91일차 시작.... (분류)
ROC Curve와 AUC 면적statsmodels의 로지스틱 회귀모델로지스틱 회귀분석이 중요한 이유?로지스틱 회귀분석이란?분류 모델 평가 지표일반화된 선형 분류 모델 - glm()재현율(Recall)정밀도(precision)정확율(Accuracy)혼동 행렬(Confusion Matrix)
0
[교육] Python ML
목록 보기
6/17

📊 로지스틱 회귀분석
📌 로지스틱 회귀분석이란?
- 정의
- 독립변수(연속)을 통해 종속변수(범주)을 회귀 분석하는데 Sigmoid함수를 이용해 분류하는 분석 방법
- 특징
- 독립변수 : 연속형
- 종속변수 : 범주형
- 분류 방법
1) 일반 회귀분석 진행
2) 연속형 예측값에 대해 Sigmoid 함수 적용
3) 출력범위를 0 ~ 1 사이의 연속형 데이터로 변환
4-1) 0.5미만일 때, 0으로 분류
4-2) 0.5이상일 때, 1로 분류
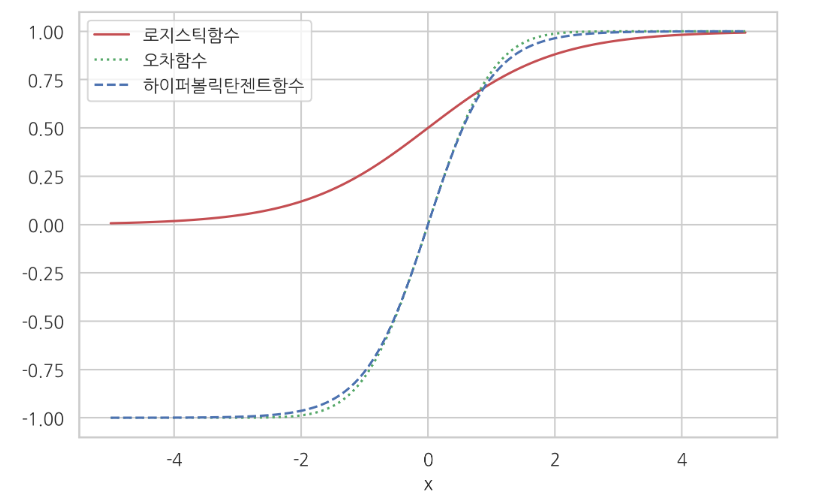
- Sigmoid - loss func - Hyper tahn
Logistic(Sigmoid) : 0 ~ 1
loss : -1 ~ 1
Hyper tanh : -1 ~ 1
📌 로지스틱 회귀분석이 중요한 이유?
- 이유
- 딥러닝 모델에서 각 Layer마다 로지스틱 회귀분석 수식을 사용하여 층을 쌓기 때문이다.
📊 statsmodels의 로지스틱 회귀모델
📌 분류 작업 수행
1. 라이브러리 Import
import numpy as np import statsmodels.api as sm from statsmodels.formula.api import logit # statsmodels의 분류 모델 from sklearn.metrics import accuracy_score # 분류 정확도 지표 모듈
2. 데이터 준비
data = sm.datasets.get_rdataset('mtcars').data print(data.head(3)) # mpg cyl disp hp drat wt qsec vs am gear carb # Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 # Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 # Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
3. 사용 칼럼만 추출 (mpg, hp, am)
data = data.loc[:, ['mpg', 'hp', 'am']] print(data.head(3)) # mpg hp am # Mazda RX4 21.0 110 1 # Mazda RX4 Wag 21.0 110 1 # Datsun 710 22.8 93 1
4. label(am)의 유니크값 확인
print(data['am'].unique()) # [1 0] # -> 이항 분류 가능
5. 연비와 마력수에 따른 변속기 분류(수동, 자동)
model = logit(formula='am ~ mpg+hp', data=data).fit() print(model.summary()) # Logit Regression Results # ============================================================================== # Dep. Variable: am No. Observations: 32 # Model: Logit Df Residuals: 29 # Method: MLE Df Model: 2 # Date: Thu, 17 Nov 2022 Pseudo R-squ.: 0.5551 # Time: 15:12:43 Log-Likelihood: -9.6163 # converged: True LL-Null: -21.615 # Covariance Type: nonrobust LLR p-value: 6.153e-06 # ============================================================================== # coef std err z P>|z| [0.025 0.975] # ------------------------------------------------------------------------------ # Intercept -33.6052 15.077 -2.229 0.026 -63.156 -4.055 # mpg 1.2596 0.567 2.220 0.026 0.147 2.372 # hp 0.0550 0.027 2.045 0.041 0.002 0.108 # ============================================================================== # [ 로지스틱 회귀 모델 summary 분석 ] # mpg p-value = 0.026 < 0.05 이므로 feature는 적절한 label을 도출 가능 -> feature 적합성 만족 # hp p-value = 0.041 < 0.05 이므로 feature는 적절한 label을 도출 가능 -> feature 적합성 만족[ 로지스틱 회귀 모델 summary 분석 ]
- mpg p-value = 0.026 < 0.05 이므로 feature는 적절한 label을 도출 가능 -> feature 적합성 만족
- hp p-value = 0.041 < 0.05 이므로 feature는 적절한 label을 도출 가능 -> feature 적합성 만족
6. 예측갑, 실제값 비교
# np.around() : 0.5를 기준으로 0과 1로 분류하여 반환 y_pred = model.predict(data.iloc[:, :2]).values y_pred = np.around(y_pred) print('예측값 : ', y_pred[:3]) print('실제값 : ', data['am'].values[:3]) # 예측값 : [0. 0. 1.] # 실제값 : [1 1 1]
7. 혼동행렬 테이블 구하기
- logit 모델의 pred_table() 메소드
→ 혼동행렬 테이블을 바로 반환 해줌conf_tab = model.pred_table() print(conf_tab) # [[16. 3.] # [ 3. 10.]]
