
자료구조란?
자료구조란 데이터를 잘 활용하기 위해 체계적으로 관리하는 방법을 정의한 것을 의미한다.
자료구조에 앞서 데이터(data)는 문자, 숫자를 넘어서 음성, 영상에 이르기까지 형태를 지닌 의미 단위로 컴퓨터에서는 프로그램을 운용할 수 있는 형태의 자료 를 의미한다.
이때, 우리가 일련의 숫자 목록을 전송 받았다고 생각해보자.
하지만 그렇게 넘겨받은 숫자의 의미를 알 수 없다면 우리는 해당 숫자를 정확하게 이해거나 활용하기 힘들다.
즉, 데이터는 그 자체만으로 정보를 가지기 힘들고 데이터를 분석하고 정리하여 얻어낸 의미를 통해 활용 할 수 있음을 의미한다.
이처럼, 데이터의 특징을 파악(분석)하여 일련의 방법(자료구조)을 통해 체계적으로 관리하는 것이 데이터를 활용하는 데 있어 유리 하다.
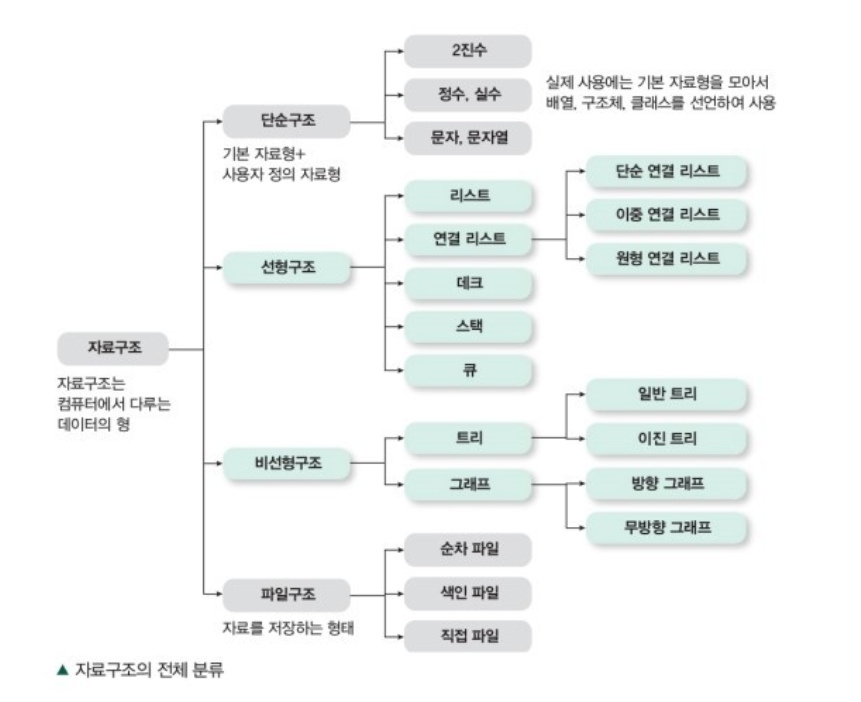
자료구조의 분류
앞서 설명했듯이, 자료구조 또한 선배 개발자 분들의 다양한 시행착오 끝에 탄생하게 된 방법론을 의미한다.
자료구조 시각적으로 알아보기
Data Structure Visualizations
Visualgo
이 중 가장 많이 사용되는 4가지의 자료구조에 대해서 알아보자.
스택(Stack)
Stack은 쌓다, 쌓이다의 의미를 가지고 있다.
이는 데이터를 순서대로 쌓는 자료구조 를 의미한다.
만약, 인덱스가 존재하는 데이터 5개를 Stack 형태로 저장한다고 가정해보자.
<= 입력방향
Data 0 | Data 1 | Data 2 | Data 3 | Data 4 | 입구/출구
=> 출력방향
해당 예시를 통해서 알아볼 수 있는 점은 다음과 같다.
- 자료구조 Stack은 데이터의 입구와 출구가 하나로 이루어지는 제한적 접근 을 특징으로 갖는다.
=> LIFO(Last In First Out) or FILO(First In Last Out)
스택(Stack)의 특징
LIFO(Last In First Out)의 구조를 가진다.
이러한 특성으로 Stack 구조는 조회가 필요하지 경우, 해당 자료구조를 통해 데이터를 저장하고 검색하는 프로세스가 매우 빠르고 최상위 블록에서 데이터를 저장하고 검색하면 된다는 장점을 가진다.
한번에 한 개의 Data만 다룰 수 있다.
Stack 구조는 한 개의 Data씩 넣고 뺄 수 있다. 한꺼번에 여러개의 Data를 연산할 수 없다.
하나의 입출력 방향을 가지고 있다.
Stack 구조는 데이터의 입출력 방향이 같다.
만약, 입출력 방향이 다른 경우 Stack 구조라고 볼 수 없다.
저장되는 데이터는 유한하고 정적이어야 한다.
이는 Stack 구조를 사용한 Call Stack을 예시로 들 수 있다.
