- 클래스 당 500장 + augmentation = 약 13800 장 데이터셋으로 yolov5n과 yolov5s 모델을 각각 다른 epoch로 훈련 하여 mAP 테이블 작성한 결과, augmentation을 한 데이터셋에서는 mAP가 꾸준히 오르는 것을 확인하였음.
mAP 테이블을 다 작성한 후 진행 중인 것.
- 최종 프로젝트의 목표가 jetson nano와 웹캠을 활용한 알약 인식인 만큼 yolo를 학습하기 위한 데이터셋에 스마트폰이 아닌 웹캠으로 촬영한 알약의 이미지를 추가하기 위한 사전 작업 중에 있음(클래스 당 200장)
- yolov5가 알약을 잘못 인식했을 경우를 대비해 confidence score를 내림차순으로 정렬하여 텍스트 파일에 저장하기(class number, confidence score)
- 웹캠으로 촬영한 알약의 각인을 ocr이 잘 읽는지 확인하고, 개선 작업.
내가 맡은 파트는 yolov5의 class와 해당 confidence score를 내림차순으로 정렬하여 ranking 같은 효과를 낼 수 있도록 하는 것이었고, 5월 27일 금요일부터 detect.py와 general.py 코드를 분석하기 시작하였음.
yolov5의 detect.py와 general.py 분석해보기
(팀원 분들의 도움이 있었지만 급하게 공부하고 구현한 부분이라 대부분 정확한 정보라고 말하기는 어렵습니다. 틀린 부분은 말씀해주세요!)
사실 전체를 다 분석한 것은 아니고, prediction 후 생성된 bbox들 중 가장 높은 confidence를 기록한 bbox 하나만 남기는 NMS(Non-Maximum-Suppression) 부분만 분석하였다.(그래서 다른 부분은 모르고, 심지어 prediction을 어디서 하는지도 잘 모름...)
나름대로 분석한 것을 정리하자면, 처음 생각은 prediction해서 생긴 다수의 bbox를 처리하는 NMS에서 가장 높은 confidence score를 가진 클래스만 저장하고 다른 클래스는 저장하지 않으니까, 이 부분에서 따로 모든 클래스에 대한 confidence score를 받아오면 되지 않을까 하는 생각으로 접근했다.

이 부분에서 예측한 결과를 NMS 함수에 넘겨주는 것을 확인하고, non_max_suppression 함수가 있는 util/general.py를 보기 시작함.
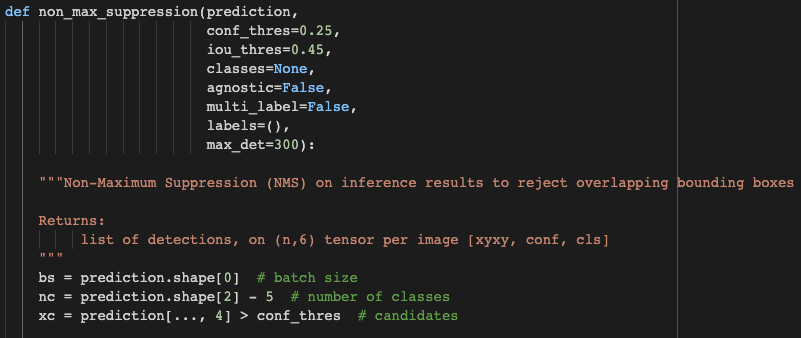
general.py의 non_max_suppression 함수이다. 인자로 prediction과 conf_thres, iou_thres 등을 넘겨주고, prediction.shape의 각 원소를 bs(batch size), nc(number of classes), xc(candidates)로 나누어 준다. 나누기 전에는 이미지 마다 수치의 차이는 있지만, (batch, number of bbox, features)로 이루어져 있다.
nc에서 prediction.shape[2]에 -5를 해주는 이유는 텐서를 구성하는 'features'를 확인해보면 알 수 있는데, 0, 1, 2, 3은 각각 x_center, y_center, width, height이고, 4에는 obj_conf 값이 들어가 있다. 즉, 앞의 다섯개를 빼고 나머지가 클래스이다. 우리 프로젝트의 경우 10개 약을 대상으로 진행하므로 10개 클래스임.

