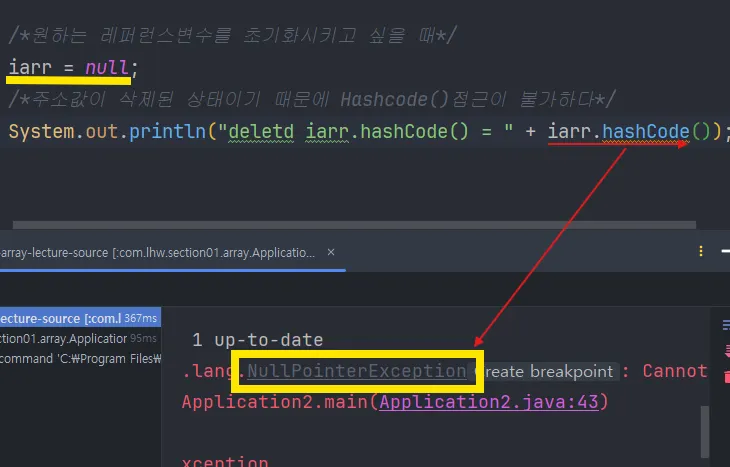
.hashCode(),.length,.max()등 모두 에러가 발생한다.
5.1.4 배열 초기화 전 기본값
Heap 영역에 할당 될 경우 자료형에 따른 초기값이 설정되어 할당된다.
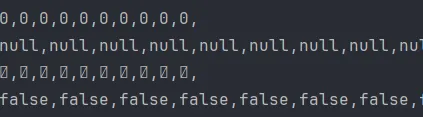
- 정수 :
0 - 문자 :
\0(없음) - 참조(String등) :
null
5.2 다차원 배열
다차원 배열의 정의 형식은 다음과 같다.
int arr[][] = new int[3][4];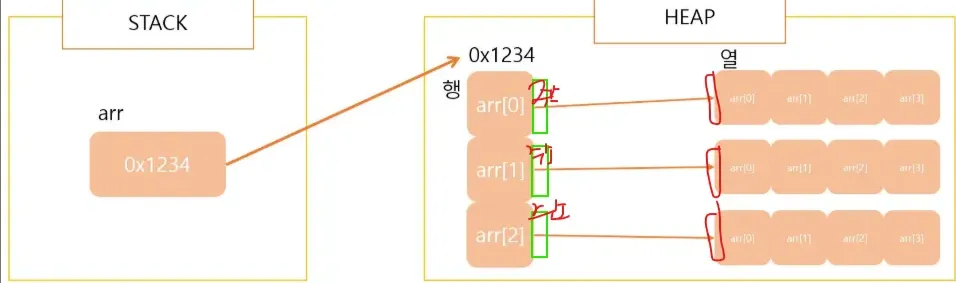
2중 배열의 행에는 그림과 같이 열들의 주소값이 들어있다.
5.2.1 정변 배열과 가변 배열
- "열" 에 포함되는 이너 배열의 길이가 모두 동일한 경우.
- "열" 에 포함되는 이너 배열의 길이가 서로 다른 경우
[가변배열]
가변 배열의 선언은 아래와 같다.
/*가변 배열의 경우 인덱스별 1차원 배열을 따로 할당해야 한다.*/
int [][] iarr;
iarr = new int[3][]; ⭕ 가변 배열
iarr = new int [][]; ❌ 크기 지정하지 않으면 생성되지 않는다.
iarr = new int[][3]; ❌ 주소관리배열을 비워놔도 생성 안된다.- 가변 배열을 첫 선언한 상태에서, 레퍼런스 변수
iarr에는 주소값이 존재한다.System.out.println(iarr); → Stack 레퍼런스 배열 참조 주소값 System.out.println(iarr[i]); → Heap 1차원 배열 참조 주소값: 현재null System.out.println(iarr[0][0]); → Null을 참조하여 오류발생- 하지만 아직
iarr[0]은 선언하지 않았으므로,null이 들어있고 이null을 참조하는iarr[0][0]은NullPointException이 발생하게 된다.
- 하지만 아직
- 위 가변 배열을 각 행에 따라 다른 크기로 선언해보자.
iarr[0] = new int[3]; iarr[1] = new int[2]; iarr[2] = new int[5];- 위 처럼 선언 가능하고 실행 결과는 아래와 같다.
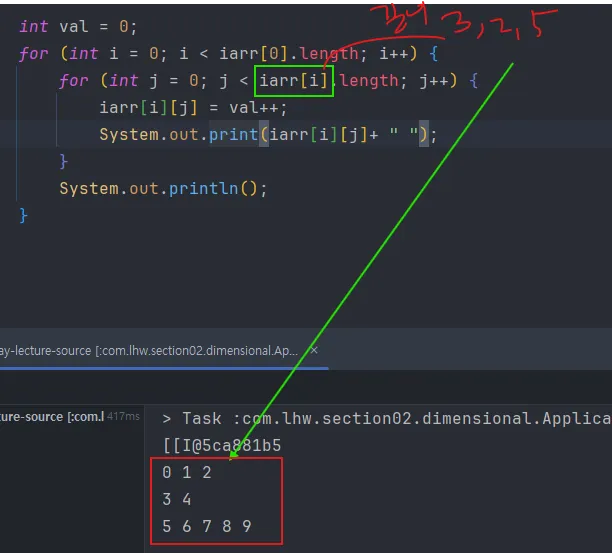
- 위 처럼 선언 가능하고 실행 결과는 아래와 같다.
5.3 배열 복사
배열 복사에는 깊은 복사과 얕은 복사가 있다.
