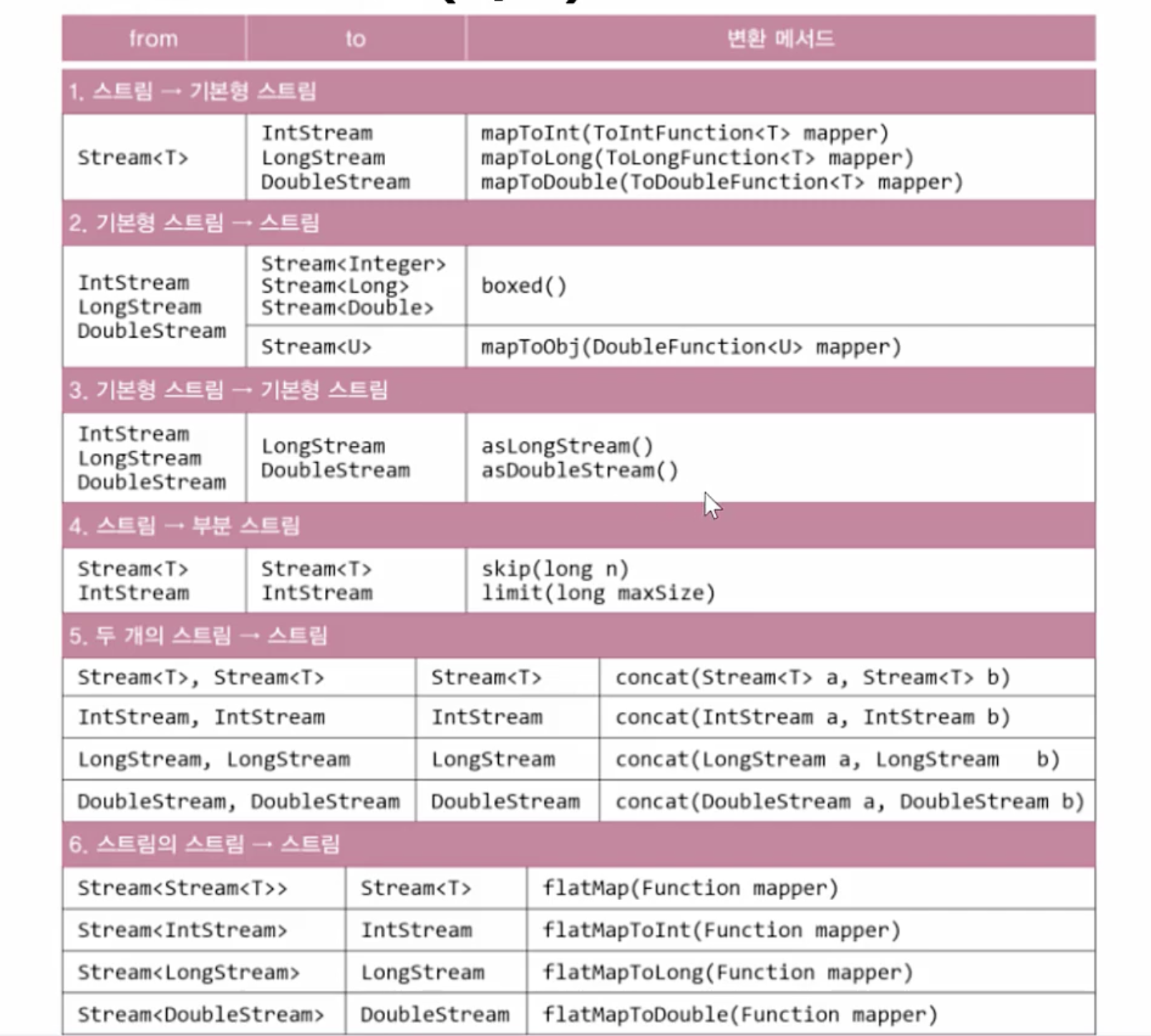
ch-14 36~39 Optional< T >
t 타입의 객체의 래퍼클래스(integer,lone etc..) - Optional< T >
간접적으로 null 다룸
public final class Optional<T> {
private final T value; // T타입의 참조 변수
...
