
이 시리즈는 Mathematics for Machine Learning의 내용을 번역 및 재해석해서 작성한 글입니다. 이 책의 내용에 이해를 돕는 글을 첨부하였으며 완전한 번역본이 아님을 알려드립니다.
1. Introduction and Motivation
머신러닝의 핵심 요소 : Data, Model and Learning
머신러닝은 데이터로부터 정보를 자동적으로 추출하도록 만든 알고리즘입니다. 자동적 이라는 말에 집중해 봅시다. 이 단어가 중요한 이유는 머신러닝이 다양하고 많은 데이터에 적용할 수 있는 알고리즘을 만든다는 점에서 의미가 있습니다.
머신러닝은 데이터로부터 만들어지기 때문에, 데이터는 머신러닝에 중요합니다. 머신러닝은 다양하고 많은 데이터로부터 잠재된 패턴을 발견하는 것을 목적이 있습니다. 예를 들어, 엄청난 양의 문서에서, 문서들간의 관련 주제를 자동으로 발견하는 것을 머신러닝 방법으로 풀어내기도 합니다. 이를 위해, 주어진 데이터 혹은 알고 있는 데이터를 분석하여 대표적인 속성을 통해 주어진 데이터와 비슷한 결과를 생성하도록 해야 하는데, 이를 모델이라고 합니다. 좋은 모델은 미래에 보지 못한 데이터에 대해 일반적으로 판단 할 수 있는 역할을 할 수 있게 됩니다. 그리고 학습은 모델의 변수들을 최적화 함으로써 데이터와 패턴과 구조를 자동적으로 찾는 것으로 이해할 수 있습니다.
머신러닝의 핵심 요소는 데이터, 모델, 학습입니다.
1.1 Finding Words for Intuitions**
머신러닝을 공부하기 어려운 이유는 개념, 단어는 추상적일 수 있으며 머신 러닝의 특정 부분이 수학적인 개념으로 추상화 될 수 있기 때문입니다. 예를 들어 머신러닝 알고리즘이라는 단어는, 적어도 2가지 의미로 이해될 수 있는데, 첫 번째는, 들어온 데이터로부터 예측을 하는 시스템이라는 의미입니다. 두번째는, 경험하지 않은 데이터에 대해 잘 작동하기 위해, 내부 파라미터들을 조정하는 시스템이라는 의미로 사용하기도 합니다. 물론 여기서, 조정이라는 것은 훈련이라는 뜻입니다.
이 책은 이러한 애매모호함을 해소하지 않지만, 문맥에 따라 같은 표현일지라도 다른 의미를 가질 수 있다는 점을 강조합니다.
이 책에서
-
데이터는 벡터로 간주합니다.
-
확률적 또는 최적화 관점에서, 적절한 모델을 선택합니다.
-
훈련에 사용되지 않은 데이터에 잘 작동하도록 수치최적화된 방법으로 학습합니다.
1.2 Two Ways to Read This Book
-
Bottom-up : 개념과 기초를 다지고 고급 과정을 공부합니다.(Low -> High)
-
