서비스의 형태가 다양해지고 커지면서 최소 천만건 이상의 데이터를 처리하고 저장하는 VLDB(Very Large Database) 형태가 되었다. 이로 인해 응답/처리 속도의 저하, 장애 증가, 비용 증가 등의 이슈들이 발생하게 됐다. 이에 대한 해결 방안으로 대표적으로 Table 레벨에서는 Partitioning, DB 레벨에서는 Sharding 기법들을 사용하고 있다.
Partitioning
Table을 분할하여 가용성, 관리용이성, 성능을 향상시키기 위해 사용한다.
- 가용성 : Table이 물리적으로 분할되어 데이터의 훼손 가능성을 줄이고 가용성 향상
- 관리용이성 : Table을 분할하여 관리를 쉽게 함
- 성능 : DML Query 성능 향상. 대용량 Write에 효율적
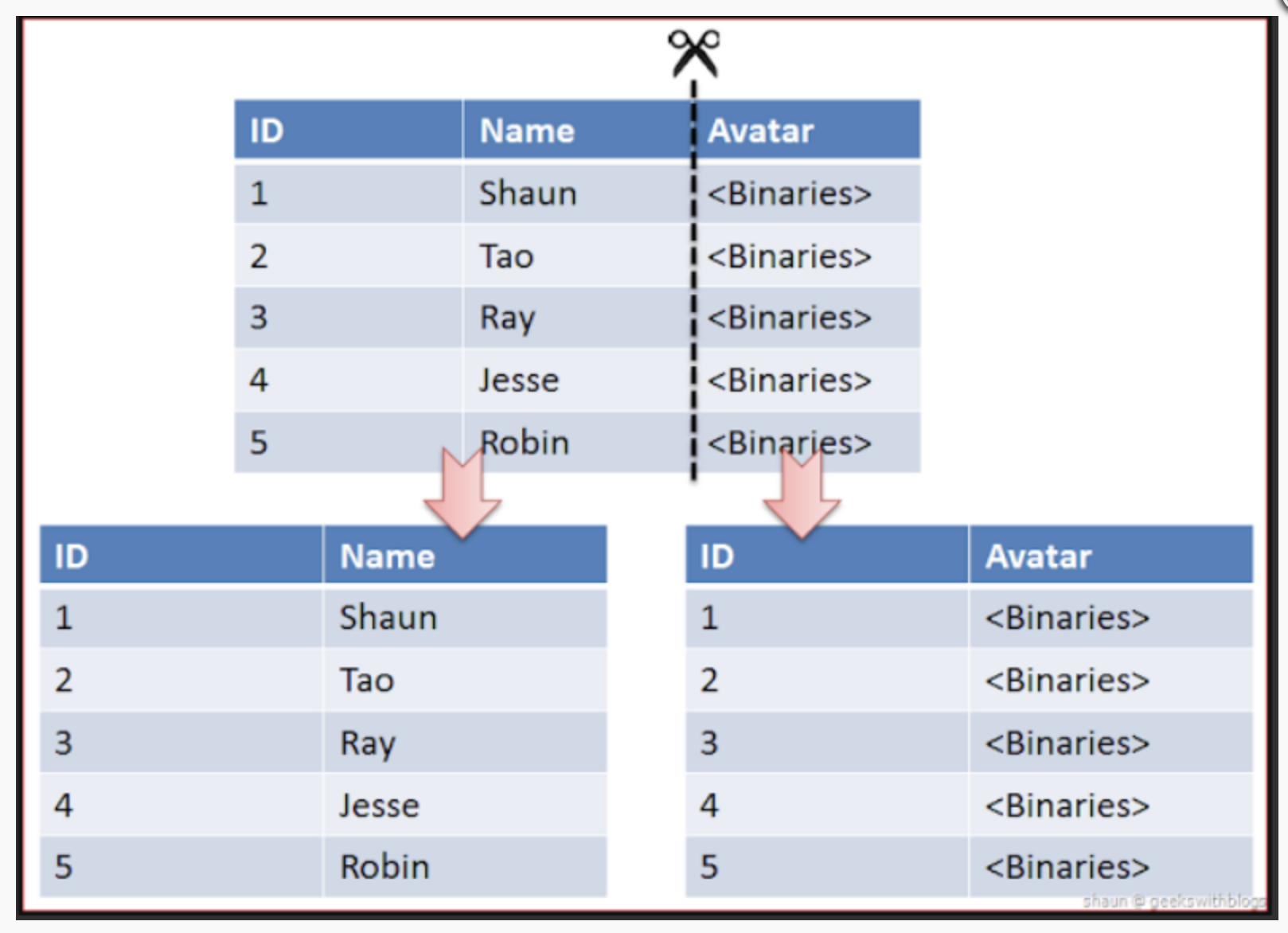
Vertical Partitioning
정규화(Nomalization)된 Table에서 Column의 사용 빈도에 따라 추가적으로 분할하는 방식이다. Table이 변경되며, 조회 시에 Table Join에 대한 비용이 발생한다.