5.3.1 얕은 복사
얕은 복사는 Stack 영역에서 배열의 주소값만 복사하는 원본 공유 개념의 복사이다.
int [] origin = {1,2,3,4,5};
int [] copy = origin; //주소값만 복사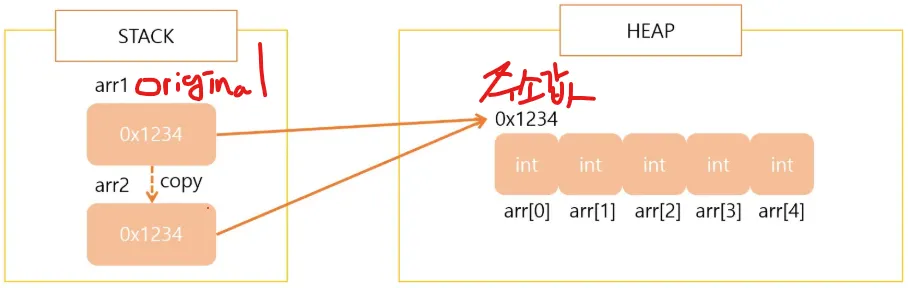
동일한 주소값이므로, .hashCode()결과가 일치한다.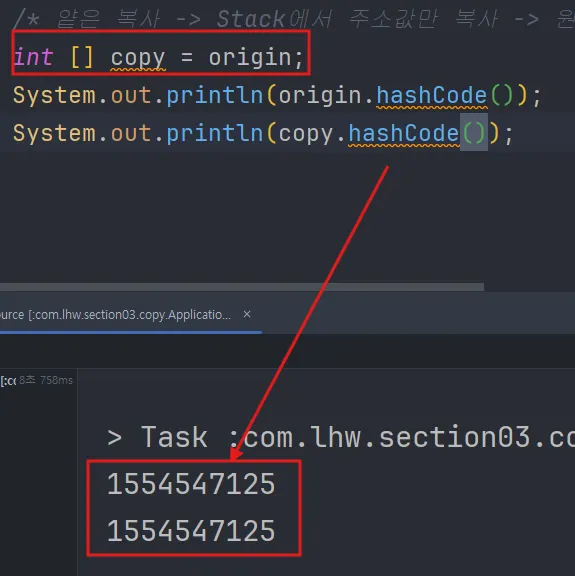
얕은 복사 수정
얕은 복사 배열의 내용을 수정하면 원본도 함께 바뀐다.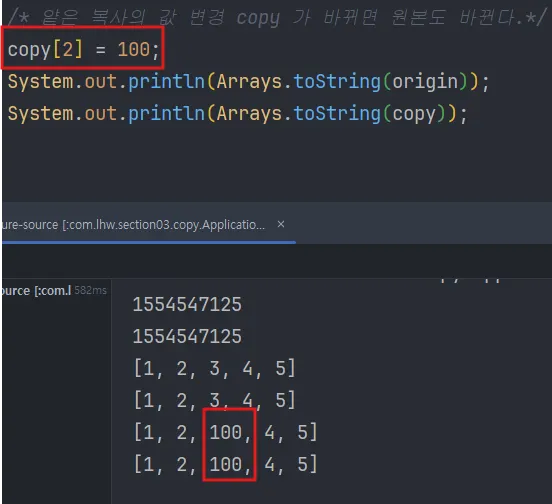
배열 메소드의 매개변수와 Return
- 메소드 매개변수로 들어간 배열은 주소값이 넘어가는 얕은 복사이다.
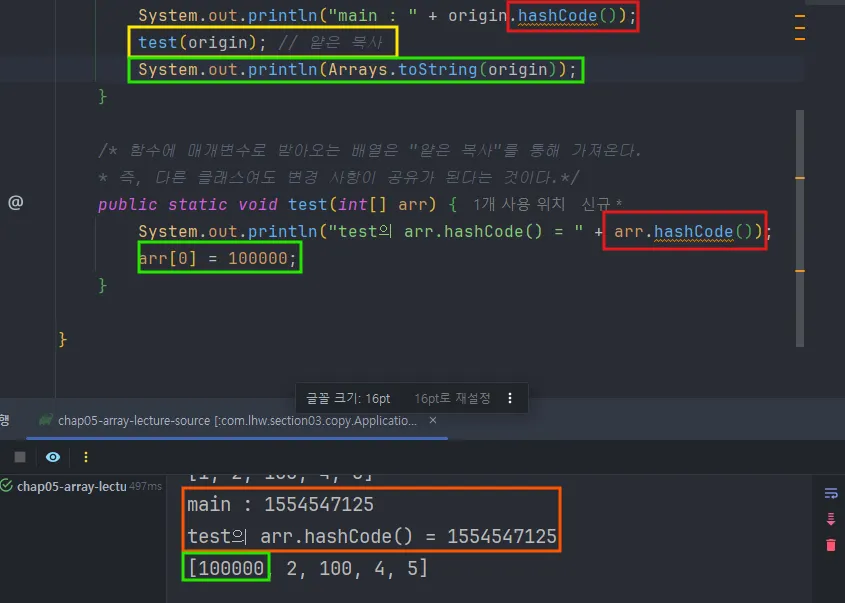
- 리턴 또한 얕은 복사를 통해 배열의 주소값을 넘겨 받는 것이다.
