
0. 서론
가. 왜 부지런하지 못했나? & 그동안 벨로그를 업데이트 하지 않은 이유?

진짜 수업을 따라가기 벅찼다. 비전공자로 클라우드 부분에 수업을 따라가는 것은 쉽지 않았다.
나. 지금은?
현재 실습 기관에 와서 그 동안 배운 내용을 정리하고, 새로운 내용을 일고 있었다. 그리고 다른 벨로그 글들을 읽으면서 깨달았다. 실패의 기록이 없으면 발전하지 못한다고...
다. 지금 올리는 이유는?
프로젝트를 보시고 선배님들의 조언을 받고 싶어 해당 내용을 공유합니다.
라. 프로젝트 정리 부분은 어떻게 구성되는가?
1)-1은 기술적 부분보다, 개요 정성적 자료 / -2는 전체적인 개발 구상도(최초, 수정) + CI/CD PRovid-3(데이터 크롤링 부분), -4(3Tier 부분), 기술적 부분 구축을 어떻게 하였는지 / 어려웠던 점은 어떤 부분인지 작성할 예정입니다.
미. 행사 관련 뉴스
해당 행사의 뉴스 : https://www.sedaily.com/NewsView/26F0J24PRY
1. 프로젝트 개요
가. 프로젝트 진행 기간 : 11월 ~12월 (4주)
나. 프로젝트 이름 : BUS(best User Sevice)
다. 프로젝트 설명 : 버스 시계열 데이터 수집을 통해 빅데이터 구축을 하며, 이를 통해 (광역)버스 기점 출발 시간 예측 시스템 개발
라. 프로젝트 성격 : 부트캠프(기존 강사님 + 외부 멘토님 한분)
마. 프로젝트 진행 인원 : 3명 (필자(조장), 팀원 2명 / 모두 비 전공자 )
바. 수상성과 :우수상(이라고 쓰고 참가상..)

사. 프로젝트 진행 중 학습내용 : PM 관리론 + 파이썬 + INFLUX DB + NAVERCLOUD NETWORK + CI/CD
아. 구축 환경 & 프로그램
1) 구축 환경 : Naver Cloud
가)cloud환경으로 구축한 이유
(1)가변성 : 우리가 만든 버스 프로그램은 버스의 운행시간이 주간에 집중되며, 이에 시간을 조회하는 사람들도
주간에 집중되기에, 시간대별 크롤링 서버에 가해지는 수요와 3Tier 서버에 대한 수요가 증가 할 수 밖에 없다.
그렇기 때문에 클라우드 환경에서 서버를 구축하였다
(실제로는 클라우드 캠프인데...클라우드로 구축해야지.)
(2)보안성 : 비록 한정된 시간으로 인해 실사용 서버까지 제작하지는 못하였지만, 추후 실 사용 서버까지 제작한다면,
소규모 그룹의 한계로 인해 보안성을 갖추기가 많이 힘들다, 하지만 클라우드로 구축하게 되면,
접속의 보안성은 가질 수 있다. 나)NCLOUD환경으로 구축한 이유

