[논문리뷰] MAST: Multimodal Abstractive Summarization with Trimodal Hierarchical Attention
Multimodal

Abstract
본 논문은 text, audio, video의 세 가지 모달리티로부터 정보를 활용하는 Multimodal Abstactive Text Summarization을 위한 새로운 모델 MAST를 소개한다. Multimodal Abstactive Text Summarization에 관한 이전 연구에서는 text와 video 모달리티만을 활용했다. 본 논문 저자들은 text modality에 attention을 더 줌으로써 audio modality로 부터 정보를 얻는 어려움을 해결하는 sequence-to-sequence Trimodal Hierachical Attention based model을 소개한다.
Introduction
multimodal text summarization이란 교차 모달리티의 정보에서 요약을 생성하는 task이다. large-scale multimodal language인 How2 dataset이 소개되고, 해당 dataset으로 multimodal abstractive text summarization에서 SOTA model이 만들어졌다. 해당 모델은 sequence-to-sequence hierarchical attention를 기반으로 하여 text와 image feature만을 활용한다.
아직 abstractive multimodal text summarization 분야에서 audio feature를 결합하는 효과를 포착하지 못했기 때문에 본 논문은 solution의 일부로서 audio modality를 도입하는 것의 이점과 어려움을 조사하여 결점을 개선한다.
본 논문은 모델이 특정 어조의 톤이나 강도로 말하는 단어에 더욱 attention을 주도록 함으로써 audio modality가 text summarization task에 대해 추가적인 유용한 정보를 제공할 것이라고 가정한다. 실험을 통해 모든 모달리티가 output에 동일한 기여를 하는 것이 아님을 알 수 있었으며 text의 기여가 큼을 증명할 수 있었다. (text>video>audio) 이는 output summary를 생성하는 동안 text input에 더욱 중요도를 주는 MAST model의 동기가 되었다.

위의 결과에서 알 수 있듯이 MAST model이 생성한 summary가 더욱 설명적인 요약문임을 알 수 있다. 본 논문의 기여점을 정리하면 다음과 같다.
Contributions
- abstractive multimodal text summarization에 audio modality를 도입하였다.
- audio 정보를 활용하고 생성된 summary에 대한 audio feature의 기여를 이해하는 것의 어려움을 조사하였다.
- multimodal abstractive text summarization분야에서 SOTA model인 MAST를 제안하였다.
Methodology
1. Dataset
open-domain videos인 How2 dataset의 300h version을 사용했다. 해당 데이터셋은 요리, 스포츠, 실내/외 활동, 음악 등과 같은 다양한 영역에 걸친 약 300시간의 짧은 교육 비디오로 구성되며, 각 영상마다 사람이 만든 스크립트와 2-3줄의 요약문이 존재한다. Train set 12,798, Validation set 520, Test set 127개의 videos를 활용하였다.
2. Modalities
- Audio
40 dimensional Kaldi filter bank feautures와 3 dimensional pitch features를 concat하여 43 dimensional audio features의 final sequence를 얻는다. - Text
각 비디오에 대응하는 스크립트를 사용한다. 모든 text는 정규화되고 소문자로 바꿔준다. encoder로 GRU를 활용한다. - Video
ResNeXt-101 3D CNN을 사용하여 비디오로 부터 추출된 2048 dimensional feature vector(per group of 16 frames)를 사용한다.
3. Multimodal Abstractive Summarization with Trimodal Hierarchical Attention
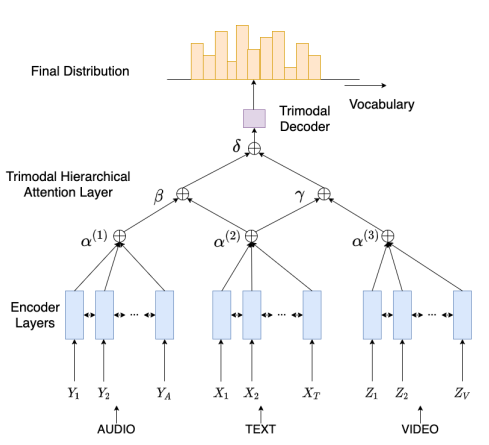
Modality Encoders
text는 bidirectional GRU encoder로, audio와 video feature는 bidirectional LSTM encoder로 인코딩된다. 각 encoder의 timestep에서 모든 모달리티에 대응하는 각각의 output encoding이 출력된다.