5.3.2 깊은 복사
깊은 복사는 주소값이 다른 또 다른 클론 배열을 생성하는 것이다.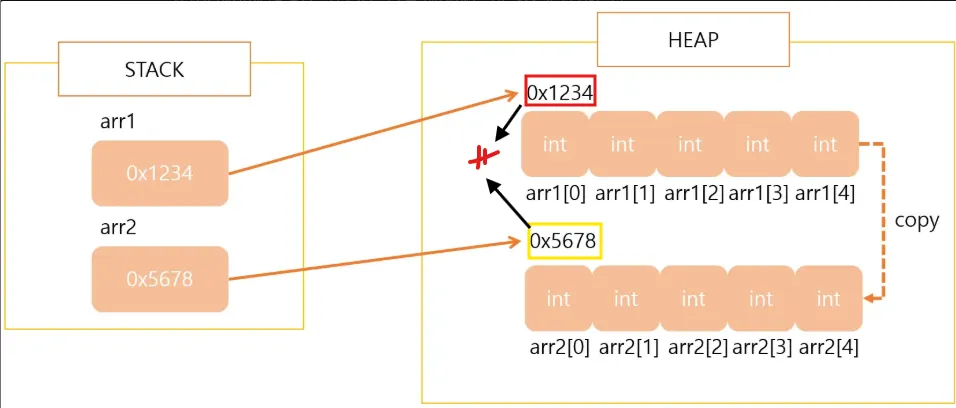
For 문을 통한 복사
for( ... ) {
for ( ... ) {
copy[i][j] = original[i][j];
}
}Object 객체의 Clone() 매소드
int [] copy = original.clone();
System의 arrayCopy() 메소드
arraycopy(원본,복사시작인덱스,복사배열,복사시작인덱스,복사할 길이)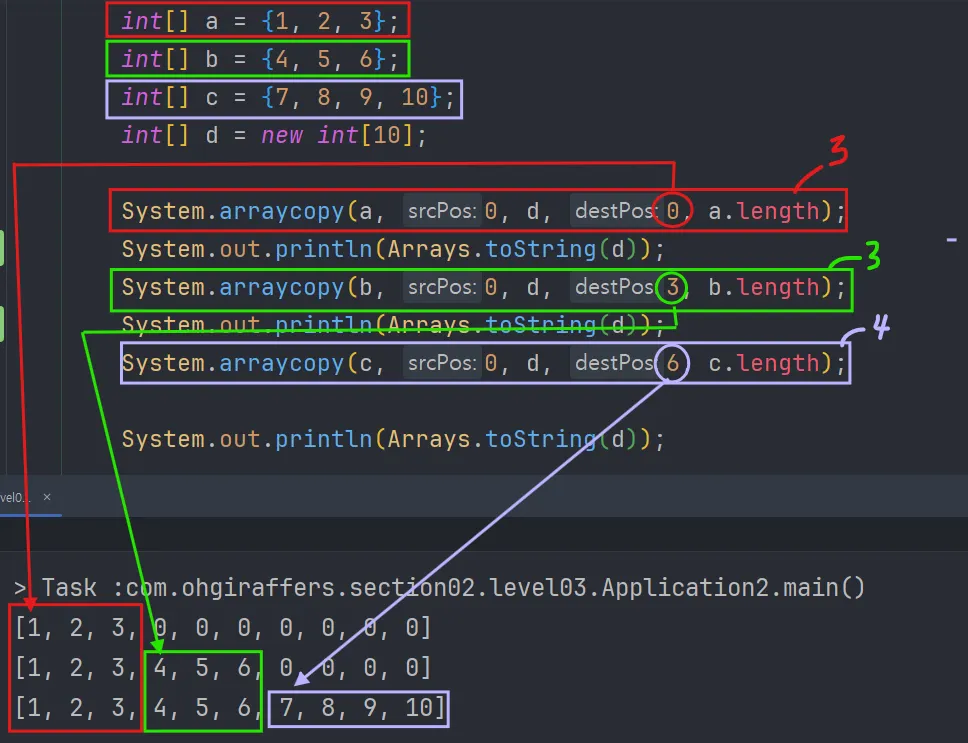
↳ 원하는 만큼 얼마나 복사할지 정할 수 있다.
