ML and networking
CNN은 이미지등을 구분하기 위해서 사용하는 기법, 네트워크 연관있는것은 시계열 데이터를 분석하고 구할 수 있게 해주는 RNN과 데이터간의 관계성을 중요시하는 Transform기법이 사용된다.
Parallel learning
AI 모델은 얼마나 빠르고, 효율적으로 학습할 수 있냐가 최대 관건이다.
계산 속도를 늘리기 위해서 분산되어있는 GPU를 활용, parallel learning을 수행한다.
동시학습기술..하지만 이떄 학습 이후 데이터를 교환하는 과정에서 network가 병목을 야기시킨다.
대표적으로 다음과 같은 3가지 종류의 parallel learning 존재.

메모리 부족 -> 분산 학습 -> gradient등 parameter 교환 -> 학습 중 너무 많은 양의 gradient 교환 필요, network congestion 발생. 이때 network congestion에 관한 연구 존재.
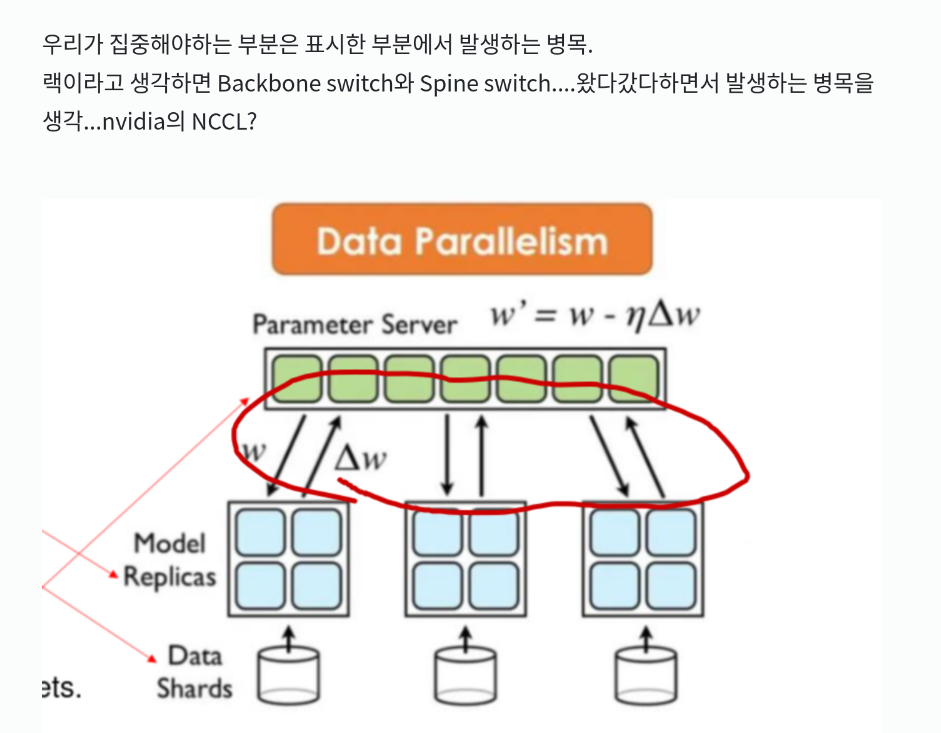
Data parallelism
데이터를 병렬로 처리하는것.

많은 양의 데이터를 smaller chunk로 나누고, 동일한 학습 모델을 사용하는 여러 노드에서 나눠서 처리하도록 만든다.
그후, 각기 나온 gradient를 aggregation하는 과정을 거친다.
문제 1. Synchronization 문제
노드별로 GPU사양이 다를 수 있다. 한놈이 느리면 걔가 끝날때까지 기다려야한다.
문제의 본질: GPU 사양이 다르거나, 특정 노드의 네트워크가 잠깐 튀거나, 심지어 노드 안의 쿨링 팬에 먼지가 껴서 온도가 올라가 쓰로틀링이 걸려도 연산이 느려진다.