8. 분류 정확도 측정
# 수기 정확도 확인 print('정확도 : ', (16 + 10)/len(data)) # 정확도 : 0.8125 # sklearn 모듈을 통한 정확도 확인 print('sklearn 기반 정확도 : ', accuracy_score(data['am'].values, y_pred)) # sklearn 기반 정확도 : 0.8125 # -> 분류 정확도 = 81.2%로 높은 성능을 보임 -> 모델 정확성 만족
📌 일반화된 선형 분류 모델 - glm()
1. 필요 라이브러리
# 모델 학습 시, family 속성 값으로 사용할 Binomial 모듈 import stats.api as sm import statsmodels.formula.api as smf
2. 일반화 선형 분류 모델 학습
model = logit(formula='am ~ mpg+hp', data=data, family=sm.families.Binomial()).fit() print(model.summary()) # Generalized Linear Model Regression Results # ============================================================================== # Dep. Variable: am No. Observations: 32 # Model: GLM Df Residuals: 29 # Model Family: Binomial Df Model: 2 # Link Function: logit Scale: 1.0000 # Method: IRLS Log-Likelihood: -9.6163 # Date: Thu, 17 Nov 2022 Deviance: 19.233 # Time: 15:59:17 Pearson chi2: 16.1 # No. Iterations: 7 # Covariance Type: nonrobust # ============================================================================== # coef std err z P>|z| [0.025 0.975] # ------------------------------------------------------------------------------ # Intercept -33.6052 15.077 -2.229 0.026 -63.155 -4.055 # mpg 1.2596 0.567 2.220 0.026 0.147 2.372 # hp 0.0550 0.027 2.045 0.041 0.002 0.108 # ==============================================================================[ 일반화 선형 분류 모델 summary 분석 ]