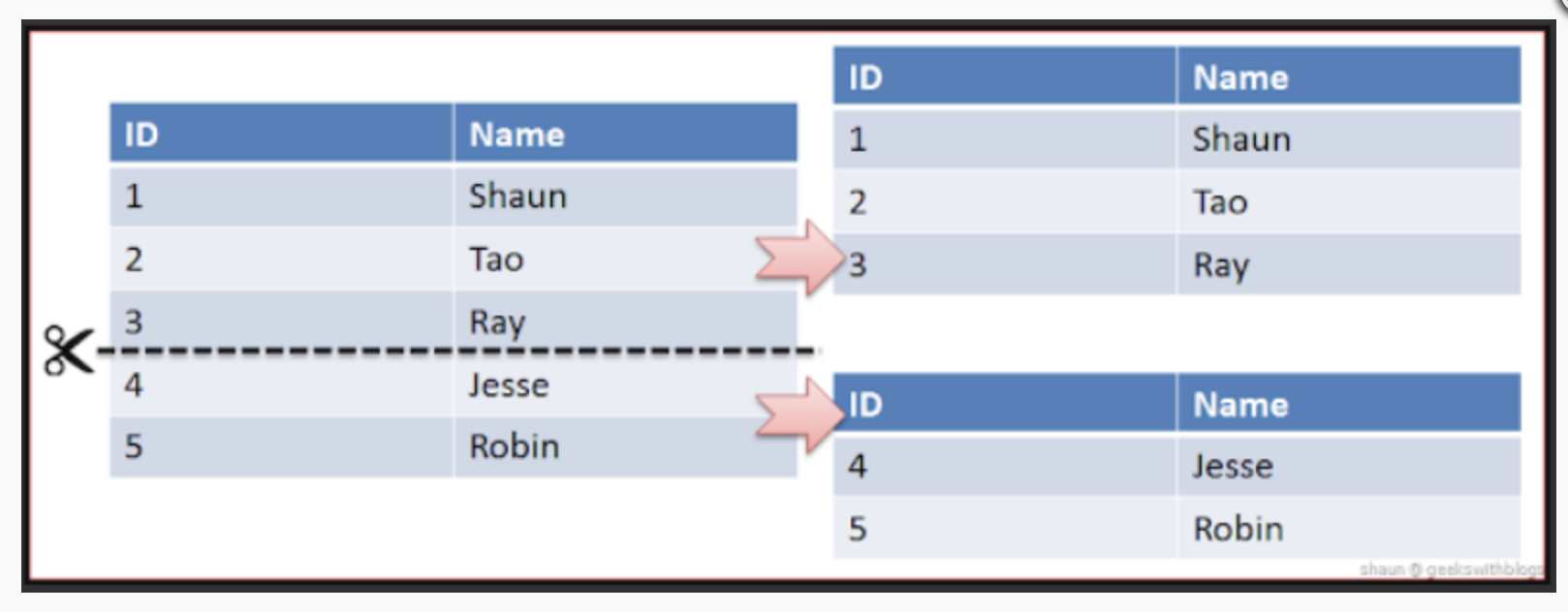
Horizontal Partitioning
데이터를 특정 기준에 따라 분할한다. 데이터가 있는 Partition을 찾기 위한 비용이 발생한다.
Range Partitioning
데이터의 범위를 지정하여 분할한다.