결과: 99대의 A100 GPU가 연산을 0.1초 만에 끝내도, 상태가 안 좋은 1대의 GPU가 1초가 걸리면 나머지 99대는 0.9초 동안 전기를 낭비하며 놀아야 합니다. 이를 분산 학습 시스템에서는 'Straggler(지각생) 문제'라고 부른다.
- 해결책: Async-SGD (비동기식 학습)과 Parameter Server
보통 중앙에 모델의 원본 가중치(Weight)를 들고 있는 파라미터 서버(Parameter Server, PS)를 둡니다.
작동 방식: 각 노드(Worker)는 지각생을 기다리지 않습니다. 자기 할당량의 학습이 끝나면 즉시 파라미터 서버로 Gradient를 던져서 원본 모델을 업데이트하고, 업데이트된 최신 모델을 다시 다운받아 다음 학습을 시작합니다.
장점: 쉬는 GPU가 단 한 대도 없습니다. 하드웨어 활용률이 100%에 달합니다.
- 비동기식의 치명적 부작용: Stale Gradient (오래된 기울기)
그런데 이 비동기 방식에는 아주 치명적인 수학적 결함이 있습니다.
상황: 느려터진 1번 GPU가 버전 10(v10)의 모델을 다운받아 열심히 Gradient를 계산하고 있습니다.
지연 발생: 그 사이, 빠릿빠릿한 나머지 GPU들이 이미 수십 번 업데이트를 쳐서 중앙 파라미터 서버의 글로벌 모델은 버전 100(v100)이 되어버렸습니다.
충돌: 뒤늦게 1번 GPU가 v10을 기준으로 계산한 Gradient를 파라미터 서버에 밀어 넣습니다.
결과: 이미 v100까지 진도가 나갔는데, 과거(v10)의 방향성을 현재 모델에 억지로 더해버리니 모델이 엉뚱한 방향으로 튀어버립니다. 이를 Stale Gradient (지연된/오래된 기울기) 문제라고 하며, 모델의 학습 수렴(Convergence)을 박살 내는 주범입니다.
이렇게 동기와 비동기를 하이브리드 형식으로 사용하는 방식 존재.
SSP(Stale Synchronous Parallel): 가장 빠른놈과 가장 느린놈이 일정 수준이상 차이나면, 멈추는 방식
Backup Workers: 100대 중 95대는 속도가 얼추 비슷하지만, 5대는 너무 느리다면, 그 5대의 업데이트는 버리는 방식.
등등이 존재.
- Bandwidth-intensive gradient sharing
우리가 집중해야하는 부분은 표시한 부분에서 발생하는 병목.
이 데이터들은 서버 랙(Rack) 상단의 Leaf 스위치를 거쳐 중앙의 Spine(Backbone) 스위치로 향합니다. 목적지가 '파라미터 서버' 단 한 곳이기 때문에, Spine 스위치에서 파라미터 서버로 내려가는 단일 포트에 상상 초월의 트래픽이 몰리게 됩니다. 스위치의 큐(Queue) 버퍼는 순식간에 터져나가고(Overflow), 패킷 드롭과 재전송이 발생하는 문제가 생긴다.
nvidia 의 NCCL?