Trimodal Hierarchical Attention Layer
모달리티를 조합하기 위해 hierarchical attention 접근법을 활용하였다. 각 decoder의 timestep에서 attention 분포 ()와 k번째 모달리티에 대한 context vector는 독립적으로 계산된다.
-
TrimodalH2
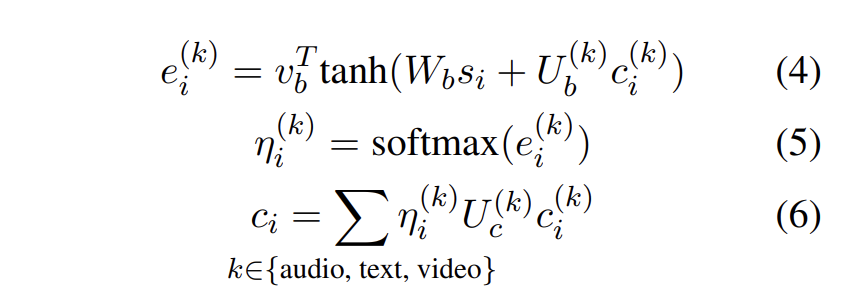 2 level attention hierarchy 구조를 가진 baseline 모델이다. 세가지 모달리티에 대한 context vector는 attention mechanism의 두번째 layer를 통해 조합되며, 그 context vector는 hierarchical attention 조합을 사용함으로써 각각 계산된다.
2 level attention hierarchy 구조를 가진 baseline 모델이다. 세가지 모달리티에 대한 context vector는 attention mechanism의 두번째 layer를 통해 조합되며, 그 context vector는 hierarchical attention 조합을 사용함으로써 각각 계산된다. -
MAST
 audio-text, text-video에 대한 context vectors는 hierarchical attention mechanisms ()의 두번째 layer를 사용하여 조합되었으며, 독립적으로 계산되었다. 이 context vector들은 세번째 hierarchical attention mechanism()를 사용하여 조합된다.
audio-text, text-video에 대한 context vectors는 hierarchical attention mechanisms ()의 두번째 layer를 사용하여 조합되었으며, 독립적으로 계산되었다. 이 context vector들은 세번째 hierarchical attention mechanism()를 사용하여 조합된다.
따라서 모델 구조에 의해 textual modality는 다른 두개의 modality와 두 번 조합되며, 이것이 다른 두 modality의 이점을 통합하는 동시에 textual modality에 더 attention을 줄 수 있게 한다.
Trimodal Decoder
GRU-based conditional decoder를 사용하였다. 각 timestep에서 decoder는 모든 modality로 부터 통합 정보를 가진다. trimodal decoder는 modality 조합에 집중하였고, 이후에 개별적인 모달리티는 내부적으로 특정한 정보에 집중한다. 최종적으로는 이전 timestep으로 부터의 정보와 현재 정보를 함께 사용한다.
Experiments
Challenges of using audio modality
1. To obtain a good representation of the audio modality
DNN acoustic model은 시간과 빈도 측면에서 부드럽게 변화하는 features를 선호한다. 본 실험에서는 MFCC 대신에 MFSC features와 filter bank featuers를 사용하였다.
2. Larger number of parameters for audio information
Video-Text baseline에서 Audio가 추가되면 파라미터 수가 2배가 된다. 이는 learning reickier와 더 많은 시간 소비를 유발하는 audio modality encoder에 너무 많은 input timestep이 존재하기 때문이다.
3. Solution
audio features를 input time에 걸친 audio features를 30개의 연속적인 timesteps의 평균을 가진 bin으로 그룹하여 MAST model을 학습시켰다. 따라서 audio timestep 수가 ideo & text timestep의 수와 비슷해졌고, 그 결과 연산량의 측면에서는 효율성을 봤으나 성능은 Video-Text model보다 더 낮게 나타났다. (MAST-Binned) Audio only와 Audio-Text 또한 Text only 보다 낮은 성능을 보였다. Audio only의 생성 요약문이 비슷하고 반복적이기 때문에 관련 높은 정보를 학습하는데 실패함을 나타낸다.