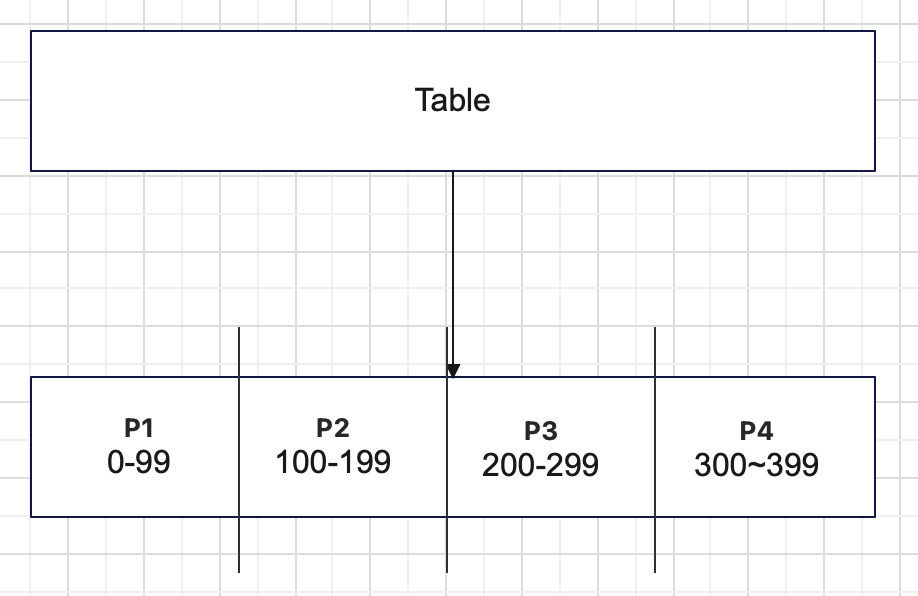
- 장점 : 관리가 편함
- 단점 : Hot Spot Partition이 발생할 가능성 있음
Hash Partitioning
Hash 함수를 활용해 분할한다.
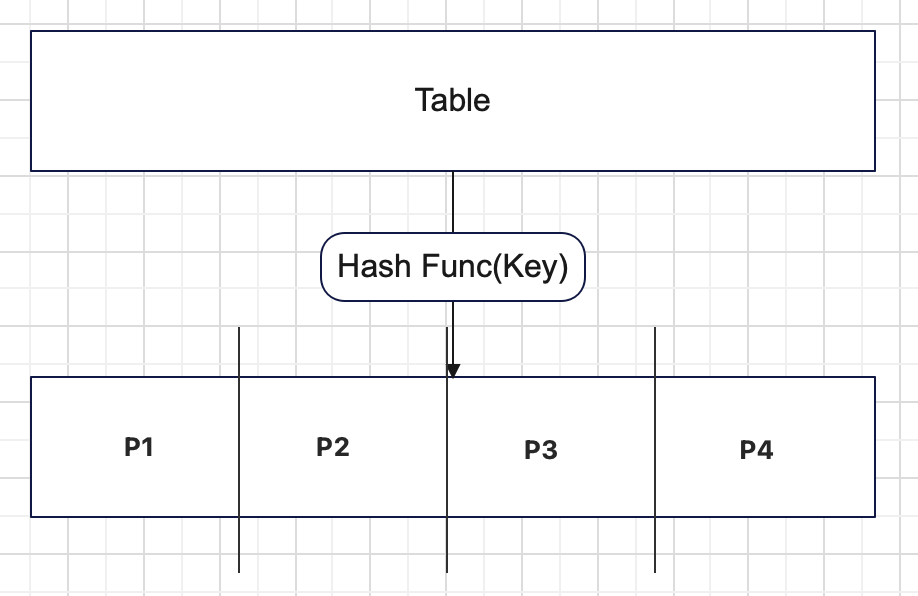
- 장점 : 데이터가 균일하게 분포됨
- 단점 : Partition을 변경할 경우 Rehashing 비용이 발생, 원하는 조건에 해당하는 데이터를 찾기 어려움
List Partitioning
특정 값으로 데이터를 분할한다.