**Arrays의 copyOf 메소드
Arrays.copyOf(복사랄배열,전체배열의길이설정))6. 클래스와 객체
6.1 인스턴스화 된 객체와 주소값
클래스를 인스턴스화 하여 객체를 생성하면 주소값이 생긴다.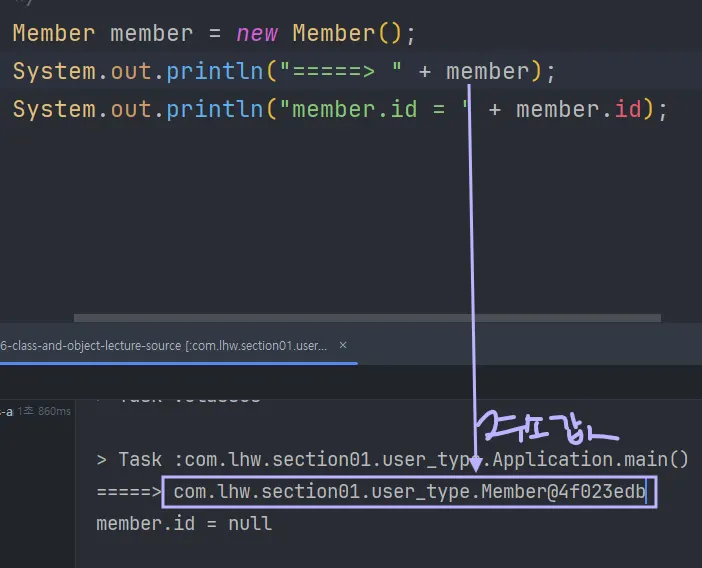
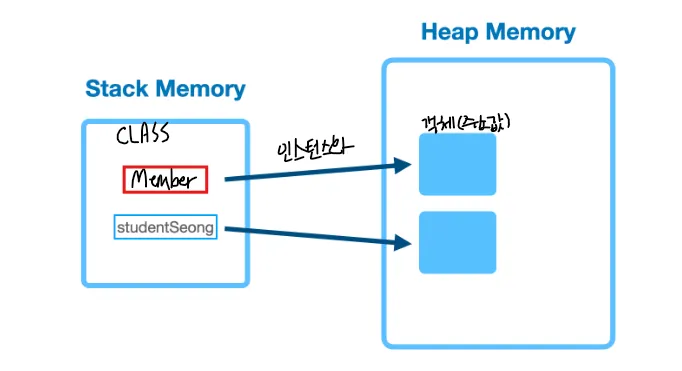
6.2 인스턴스화 시 객체 변수 JVM 초기화
객체는 Heap 영역에 저장되는데, 비어있는 값은 Heap에 들어가므로, JVM이 비어있는 객체의 변수들을 기본값으로 초기화 해준다.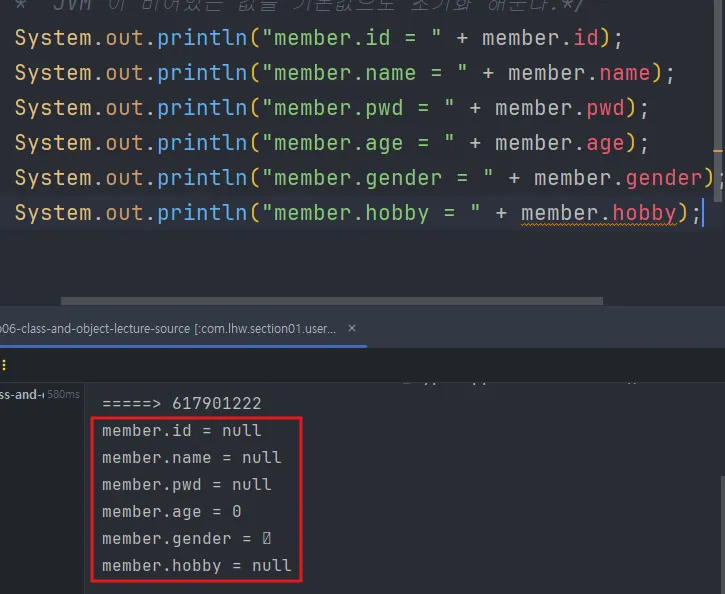
6.3 this.
인스턴스 변수가 생성되었을 때 자신의 주소를 저장하는 레퍼런스 주소이다.
생성된 객체의 주소값을 넣어두는 곳이다. 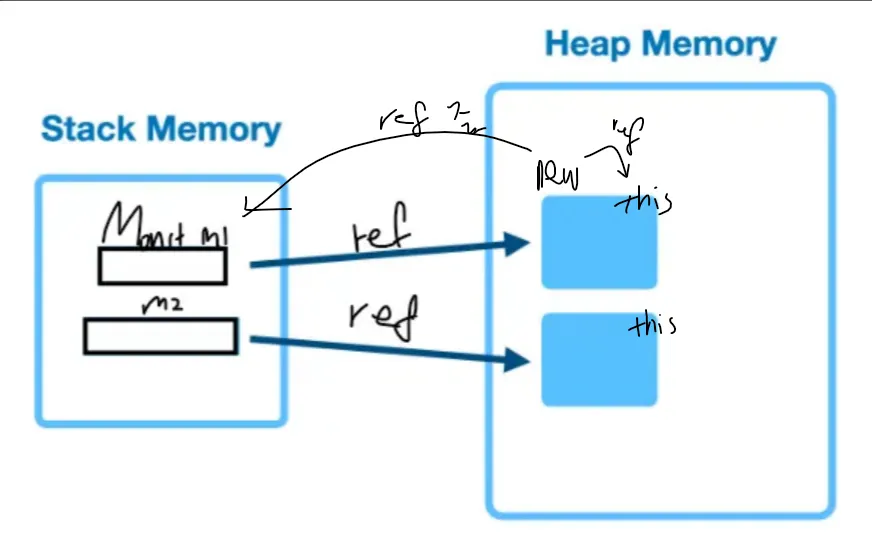
객체의 주소값을 동일하게 들고 있기 때문에 메소드에서 주소값을 뽑아내면 해당 메소드를 사용하는 주소값과 동일하게 출력된다.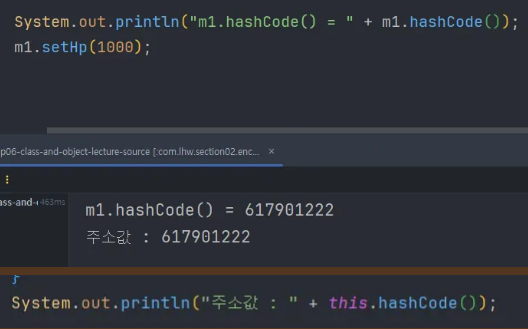
6.4 직접 접근과 간접 접근
6.4.1 직접 접근
필드에 직접 접근 시 필드(전역변수)에 변경이 생겼을 때 사용한 코드를 모두 수정해야 한다.
public class Application {
public static void main(String[] args) {
Monster m1 = new Monster(); // Heap에 m1(주소값) 올라감
m1.name = "두치";
m1.hp = 100;
Monster m2 = new Monster();
m2.name = "뿌꾸";
m2.hp = -100;
Monster m3 = new Monster();
m3.name = "드랴큘라";
m3.setHp(-200);
}
}
public class Monster {
// String name; 변경됨!
