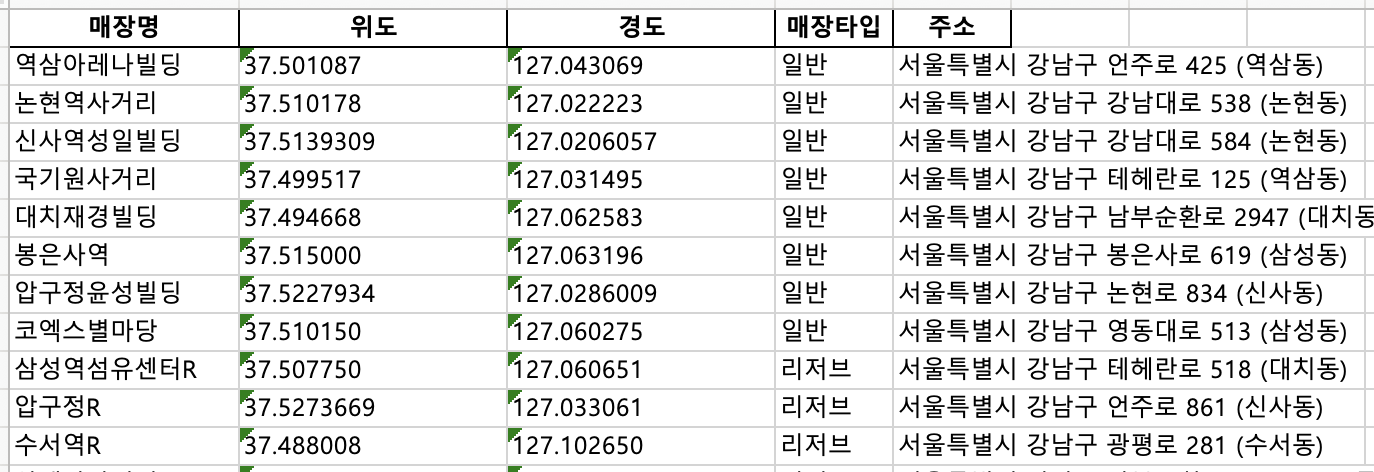
한국 스타벅스 매장 데이터가 필요한데 따로 데이터를 제공하지 않더라구요. 그래서 홈페이지 내용을 크롤링해서 excel로 데이터를 export하는 코드를 작성했습니다.
저는 간단하게 하고싶어서 colab을 이용해서 개발했습니다! 아래는 코랩 링크입니다.
결과 링크
Selenium이란?
Selenium은 웹 애플리케이션 테스트 자동화 및 데이터 크롤링에 사용되는 도구입니다.
동적 웹페이지에서 데이터를 가져오거나, 반복적인 브라우저 작업을 자동화할 수 있습니다.
- 주요 기능
- 웹 브라우저 제어 (Chrome, Firefox 등 지원)
- HTML 요소 탐색 및 상호작용 (클릭, 입력, 데이터 추출 등)
- 다양한 프로그래밍 언어(Java, Python 등)와 호환
코드 설명
이 코드는 Selenium을 사용하여 스타벅스 공식 홈페이지에서 매장 정보를 수집하고, 데이터를 엑셀 파일로 저장하는 Python 코드입니다.
주요 기능
-
지역별 매장 정보 크롤링
- 각 지역 버튼을 클릭해 매장 리스트를 확인하고 데이터를 추출합니다.
- 매장 이름, 위도, 경도, 매장 유형(일반, 리저브, 드라이브스루), 주소를 수집합니다.
-
엑셀 파일 저장
- 수집한 데이터를 지역별로 엑셀 파일로 저장하며, 모든 데이터를 통합한 파일도 생성합니다.
코드
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import pandas as pd
# Chrome WebDriver 옵션 설정
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') # 브라우저 GUI 비활성화
chrome_options.add_argument('--no-sandbox') # 샌드박스 옵션 비활성화
chrome_options.add_argument('--disable-dev-shm-usage') # 리소스 제한 방지
chrome_options.add_argument('lang=ko_KR') # 브라우저 언어 설정
# 웹 크롤링 시작
browser = webdriver.Chrome(options=chrome_options)
browser.get('https://www.starbucks.co.kr/store/store_map.do?disp=locale')
browser.implicitly_wait(5)
columns = ['매장명', '위도', '경도', '매장타입', '주소']
all_starbucks_list = [] # 모든 매장 데이터를 저장할 리스트
save_loc = '/content/drive/MyDrive/Colab Notebooks/AI와데이터기초/personnal'
# 매장 정보 크롤링 함수
def crawl_starbucks_by_region(region_index):
try:
loc_search_button = browser.find_element(By.XPATH, '//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/header[2]/h3/a')
browser.execute_script("arguments[0].click();", loc_search_button)
time.sleep(5)
region_button = browser.find_element(By.XPATH, f'//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[{region_index}]/a')
region_name = region_button.text
print(f"{region_index}번째 지역: {region_name}")
region_button.click()
time.sleep(2)
if region_index < 17:
all_button = browser.find_element(By.XPATH, '//*[@id="mCSB_2_container"]/ul/li[1]/a')
all_button.click()
time.sleep(5)
stores = browser.find_elements(By.CLASS_NAME, 'quickResultLstCon')
print(f"{region_name} 매장 수: {len(stores)}")
region_stores = []
for store in stores:
name = store.get_attribute('data-name')
lat = store.get_attribute('data-lat')
lng = store.get_attribute('data-long')
store_type = "리저브" if name.endswith('R') else ("드라이브스루" if name.endswith('DT') else "일반")
address = str(store.find_element(By.CLASS_NAME, 'result_details').get_attribute('outerHTML')).split('>')[1].split('<br')[0].strip()
region_stores.append([name, lat, lng, store_type, address])
df = pd.DataFrame(region_stores, columns=columns)
df.to_excel(f'{save_loc}/starbucks_store_list_{region_name}.xlsx', index=False)
print(f"{region_name} 저장 완료")
return region_stores
except Exception as e:
print(f"오류 발생: {e}")
return []
# 모든 지역 크롤링
for i in range(1, 18):
print(f"----- {i}번째 지역 크롤링 시작 -----")
region_stores = crawl_starbucks_by_region(i)
all_starbucks_list.extend(region_stores)
print(f"----- {i}번째 지역 크롤링 완료 -----")
# 전체 데이터 저장
all_starbucks_df = pd.DataFrame(all_starbucks_list, columns=columns)
all_starbucks_df.to_excel(f'{save_loc}/all_starbucks_store_list.xlsx', index=False)
print("크롤링 완료. 모든 데이터 저장.")
browser.quit()결과 🚀
- 지역별 스타벅스 매장 정보를
save_loc위치에 엑셀 파일로 저장합니다. - 예시 파일 구조:
starbucks_store_list_서울.xlsxall_starbucks_store_list.xlsx

이것저것 모음집
안녕하세요? 코딩이 아예 처음인제 자세히 코드를 알려주셔서 감사합니다.
저는 대학교 과제로 동일한 주제의 코딩을 하려고 하는 학생입니다.
실례가 되지 않는다면 엑셀 파일도 공유해주실 의향이 있으신지 여쭤보고자 합니다.