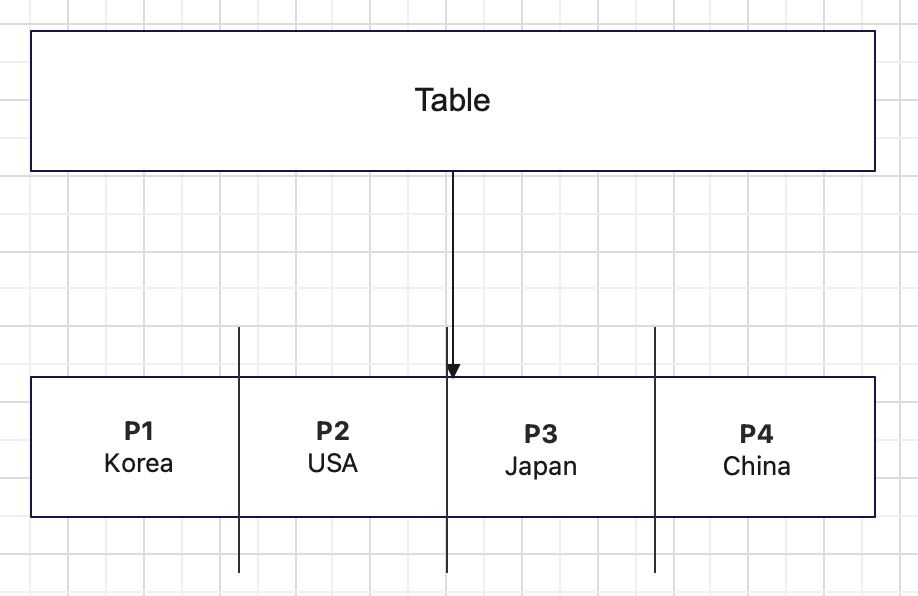
- 장점 : 특정 Partition에 저장될 데이터에 대한 명시적 제어가 가능
- 단점 : 데이터의 분포도가 떨어질 경우 효율이 떨어짐
Composite Partitioning
Partitioning을 해도 효과적으로 관리하기 힘든 경우 Sub-Paritioning을 추가하여 분할한다.
ex) Range-Hash, Hash-List
Sharding
DB를 확장하는 방법은 Partitioning과 동일하게 수직과 수평 2가지 방식이 있다. 수직으로 확장하는 것은 Scale-Up을 의미한다. Sharding은 수평적으로 확장하는 방식으로 Scale-Out된 DB Node들에 데이터를 분할하여 각 Shard Node에 저장한다.
Sharding은 데이터 분할 방법과 이로 인한 이점들은 Partitioning과 비슷하나 DB를 물리적으로 분산시켜 크기를 줄이고, 트래픽 부하 분산을 목표한다 점에서 다르다.
Sharding은 잘못 설계될 경우 데이터가 소실되거나 부하의 불균형이 발생할 수 있다. 또한 구현이 복잡하기 때문에 DB 이전 구조로 되돌리기가 어렵다. 그러나 서비스의 규모가 커질 것을 예상해서 Sharding될 가능성을 어느정도는 고려하여 설계해야 한다.
Vertical Partitioning
Partitioning과 동일하게 정규화(Nomalization)된 Table에서 Column의 사용 빈도에 따라 추가적으로 분할하는 방식이다. Table이 변경되며, 물리적으로 분리되었기 때문에 Join이 불가능하다.
Horizontal Sharding
Range Based Sharding
범위를 기준으로 Shard Node를 특정한다.