String types; => 위 Application에서 문제 발생 전부 고쳐줘야 함
int hp;
}6.4.2 간접 접근
이러한 문제가 생긴다면 애초에 문제를 피해가면 된다. 메소드를 이요하여 필드에 간접적으로 접근하는 것이다. 이는 setInfo(), getInfo()로 해결한다.
public class Application {
public static void main(String[] args) {
/* 필드에 직접 접근하는 경우 발생할 수 있는 문제점 이해
(왜 어떤 때는 public, 어떤 떄는 private를 써야 하는가?)
* - 필드에 직접 접근 시 필드 수정이 생겼을 때 사용한 코드를 모두 수정해야 한다.
* 이는 유지보수 측면에서 악영향을 끼친다.*/
Monster m1 = new Monster(); // Heap에 m1(주소// 값) 올라감
System.out.println("=====> " + m1.hashCode()); //주소값
// m1.name = "두치";
m1.setInfo("두치"); //
m1.getInfo();
System.out.println("m1.getInfo() = " + m1.getInfo());
}
}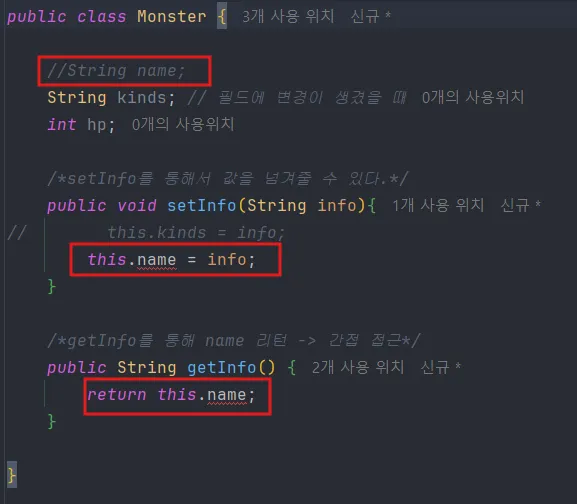
↳ 필드(전역변수)에 변경 사항이 생기자 메소드에만 문제가 생긴다. 메인코드에서 더 이상 접근하지 않기 때문이다.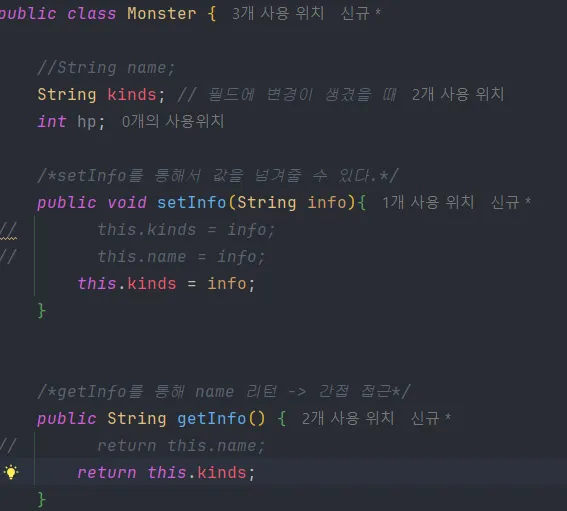
- 이와 같이
getInfo,setInfo메소드만 수정하면 문제가 해결된다.
6.5 직접 접근을 제한하는 접근 제한자
메소드를 통해서 간접 접근이 가능해졌지만, 여전히 직접 접근이 가능하다. 이를 접근제한자를 통해 접근 제한을 강제화할 수 있다.
↳ 필드는 private으로, 메소드를 public으로 설정하여 캡슐화(Encapsulation)을 진행한다.
모든 곳에서 필드에 직접 접근할 때 발생할 수 있는 문제점은 다음과 같다.
- 올바르지 않은 값이 들어와도 통제가 불가능하다.
- 필드의 변수를 변경할 때 사용하는 쪽에도 수정 영향을 미친다.
등의 문제가 존재한다. 따라서 아래와 같이 제한을 접근하는 솔루션을 제안한다.
직접 접근❌ 간접접근⭕ → 접근제한자
private String kinds;
private String hp;이런 식으로 필드에 private 접근제한자를 걸어주어 메소드로 간접 접근만 허용하도록 한다.
/*간접 접근 가능한 메소드를 정의하여 외부에선 메소드로만
* 접근 가능하도록 한다.*/
public void setInfo(String info){
this.kinds = info;
}
public String getInfo() {
return this.kinds;
}이와 같이 클래스 혹은 클래스의 멤버(필드, 메소드)에 참조 연산자로 접근할 수 있는 범위를 제한하기 위한 것이 접근제한자이다.
6.6 추상화
추상화란, 공통되냐 부분을 추출하고 공통되지 않고 불필요한 부분을 제거한다는 의미를 가지며, 추상화의 목적은 유연성을 확보하기 위함이다.
유연성 확보는 여러 곳에 적용될 수 있는 유연한 객체를 의미하며, 재사용성이 높아질 수 있게 한다는 의미이다.
즉, 추상화는 현실세계의 복잡한 사건을 단순화하여 새로운 객체 지향 세계를 창조해 가는 과정이다.
- 협력(애플리케이션에 구현에 필요한 객체간의 상호작용)
- 책임(객체가 협력에 참여하기 위해 수행해야 할 책임(기능))
- 역할(객체의 책임이 모여 하나의 역할이 된다.)