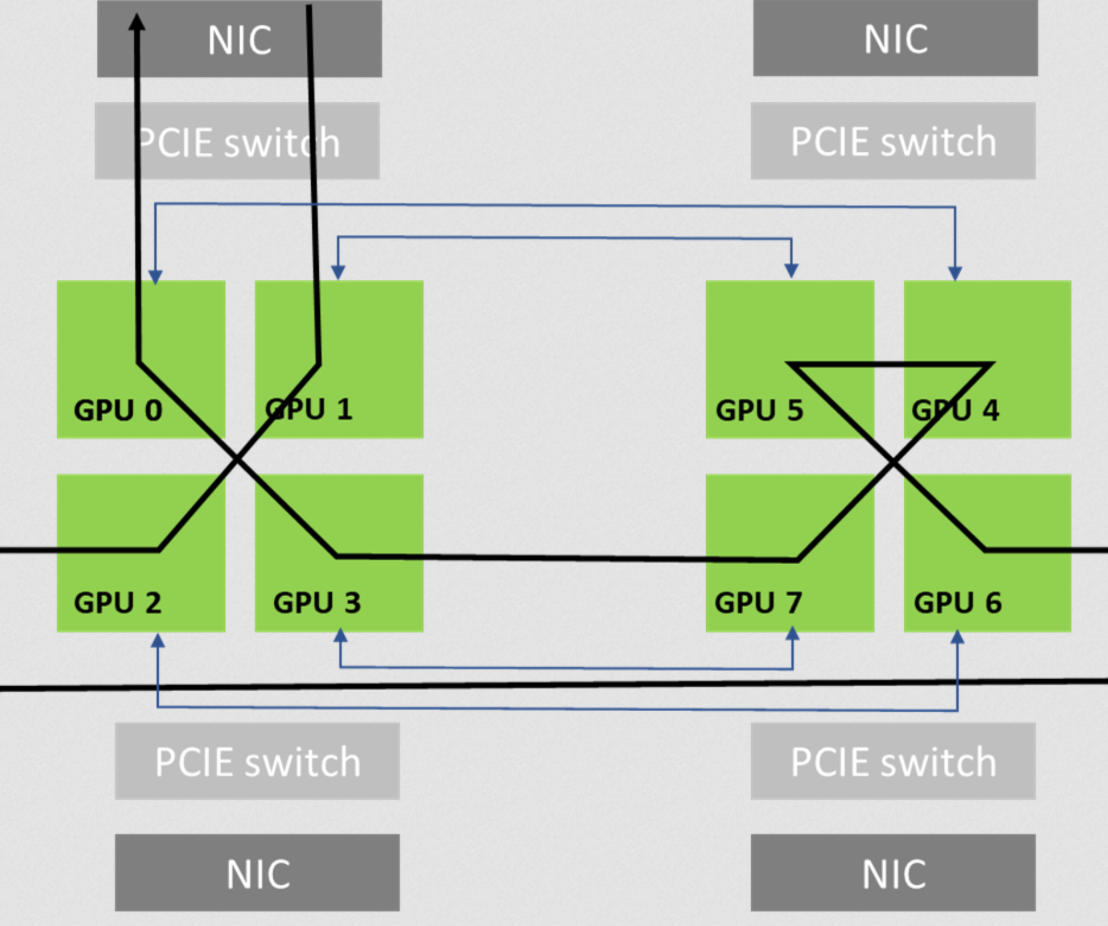
Ring 기반: 각 GPU가 인접한 이웃 GPU와 연결되어 원형으로 데이터를 전달. 대역폭 활용도가 높음.
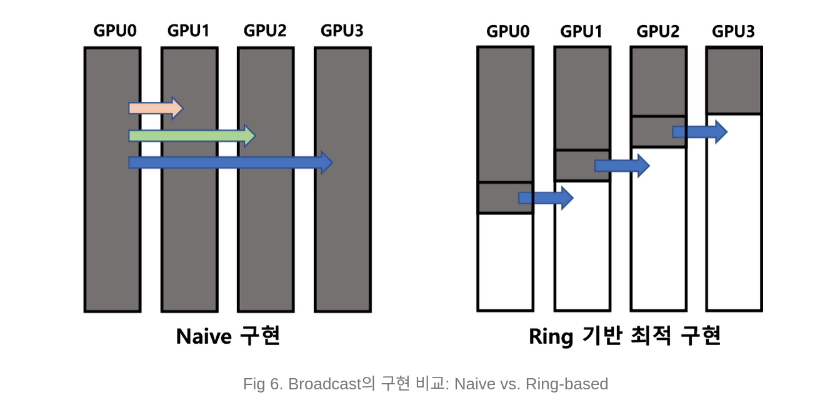
오른쪽 그림은 Ring 기반 최적 구현을 나타낸 것이다. Ring 네트워크 topology와 같이, GPU0은 GPU1로, GPU1은 GPU2로, GPU2는 GPU3으로 데이터를 전송한다. 이때 데이터를 작은 조각으로 나누어 전송한다. 그렇게 한다면 Fig 6.과 같이 모든 GPU가 놀지 않고 데이터 통신에 참여할 수 있게 된다.