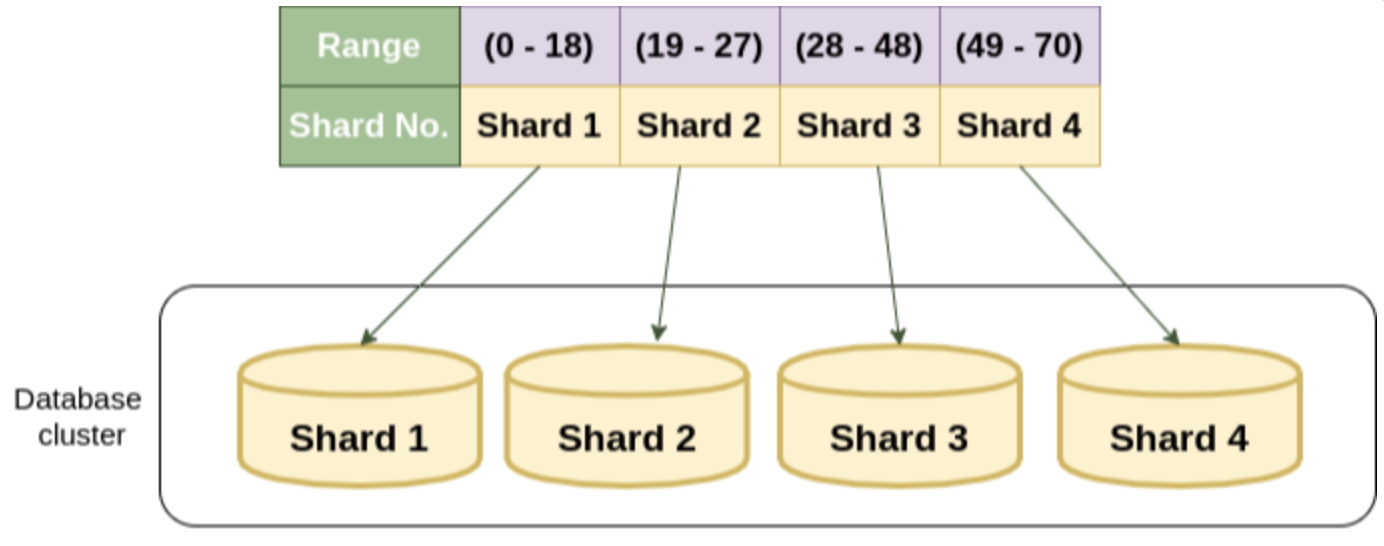
- 장점 : Node 증설에 재정렬 비용이 들지 않음
- 단점 : Hot Spot Node가 발생할 수 있음
Hash Based Sharding
해시 함수를 통해 Shard Node를 특정한다.
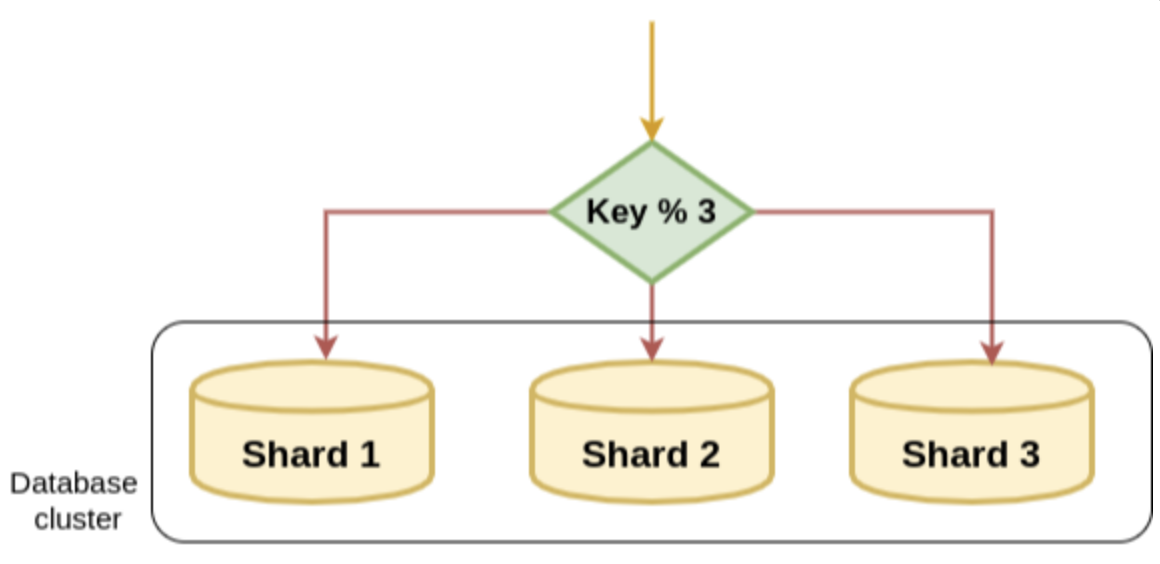
- 장점 : 데이터가 균일하게 분배됨
- 단점 : Node를 추가 증설할 경우 재정렬 비용 발생함, 범위 질의가 효율적이지 못함
Directory Based Sharding
Shard Node 정보를 가진 Table을 통해 Shard Node를 특정한다.