- SOLID는 이러한 점들을 지키기 위해 만든 원칙이다.
6.6 DTO
계층 간(클래스 끼리의 이동)의 데이터 전달 용도로 사용되는 클래스 캡슐화의 원칙을 따라 작성한다. 하지만 캡슐화가 의미 없을 정도로 필드명을 그대로 사용한 getter, setter 메소드로 인해 유지보수성이 좋지는 않다.
- 데이터 전송하는 객체에 대한 모든 것을 이야기한다.
→ 객체로 전달하는 방법, getter,setter로 전달하는 방법 등이 존재한다.
→ DB와 클래스 간 상호작용을 의미한다.
6.6.1 setter(설정자)와 getter(접근자)
getter/setter의 경우 실문에서 암묵적으로 통용되는 작성 규칙이 존재한다고 한다.
- Setter(설정자) 작성 규칙
필드값을 변경할 목적의 매개변수를 변경하려는 필드와 같은 자료형으로 선언하고 호출 당시 전달되는 매개변수의 값을 이용하여 필드의 값을 변경한다.[표현식] public void set필드명(매개변수) { 필드 = 매개변수; } [작성예시] public void setName(String name) { this.name = name; } - getter(접근자) 작성 규칙
필드의 값을 반환받을 목적의 메소드 집합을 의미한다. 각 접근자는 하나의 필드에만 접근하도록 한다. 필드에 접근해서 기록된 값을 return을 이용하여 반환하며, 이 때 반환타입은 반환하려는 값의 자료형과 일치시킨다.* [표현식] public 반환형 get필드명() { return 반환값; } [작성예시] public String getName() { return this.name; }
6.7 생성자
6.7.1 생성자 사용 목적
- 인스턴스 생성 시점에 수행할 명령이 있는 경우
- 매개변수 있는 생성자의 경우 매개변수로 전달받은 값으로 필드 초기화할 경우
- 작성한 생성자 외에는 인스턴스를 생성하는 방법을 제공하지 않고 싶을 경우
→인스턴스 생성 방법 제한, 초기값 전달 강제화
6.7.2 생성자 재사용
public User(String id, String pwd) {
this.id = id;
this.pwd = pwd;
System.out.println("User id, pwd 초기화 생성자 동작함");
}
public User(String id, String pwd, String name, Date enrollDate) {
// this.id = id;
// this.pwd = p|wd;
/* 동일 클래스 내의 다른 생성자 메소드를 호출하는 구문
* 리턴 되어 돌아오지만 리턴값은 돌아오지 않으며 가장 첫 줄에 선언해야 한다.*/
this(id, pwd); --> 위 생성자를 호출해서 사용할 수 있다.
this.name = name;
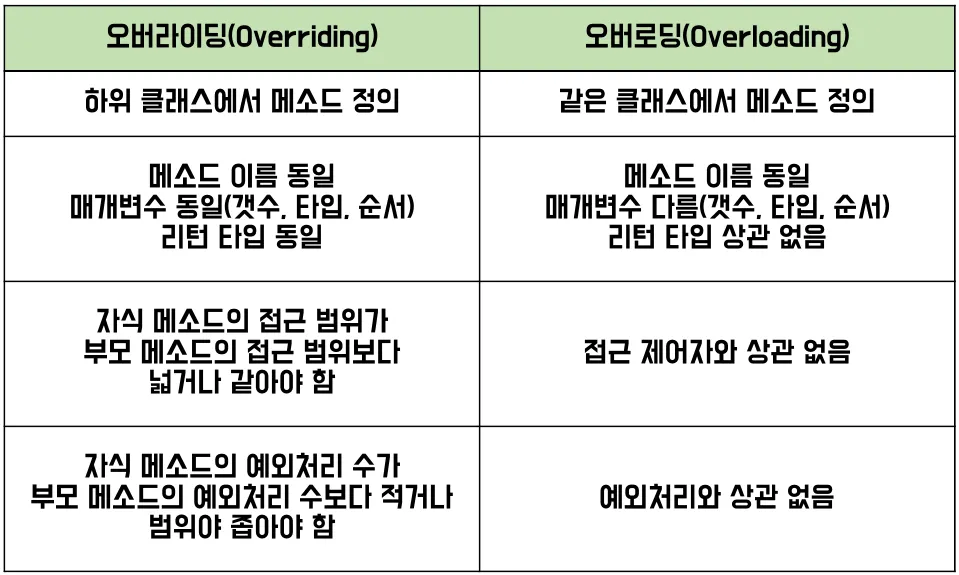
this.enrollDate = enrollDate;6.8 오버로딩
-
오버로딩: 같은 클래스 내에서 같은 이름의 메소드를 매개변수 부분(시그니쳐)만 다르게 하여 정의하는 것
-
사용 이유: 매개변수의 종류별로 메소드 내용은 다르게 작성해야 하는 경우
→ 동일 기능의 메소드를 매개변수에 따라 다른 이름을 붙이면 관리가 어려워지기 때문이다.
EX) System.out.println()
메소드의 시그니쳐
public void method(int num) {} 이라면, 메소드의 메소드명과 파라미터 선언 부분을 메소드의 시그니쳐(Signature)라고 한다. (method(int num 부분)
오버로딩의 조건
매개변수의 타입, 개수, 순서를 다르게 작성한다. 하나의 클래스 내에서 동일한 이름의 메소드를 여러 개 작성할 수 있다. 메소드의 헤드부에 있어 시그니쳐를 제외한 부분이 다르게 작성되는 것은 인정되지 않는다.