confidence를 계산하는 부분. x 텐서 각각 5번째부터 끝까지를 4번째 원소와 곱한다. 사실 개선 사항에 넣을 예정이지만 yolo가 인식한 클래스의 확률과 내가 뽑아본 수치가 다르다. 내 생각에는 obj_conf가 곱해지지 않았기 때문인 것 같은데, 지금 수정을 당장 하지 않은 이유는 중요한 건 순위를 출력하는 것이고 정확한 수치가 필요한 것이 아니라 각 수치의 크기를 비교하기만 하면 되기 때문이다. 지금은 시간이 부족하지만 프로젝트가 끝나고 나면 정확하게 원인을 분석해야 할 것 같다.
당장의 목표는 detection은 기존 yolov5의 형태로 출력하고 저장하되, 따로 각 클래스의 confidence score를 뽑아내는 것임.
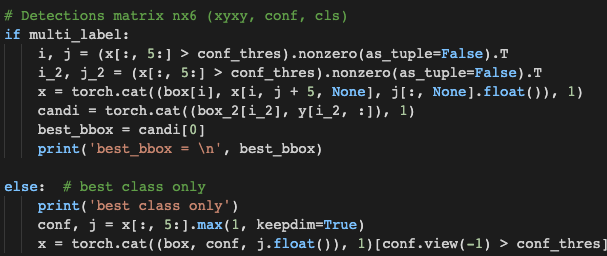
앞 뒤로 다 읽어본 결과 위 부분에서 가장 높은 confidence만 남기는 것을 확인했다. 처음에는 multi label이 아니니 else: 부분이 실행될 것이라고 생각하고 해당 부분을 계속 수정해보고 리턴 값으로 받아 출력해봤는데, 여기가 아니라 multi label이 실행된다. 그렇게 생각한 이유는,
- else: 안에서 작성한 print문이 실행되지 않음.
- 또한 변수를 선언해서 리턴값으로 받았는데 리턴이 되지 않음.
위 두 가지 이유로 multi label이 실행되는 것이라고 생각했고, 실제로 그랬다.
multi_label 조건문 안에서 같은 수가 저장된 변수들을 한 번 더 만들었음(이유는 모르겠다..하다보니 저렇게 됨. 나중에 수정해보겠음.)
x에는 기존 nms task를 위해 원래 형태 그대로의 코드이고, 나는 전체 클래스에 대한 각각의 confidence 값을 받기 위해 candi 변수에 따로 저장하였다. 그리고 그 중 가장 첫 번째를 best_bbox에 저장함. 이전 코드에서 정렬이 되는 듯(확실하지 않음. 추후 확인 예정). 이후 best_bbox를 리턴.
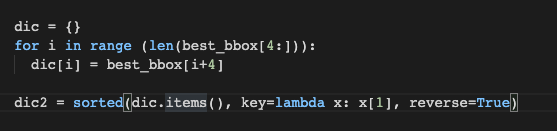
best_bbox를 딕셔너리에 저장하여 내림차순으로 정렬한다.

detection 정보에 이어서 텍스트 파일에 저장!
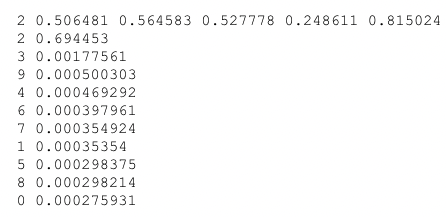
일단 yolo가 예측한 클래스가 confidence score를 뽑아본 결과의 가장 위에 위치해 있는 걸로 보아 각각의 confidence score가 맞는 것 같다. 하지만 bbox를 통해 저장된 0.815024와 내가 뽑아본 2번 클래스의 confidence score인 0.694453이 각각 다르다. 방금 언급한 obj_conf를 곱해주지 않았을 수도 있고, 또는 best_bbox에 저장할 때 단순하게 정렬이 됐다고 생각하고 candi에 저장된 첫번째 bbox가 사실은 best_bbox가 아니었을 수도 있을 것 같다. 이후 다시 시도해봐야할 것 같다.
22.05.31 수정
- 위 텍스트 파일에서 클래스에 대한 confidence가 각각 0.815024, 바로 아래 1위 confidence가 같은 2번 클래스이지만 0.694453으로 다른 이유는 가장 높은 confidence score를 가진 bbox가 아니어서였다. 그래서 후보 bbox들을 내림차순으로 정렬하여 가장 높은 confidence score를 가진 bbox를 다시 저장하여 수행하였다. 그 결과,
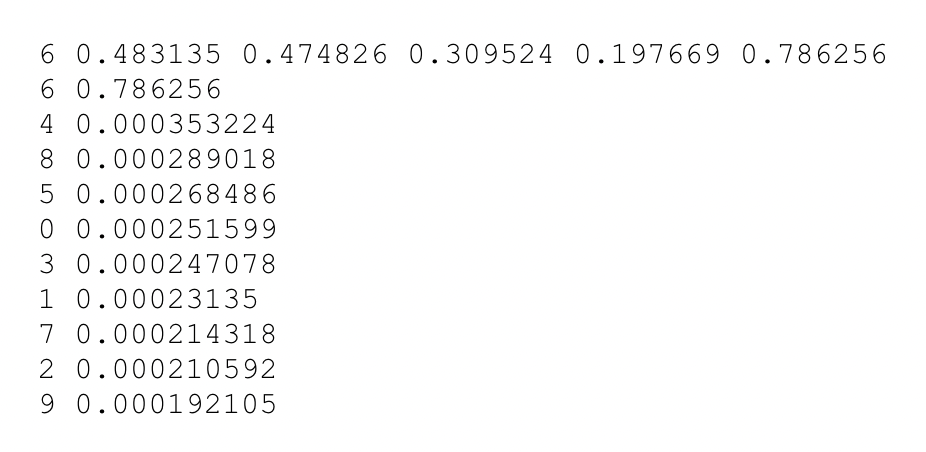
score가 잘 맞게 나온다.
6번 클래스는 EZn6_Any로 정답 라벨과 yolov5가 예측한 결과가 일치한다.

이 이미지를 OCR 모델로 넘겨주기 위해 crop하여 저장한다.

앞으로 해야할 일
1. 웹캠으로 촬영한 알약 이미지로 데이터셋을 늘려 학습하기
2. 다른 파트 팀원 돕기