- mpg p-value = 0.026 < 0.05 이므로 feature는 적절한 label을 도출 가능 -> feature 적합성 만족
- hp p-value = 0.041 < 0.05 이므로 feature는 적절한 label을 도출 가능 -> feature 적합성 만족
- 3. 모델 성능 평가
- 해당 모델은 pred_table()을 기능을 제공하지 않아 혼동행렬을 추출할 수 없다.
→ sklearn 라이브러리의 accuray_score() 메소드 사용
📊 분류 모델 평가 지표
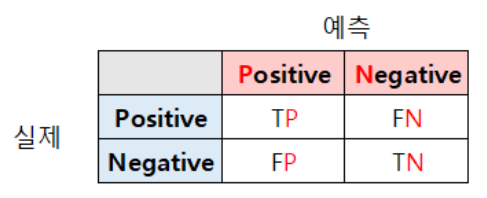
📌 혼동 행렬(Confusion Matrix)
- ⭐ 혼동 행렬
- TP : 참 긍정
- FP : 거짓 긍정
- FN : 거짓 부정
- TN : 참 부정
📌 혼동 행렬을 이용한 평가 지표
- ⭐ 정밀도(Precision)
정밀도 = (TP) / (TP + FP) = (참 긍정) / (예측 긍정)
- 모델이 긍정이라고 예측한 것 중에서 실제 긍정인 비율
- ⭐ 재현율(Recall)
재현율 = (TP) / (TP + FN) = (참 긍정) / (실제 긍정)
- 실제 값이 긍정인 것 중에서 모델이 예측한 긍정이 참인 비율
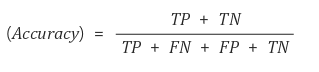
- ⭐ 정확율(Accuracy)
정확율 = (TP + TN) / (TP + FN + FP + TN) = (전체 참 개수) / (전체 개수)
- 전체 개수 중에서 모델이 예측한 결과가 참인 비율
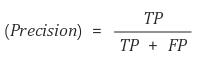
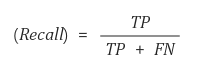
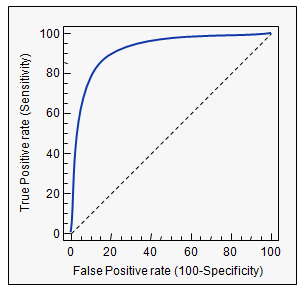
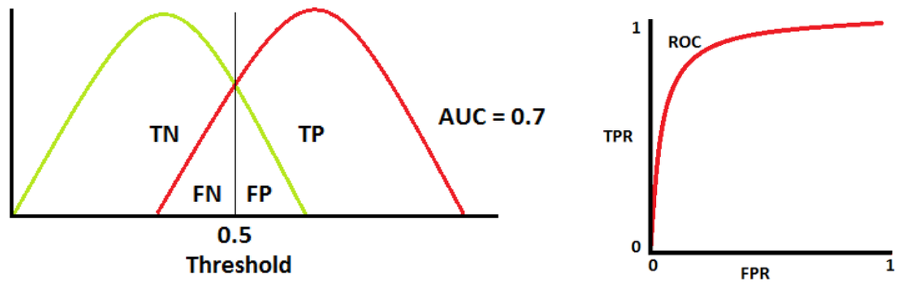
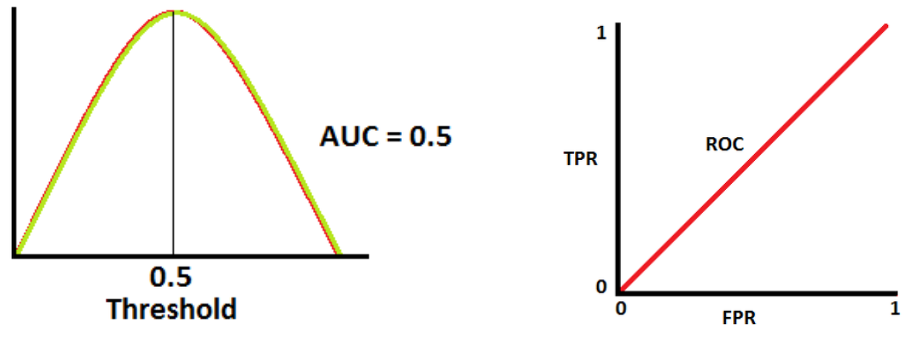
📌 ROC Curve와 AUC 면적
- ⭐ ROC 곡선
여러 임계값들을 기준으로 Fallout 대비 Recall의 변화율을 그래프화 한 것
- ⭐ AUC 면적
AUC (Area Under the ROC Curve)는 ROC Curve의 밑면적을 의미한다.
즉, 성능 평가에 있아서 수치적인 기준이 될 수 있는 값으로, 면적이 1에 가까울수록
그래프가 좌상단에 근접하게 되므로 좋은 모델이라고 할 수 있다.
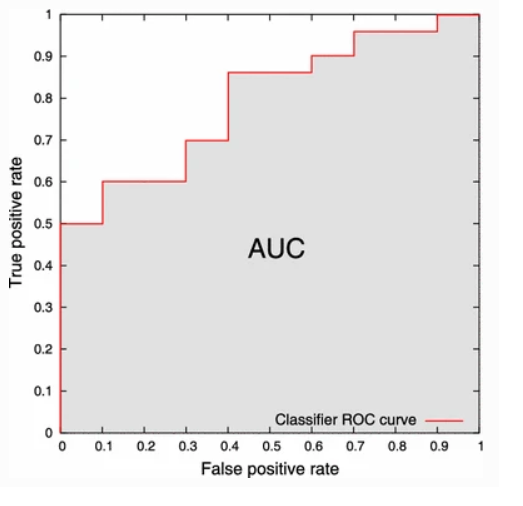
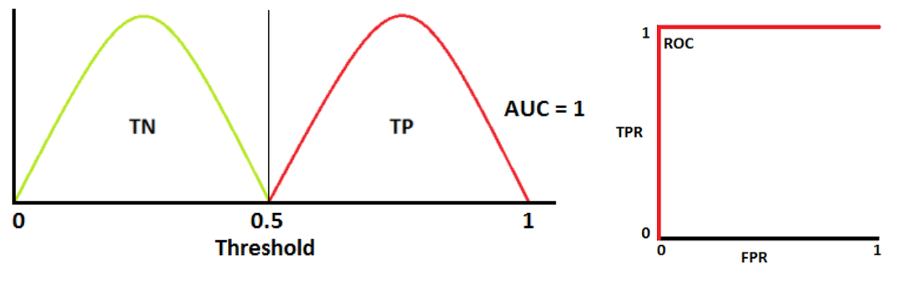
📌 AUC 면적 측정 방법
- AUC = 1
- 양성 클래스와 음성 클래스를 완벽하게 구별할 수 있음
- AUC = 0.7
- 양성 클래스와 음성 클래스를 구별할 수 있는 확률은 70%
- AUC = 0.5
- 양성 클래스와 음성 클래스를 구분할 수 있는 능력이 없음

데이터 사이언티스트를 목표로 하는 개발자