6.9 매개변수
매개변수
파라미터로 사용 가능한 자료형
1. 기본자료형
2. 기본자료형 배열
3. 클래스자료형(참조자료형)
4. 클래스 자료형 배열(객체 배열이지만 다음 쳅터에서 다룰 예정
5. 가변인자
6.9.1 기본자료형
기본자료형을 매개변수로 전달 받는 메소드 호출이다. 리터럴 값(참조 주소값 아님)을 전달해서 메소드를 호출할 때는 서로 다른 지역 변수에 영향을 주지 않는다.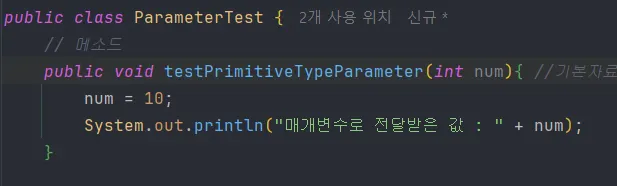
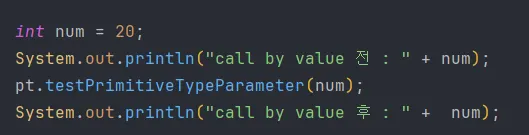
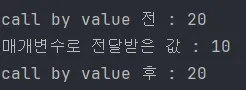
6.9.2 기본자료형 배열
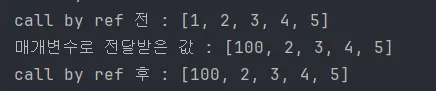
배열은 주소값으로 연결되어 있기 때문에 얕은 복사를 하게 된다. 즉, 원본이 바뀐다.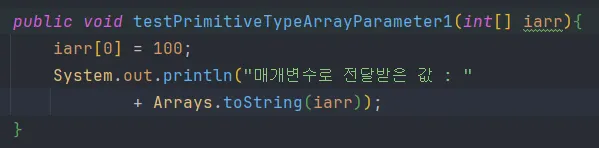
6.9.3 클래스 자료형
클래스 자료형을 매개변수로 전달받는 메소드를 호출한다. 객체의 주소값을 넘겨 메소드를 호출한다.
6.9.4 가변 인자
단일 변수, 배열까지 가능하다.
가변인자는 매개변수로써 뒤에 작성되어야 한다.
7. 상속
7.1 상속의 정의와 사용 이유
부모클래스가 갖는 멤버를 자식클래스가 물려받아 자신의 것처럼 사용할 수 있도록 만든 것이다. 멤버 외에도 부모 클래스의 타입 또한 상속이 된다. (다형성의 토대가 됨)
7.2 Super()
super() : 부모의 생성자를 호출하는 함수로, 직접 작성해주지 안항도 컴파일러에서 자동으로 생성해준다.
7.3 @Override
어노테이션 : 오버라이딩 성립 요건을 체크하여 성립되지 않으면 에러를 발생시킨다.
7.4 IS - A 관계
"자식 클래스는 (하나의) 부모 클래스이다." 라는 말을 만족(성립)하는 관계를 뜻하며 클래스 간 상속 관계를 파악하기 위한 키워드이다.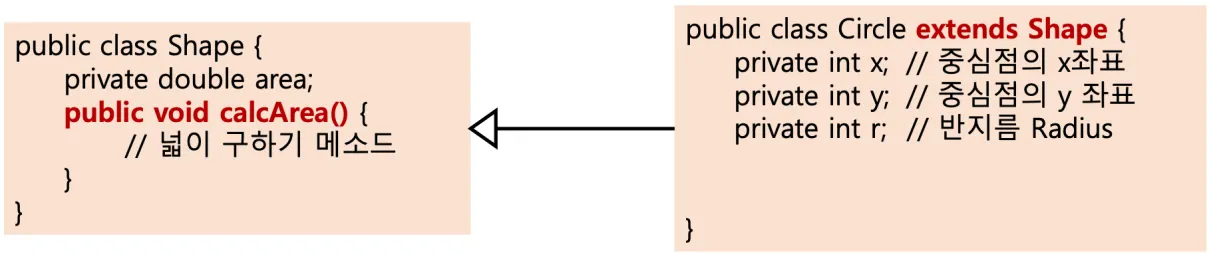
7.5 super 와 super()
Super keyword
super : 자식클래스를 이용해서 객체를 생성할 때 부모 생성자를 호출하여 부모 클래스의 인스턴스도 함께 생성하게 된다. 이 때 생성한 부모의 인스턴스 주소를 보관하는 레퍼런스 변수도
자식 클래스 내의 모든 생성자의 메소드 내에서 선언하지 않고도 사용할 수 있는 레퍼런스변수(주소값)이다.
@Override
public String getInformation() {
return super.getInformation()
+ "Computer ["
+ "cpu=" + this.cpu
+ ", hdd=" + this.hdd
+ ", ram=" + this.ram
+ ", operationSystem=" + this.operationSystem
+ "]";
}super() : 부모 생성자를 호출하는 구문으로 인자와 매개변수의 타입, 갯수, 순서가 일치하는
부모의 생성자를 호출하게 된다. this()가 해당 클래스 내의 다른 생성자를 호출하는
구문이라면, super()는 부모클래스가 가지는 private 생성자를 제외한 나머지 생성자를
호출할 수 있도록 한 구문이다.