Top-down : 고급과정으로부터 잘 모르는 개념을 다지며 공부합니다.(High -> Low)
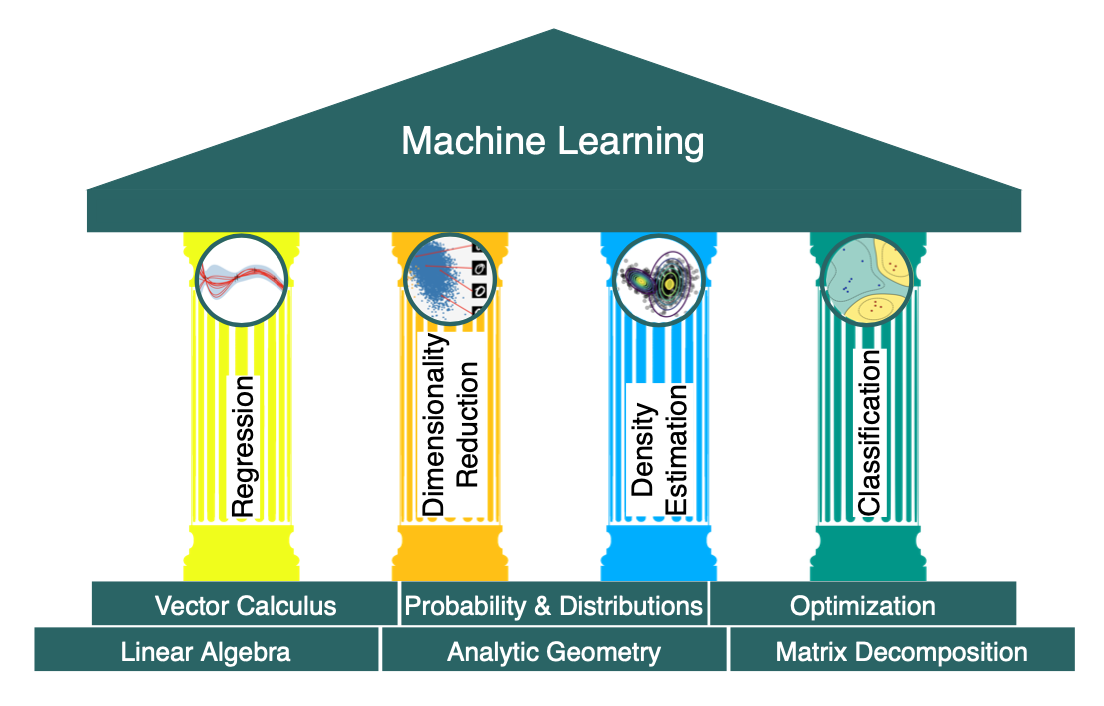
Part 1 - 머신러닝의 기초가 되는 6가지 수학
Linear Algebra(선형 대수학)
수치 데이터를 벡터로 표현하고, 이런 벡터들의 집합(테이블 형태)을 행렬로 표현합니다.
Analytic Geometry(해석 기하)
주어진 2개의 벡터가, 어떤 실제 세계의 2개를 표현한다고 가정해 봅시다. 만약 이 벡터가 유사하다면, 머신러닝 알고리즘을 통한 예측 결과도 비슷해야하지 않을까요? 벡터들의 비슷함을 나타내거나 해석하기 위해서, 해석 기하에서 유사도 또는 metric(distance)와 같은 연산(operation)을 사용하는 과정을 배웁니다.
Matrix Decomposition(행렬 분해)
우리가 15라는 숫자를 15= 3 X 5로 분해할 수 있는 것처럼 행렬들도 분해될 수 있습니다. 이렇게 행렬을 분해함으로써 데이터의 직관적인 해석과 모델의 효율적인 훈련을 도울 수 있습니다.
Probability Theory(확률론)
데이터를 관측하다 보면 잡음 같은 데이터가 섞여있는 것을 볼 수 있습니다. 이러한 잡음을 제거하고 싶을 때, noise의 의미와 노이즈로부터 구분될 수 있는 패턴의 정의를 모델에게 알려주어야 합니다. 또한 불확실성을 표현하고 정량화하는 방법론에 대해 배웁니다.
Optimization(최적화)
훈련하기 위해,성능을 최대화하는 모델의 파라미터를 찾아냅니다.경사(미분)에서, 많은 최적화 기술이 필요로 합니다.
Part 2 - 머신러닝의 4가지 기둥
Regression(회귀)
머신 러닝의 가장 기본적인 예측 모델인 선형 회귀분석을 배웁니다. 주어진 입력값들이 있을 때 예측값(Numerical,Continuous) y로 보내는 함수를 찾는 과정을 다룹니다.
Dimensionary Reduction(차원 축소)
복잡한 데이터를 분석을 쉽게 하기 위한 차원 축소법을 배웁니다. 예를 들어 회사에 지원한 지원자의 역량을 파악하기 위해, 모든 정보가 아닌 주요 정보만 보는 것이 더 효과적이며 시간 측면에서 효율적일 수 있습니다.
Density Estimation(밀도 추정)
데이터를 설명하는 확률 분포를 찾는 과정입니다. 이를 위해 가우시안(Gaussian Mixture)에 집중할 예정입니다.
Classfication(분류)
회귀와 비슷하게 주어진 입력값으로 예측값을 찾는 과정입니다. 다만 이 때의 y는(integer,label)로 불리는 형태를 지닙니다. 이를 위해 SVM에 대해 배웁니다.
Contributor