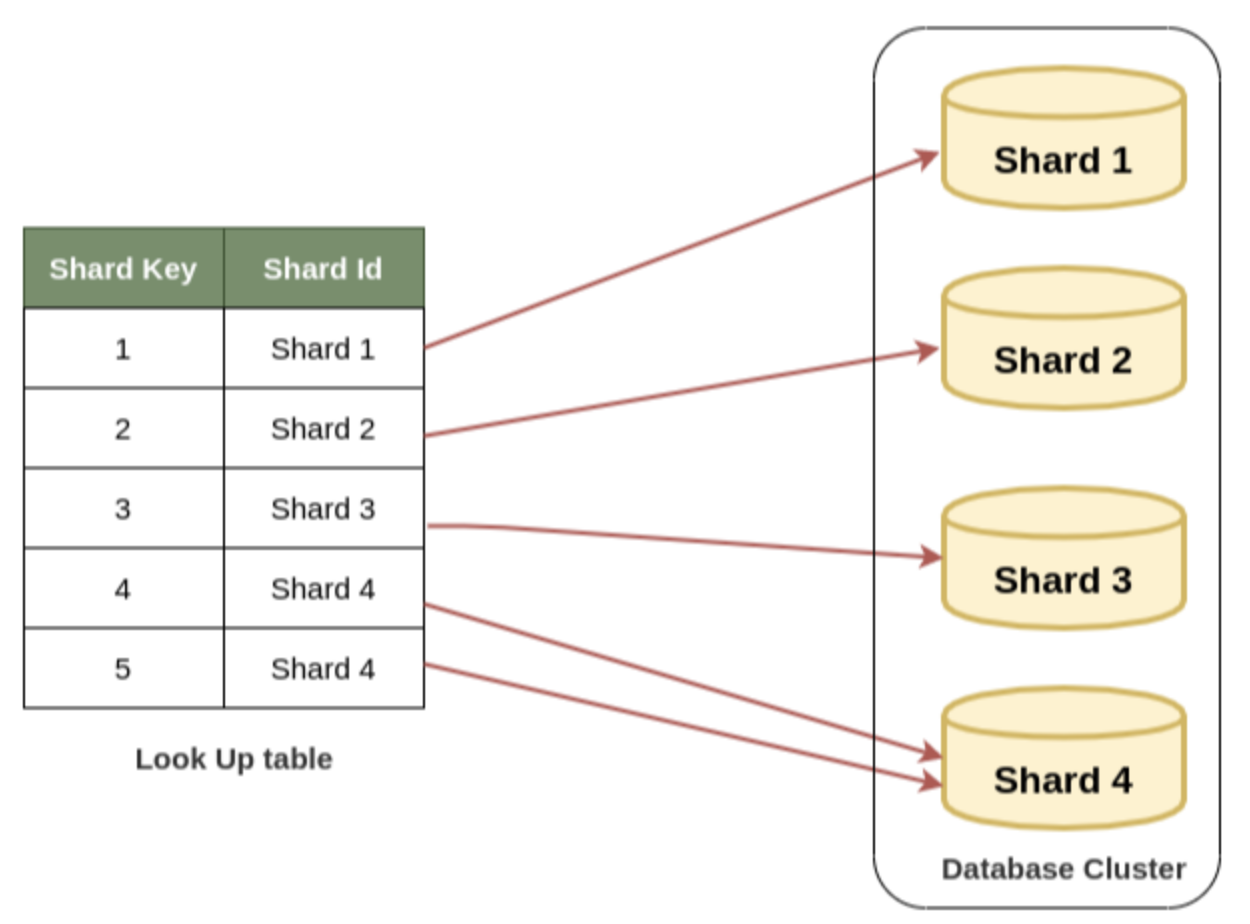
- 장점 : Shard Node의 확장이나 축소가 자유로움, Sharding에 필요한 시스템이나 알고리즘을 유연하게 설정할 수 있음
- 단점 : 모든 Read/Write 과정에서 Table을 참조해야 하므로 오버헤드가 발생함, Table이 실패지점이 될 수 있음
참조글
VLDB
Partitioning
- https://nesoy.github.io/articles/2018-02/Database-Partitioning
- https://coding-factory.tistory.com/840
Sharding