public Computer(String cpu, int hdd, int ram, String operationSystem) {
/* 부모클래스의 기본생성자 호출 */
super();
this.cpu = cpu;
this.hdd = hdd;
this.ram = ram;
this.operationSystem = operationSystem;
}super() 와 this() 생성자
둘 다 함께 사용할 수 없다. 아래 사진을 확인해보자.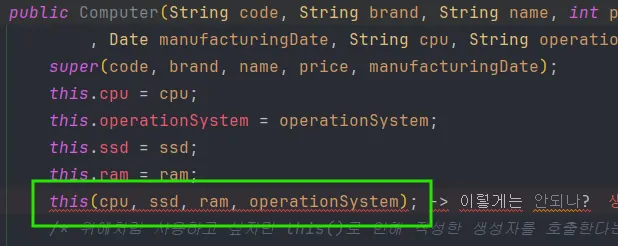
위처럼 사용하고 싶지만 this()로 인해 작성한 생성자를 호출한다는 의미는 부모 인스턴스를 두 개 생성할 수 없기 때문에 부모 생성자는 한 번만 호출할 수 있다. this 내에는 이미 super가 존재한다.(부모단일이라 안됨)
getter/setter
setter , getter 는 부모필드의 메소드에 대해서는 자신의 것처럼 사용 가능하기 때문에 따로 작성할 필요 없이 부모클래스에 작성한 것을 사용할 수 있다. 따라서 자식 클래스에 추가된 필드에 대해서만 setter/getter를 작성한다.
getInformation()
super.getInfo() : 정상적으로 부모메소드 호출
this.getInfo() : 본인의 getInfo호출
→재귀호출 StackoverflowgetInfo() : this.가 자동호출 → 오류 생김 반드시 super. 사용해야 함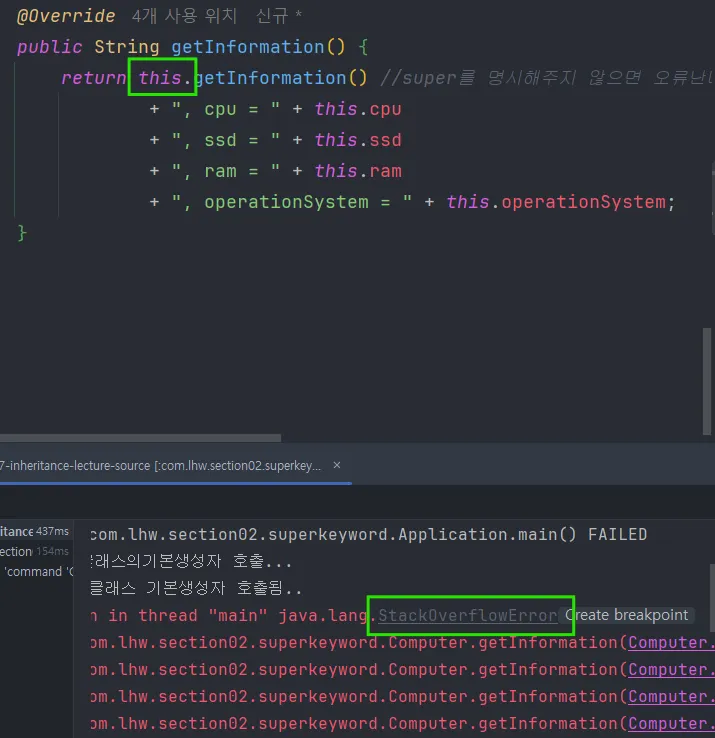
7.5.2 오버라이딩
💡 부모클래스에서 상속받은 메소드를 **자식 클래스가 재정의**하여 사용하기 위한 기술- 오버라이딩 성립 조건
1. 메소드명 동일
2. 메소드 리턴타입 동일
3. 매개변수의 타입, 개수, 순서가 동일
4. 부모 클래스의 private 메소드는 오버라이딩 불가능
5. 부모 클래스의 final 키워드가 사용된 메소드는 오버라이딩 불가능
6. 접근제어자는 부모 메소드와 같거나 더 넓은 범위여야 함
7. 예외처리는 같은 예외이거나 더 구체적(하위)인 예외를 처리해야 함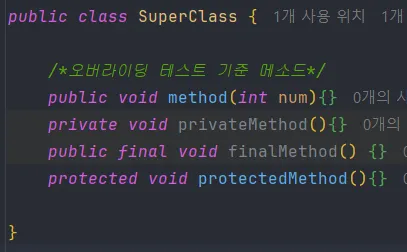
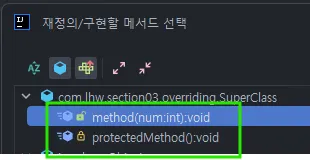
부모의 것을 자식이 동일한 시그니처로 재정의하는 것 - 기본적으로 상속이 되어야 한다.
7.5.3 오버라이딩과 오버로딩
💡 PROBLEM
- JAVA 수업을 들으면서 계속 프로젝트 회고록을 신경 쓰느라 수업 중간 중간을 놓쳤다. 물론 회고록도 중요하지만, 수업을 잘 따라가며 놓치지 않아야 하는데 자꾸 실수한다.
- 지난 수업 때 배운 내용들이 다 쉽고 간단한 내용들이라 복습을 하지 않았더니, 기억이 나지 않는 부분도 있고, 수업 시간 때 강사님이 배운 것이라 언급하셨는데 모르겠는 부분도 있었다. 아는 거라고 대충 듣고 딴짓하지 말고 수업에 잘 집중하자. 어차피 이제는 다 모르는 부분이라 최선을 다해야 한다.
- 잠을 잘 못자서 수업시간에 피곤했다.
🪛 TRY
- 인프런 스프링 공부
- 이번 주 안에 JAVA 프리코스 완주, 복습
- PCCP 금요일 준비