Call Stack 내부의 함수 실행 데이터는 Stack의 Frame 단위로 저장되게 된다.
이때, 각 Frame은 해당 기능에 필요한 Data가 저장되는 공간(블록)을 의미한다.
예를 들어, 함수가 새로이 변수를 선언할 때 해당 데이터는 Stack의 최상위 블록으로 저장되게 된다.
이후, 다음 함수가 실행되게 될 때 최상위 블록은 새롭게 들어오는 데이터로 변경되게 된다.
즉, 저장되는 데이터가 정적이어야만 Stack의 컴파일 시간이 결정될 수 있고 저장되는 데이터의 타입에 의한 크기가 고정되어 빠른 실행 시간을 보장할 수 있다.
Stack의 크기는 일반적으로 제한된다.
대부분의 언어에서 Stack은 heap에 의해 크기가 제한되어 있으므로, Stack의 크기가 제한되지 않은 경우 Stack Overflow가 발생 할 수 있다.
스택(Stack)의 실사용 예제
앞서 스택(Stack)의 특징을 살펴본 결과, 스택은 입력방향과 데이터의 타입(크기, 정적 등등)을 고정함으로써 빠른 실행 속도를 보장 할 수 있다.
하지만, 스택(Stack)내의 Data에 인덱스와 같은 labeling을 하지 않기에 특정 데이터를 탐색하는 조회와 같은 기능은 수행할 수 없다.
즉, Data의 조회없이 순차적으로 빼거나 넣는 형태만을 사용하는 경우 스택(Stack) 구조를 사용할 수 있다.
대표적 예시로, 브라우저의 뒤로가기/처음으로 기능을 들 수 있다.
브라우저에서 Stack 구조를 통해 해당 기능을 실행하는 순서는 다음과 같다.
1) 새로운 페이지로 접속할 때 이전 페이지를 Stack에 보관한다.
2) 뒤로가기 버튼을 누르는 경우 Stack에 저장된 가장 마지막 페이지를 불러오고, 기존 페이지를 Stack에 저장한다.
3) 처음으로 버튼을 누르는 경우 Stack의 데이터를 모두 비워 처음으로 저장된 페이지를 불러오고, 기존 페이지를 Stack에 저장한다.
이렇듯, 특정 페이지를 불러오는 것이 아닌 스택에 저장된 가장 첫 데이터 혹은 마지막 데이터를 불러오는 형태에서 빠른 실행 속도를 보장 할 수 있다.
큐(Queue)
큐(Queue)는 대기 행렬이라는 뜻을 가지고 있다.
이는 데이터가 들어오는 순서대로 처리되는 구조 를 의미한다.
만약, 인덱스가 존재하는 Data 5개를 큐(Queue)구조로 저장한다고 가정해보자.
<= 입력방향
출구 | Data 0 | Data 1 | Data 2 | Data 3 | Data4 | 입구
<= 출력방향
즉, 큐(Queue) 구조는 Stack과는 반대로 먼저 들어온 Data가 먼저 나오는 FIFO(First In First Out) 를 특징으로 가진다.
큐(Queue)의 특징
FIFO(First In First Out)
먼저 들어간 데이터가 가장 먼저 나오는 선입선출의 구조 를 가지고 있다.
Data는 한번에 한 개만 처리할 수 있다.
두개의 입출력 방향을 가지고 있다.
Queue 자료구조는 데이터의 입력, 출력 방향이 상이하다.
만약, Stack 처럼 입출력 방향이 같다면 Queue 자료구조라고 볼 수 없다.
큐(Queue)의 사용예시
큐(Queue)의 가장 큰 특징은 FIFO에 있다.
즉, 데이터가 들어온 순서대로 처리되는 경우 큐(Queue) 자료구조 를 사용할 수 있다.
대표적인 예시로, 프린터의 인쇄 기능을 들 수 있다.
프린터 소프트웨어에서 프린터의 인쇄 기능은 다음과 같은 순서로 동작한다.
1) 문서 출력 버튼을 누를 시 해당 문서의 Data가 Queue에 저장된다.
2) 여러건의 문서를 출력할 시 Queue내 출력 명령이 들어온 순서대로 저장된다.
3) 프린터는 저장된 Data의 순서대로 인쇄한다.
이때, Queue는 컴퓨터의 장치들 사이에서 Data를 주고 받을 때 발생하는 속도의 차이(Buffering)을 해결하기 위해 주로 사용 된다.
예시에서 프린터는 컴퓨터의 인쇄 명령보다 느린 속도로 인쇄 작업을 수행하게 된다.
따라서, 컴퓨터는 프린터의 인쇄에 필요한 Data를 Queue에 저장해두고 다른 작업을 수행한다.
또한, 프린터는 인쇄 작업이 끝날 시 Queue에 저장된 다음 인쇄 작업을 순차적으로 수행한다.
- 순서가 불규칙적인 비동기 방식을 의도대로 처리하기 위해 동기 방식을 사용하는 것과 같다.