(1)보안 인증 :추후 어플리케이션으로 해당 서비스를 확장한다면,
정보보안 인증을 통과한 국내 클라우드인 네이버 클라우드가 더 유리하다고 생각하였다.
(2)개발방법론(API) : 네이버의 각종 API(Souce commit, souce build, Souce delploy)를 이용하면
개발 속도를 높일 수 있다고 생각하였다.
2) 사용 프로그램(-2에서 구조도 및 상세 설명 계속)
Naver VPC[subnet(public/privite/Load balnace) / NIC / Route table / ACG / Load balnce ]
NAVER SEVER[SEVER / AutoSaciling /INIT SCRIPT ]
NAVER Pipline[naver Commit / naver Build / Naver Deploy] & PROVIDER[TERRAFORM]
Python[data Crolling]
WEBSEVER[NGINX]
APPSEVER[WSGI : GUNICRON / FRAMEWORK : DJANGO]
DB [Data crollign DB : InfluxDB[INFLUXDB] / 3 Tier DB : MYSQL[MYSQL]]
2. 프로젝트 선정 이유
가. (발표에는 없었던) 실질적인 이유
우리가 지원한 제안이(멘토님 2분의 제안 이 서로 상이하였음) Influx DB를 사용해 보는 것이었고,
Influx DB의 특성상 시계열 데이터를 활용해야 하였기에 이를 효과적으로 제공 할 수 있는 부분이라고 생각되었기에
해당 프로젝트를 선정하였다. 나. 발표상 선정 이유
1)경기도 양주의 지역적 특색 : 경기도를 관통하는 광역 버스가 많습니다.
2)현재 지도 서비스의 부족 : 현재 네이버 지도를 위시로 한 각종 지도 어플리케이션에서는
출발한 버스의 도착 시간은 확인이 가능하나, 출발하지 않은 버스에 시간을 알 수 없었다.
3)버스 회사의 자료 공급 부족 : 인터넷 등에서 광역버스 시간표를 검색하면 데이터가 검색되나,
해당 자료가 재대로 업데이트 되지 않고 있었습니다.
4)내부 타임 테이블 존재 : 전화로 해당 내역을 문의하면 TIME TABLE을 안내해줍니다. 따라서 내부적으로는 타임 테이블이
존재하나 -> 회사에서 이를 제공하지 않으며 이로 인해 공공 API에서 해당 내용을 제공하지 않습니다. 5)이에 해당 정보를 크롤링하여 -> 빅데이터 화 한 뒤 -> 분석을 통해 해당 타임테이블을 버스 회사를 대신하여 제공하고자 하였습니다.
3. 최초 일정 계획(간트차트)
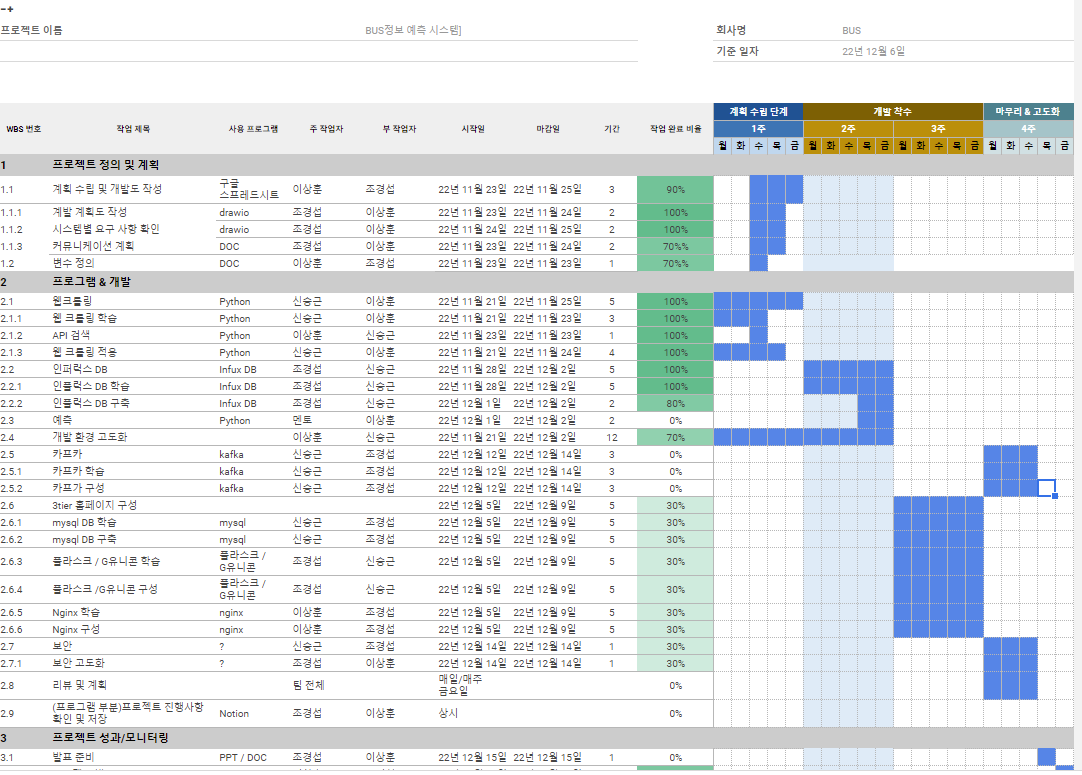
4. 완성 정도 / 미진했던 부분
가. 프로젝트 계획
데이터 크롤링 + 데이터 분석 + CI/CD파트 완성
나. 1차 고도화 계획
3tier 프론트 엔드 홈페이지 완성
다. 2차 고도화 계획
크롤링 버스의 댓수 늘리기
라. 3차 고도화 계획
카프카 적용

실제 완성
가 부분 . 데이터 크롤링 + CI/CD 완성
-> 데이터 분석 부분 실패
나. 1차 고도화 계획
-> 3tier 구성 실패
5. 아쉬웠던 점

팀장으로써 PM역활을 수행하였음에도, 프로젝트가 안 풀렸을때 이것을 어떻게 하지?
보다 왜 이사람이 못했는가? 하는 남탓을 많이 하였던 것 같다,
그리고 업무와 의사소통에 있어서 어느 순간 남탓만 하며, 좌절했던 것 같다.
그렇기에 얼마전에 우연히 만나 친하게 연락드리고 있는,
어떤 PM님을 만나뵈었다. 그리고 나와같은 테스트 프로젝트가 아닌, 실 프로젝트 5개를 한번에 진행하고 있다는 것을 들으며,
내가 어찌되었던 IT업종(아니 사실 그 어떤 업종에서든) 다시한번 사람이 아닌 task를 중시하는 방법론을 일을 하면서도
배워야 한다고 다시한번 다짐하였다. 
34살 조금은 늦은 나이에 클라우드 엔지니어를 꿈꾸는 청년