Results and Discussion
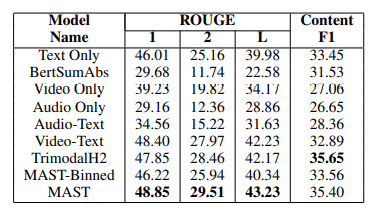
About Model Name
- Text only, Video only, Audio only : attention-based S2S models
- BertSumAbs : Bert based model
- Audio-Text, Video-Text : S2S models with hierarchical attention layer
- TrimodalH2 : add the audio modality in second-level of hierarchical attention
- MAST-Binned : groups the audio featues
1. Discussion
Text only, Audio-Text, Video-Text의 score로 보아 text modality가 최종 요약문과 관련된 가장 많은 양의 정보를 포함하고 있음을 알 수 있다. transformer 기반 모델인 BertSumAbs는 text data의 양이 너무 적어 좋은 성능을 보이지 못했다. text와 audio modality의 조합은 ROUGE score가 Text only보다 낮은데, 이는 hierarchical attention model이 audio modality 자체를 잘 학습하지 못함을 의미한다. TrimodalH2 model의 결과에서도 알 수 있다.
2. Usefulness of audio modality
MAST와 TrimodalH2 models는 Video-Text baseline보다 Content F1 score가 더 높고, 이는 모델이 audio modality의 정보를 활용함으로써 더 유의미한 내용을 추출하도록 학습했음을 할 수 있다. 하지만 TrimodalH2 model은 Video-Text ROUGE score를 넘기지 못했다. MAST model은 text modality에 attention을 더 주면서 TrimodalH2의 단점을 극복하고 더 좋은 ROUGE score를 달성했다.
3. Attention distribution across modalities
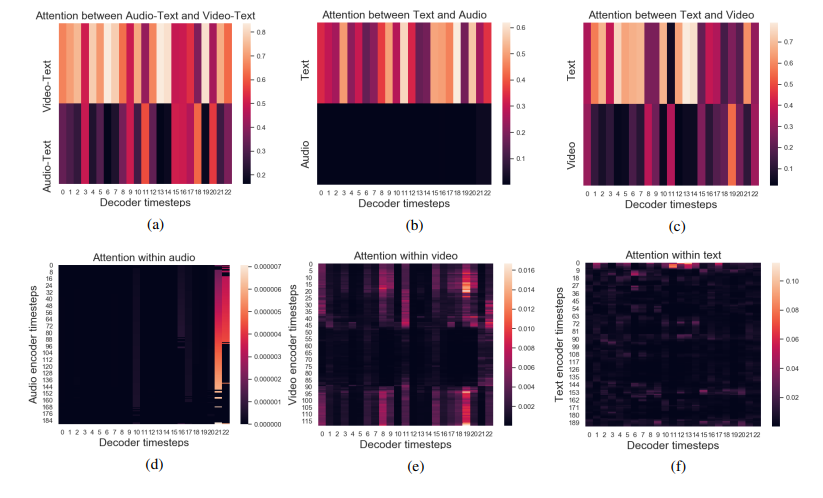
본 저자는 각 modality와 그 조합의 중요도를 보기 위해, decoder timestep의 다른 levels of attention hierarchy에서 attention plot을 그렸다. 위 결과를 통해 audio와 video modality에는 attention을 덜 주는 반면, text modality가 요약문 생성에 강하다는 것을 알 수 있다. 이러한 결과는 MAST model의 text modality가 다른 모달리티와 상호 작용하는 동안이 더욱 중요함을 뒷받침한다. 그림 4(b)와 4(d)는 audio modality를 통한 약간의 이득과 적절한 사용의 어려움을 강조한다.
Conclusion
본 논문은 audio, text, video 세 가지 모달리티를 전부 사용하여 abstractive multimodal text summary 분야에서 SOTA를 달성한 s2s based model인 MAST를 소개했다. MAST는 Trimodal Hierarchical Attention layer를 사용한다. 본 저자는 audio modality를 더함으로써 역할을 탐색하고 MAST model의 효율성을 입증한다.