기존(Centralized): 모든 노드가 중앙 서버(PS) 한 곳으로 데이터를 쏘면 스위치 포트 하나에 부하가 집중되어 패킷 드롭 발생.
NCCL(Ring): 각 노드는 오직 인접 노드와 1:1로만 통신. 트래픽이 전체 네트워크 링크에 균등하게 분산되어 특정 스위치 포트의 병목을 원천 차단함.
옆 GPU로 데이터를 쏘는 과정은 RDMA를 사용하여 CPU개입없이 copy가 이루어지도록 한다.
Model parallelism
대형 모델을 작은 모델로 쪼개는것.
Layer 많으면 연산이 증가하고, 노드별 연산을 분산하면 학습을 빨리 끝낼 수 있다. 여기서도 노드간 통신이 필수다.
여기서도 마찬가지로 노드간 통신에서의 병목이 발생.
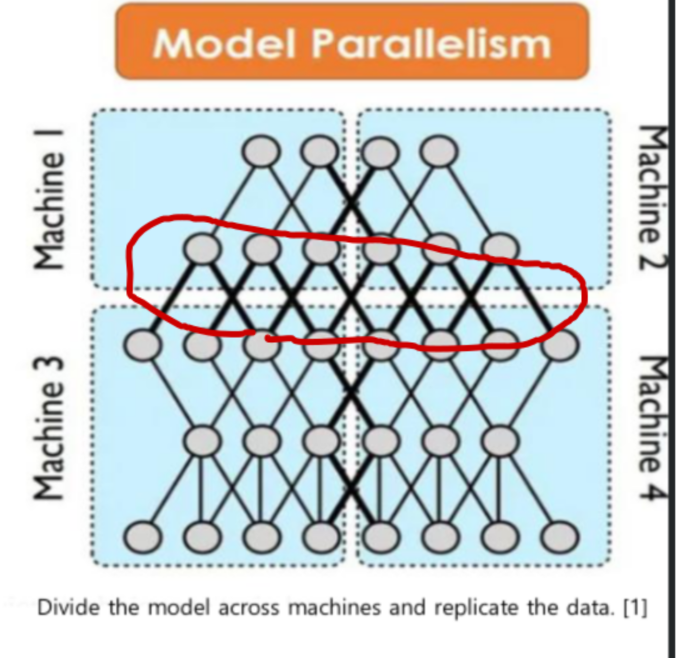
모델 효율(모델 경량화)와 인프라 최적화(노드간의 통신 병목 해결) 둘다 중요.
Pipeline parallelism

여기서 Forward와 Backward propagation 중간에 Worker가 IDLE한 부분이 있는데, 거기를 어떻게 효율적으로 사용할 수 있을것인지 또한 관건이다.
Resource Optimization 가능. 기계 학습시 하나의 데이터 학습하려면 10배의 데이터가 추가적으로 필요하다. memory 제약이 발생.
-> CPU 메모리를 거치지 않고 네트워크 카드(NIC)가 다른 서버의 GPU 메모리(VRAM) 데이터를 직접 읽어온다.
이를 통해 여러 대의 서버에 흩어진 GPU들을 하나의 거대한 Virtual Shared Memory처럼 묶어서 사용할 수 있게 됩니다.
Challenges in Parallel Learning

이중 하나를 프로젝트로 경험해보는것이 제일 중요함.