}사용 이유
- null을 직접다루는 것은 위험(NullPointerExcpetion)
- null체크는 if문으로 하기에 코드가 지저분 해짐
// 반환 값은 null & 객체
Object result = getResult();
if(result != null)
System.out.println(result.toString());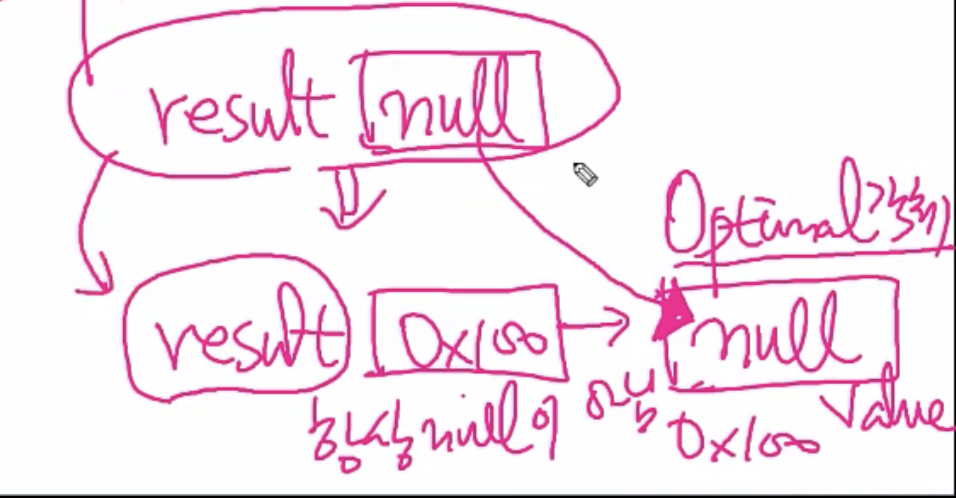
result의 값이 null이더라도 주소가 출력됨!!!!
Optional 객체 생성
String str = "abc";
Optional<String> optVal = Optional.of(str);
Optional<String> optVal = Optional.of("abc");
Optional<String> optVal = Optional.of(null); //NullPointerException
// 참조변수값이 null일 가능성이 있으면 of 대신 ofNullable() 사용
Optional<String> optVal = Optional.ofNullable(null);
// 초기화 시에는 null 보다 empty 사용(String 생략 가능)
Optional<String> optVal = Optional.<String>empty();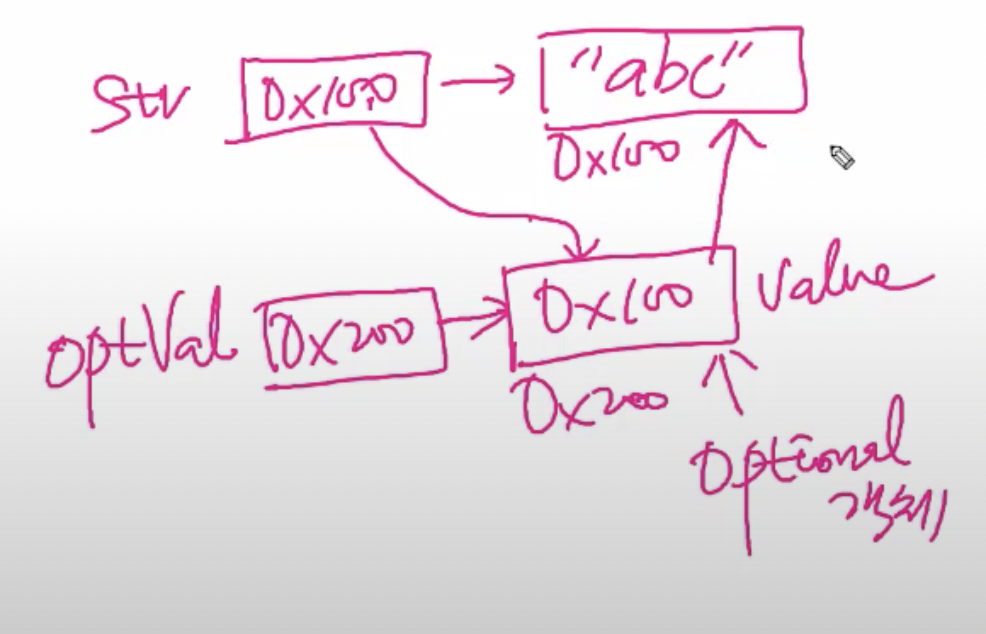
Optional 객체 값 가져오기
Optional<String> optVal = Optional.of("abc");
String str1 = optVal.get(); // optval에 저장된 값 반환, null 이면 예외발생
String str2 = optVal.orElse(""); // optval에 저장된 값이 null일땐 "" 반환
String str3 = optVal.orElseGet(String::new); // 람다식 사용 가능 () -> new String()
String str4 = optVal.orelseThrow(NullPointerException :: new) // 널이면 예외 발생 // 예외종류 지정 가능isPresent()
Optional객체의 값이 null이면 false 반환
if(Optional.ofNullable(str).isPresent(){
// if(str!=null)
System.out.println(str);
}OptionalInt, OptionalLong, OptionalDouble
기본형 값을 감싸는 래퍼클래스(Optional< T > 도 가능하지만 성능때문에 사용)
public final class OptionalInt{
...
private final boolean isPresent; // 값이 저장되어 있으면 true
private final int value; // int 타입의 변수(참조형이 아닌 기본형)
}
OptionalInt의 값을 가져올때는 int getAsInt(), long getAsLong(), double getAsDouble()등의 메서드를 사용
//둘다 0을 저장(empty 시에도 OptionalInt의 코드를 보면 value 초기 값이 0 이기 때문)
// 이를 구별하기 위해 isPresent 또한 정의되어 있음
OptionalInt opt = OptionalInt.of(0);
OptionalInt opt2 = OptionalInt.empty();
System.out.println(opt.isPresent()); //true
System.out.println(opt2.isPresent()); //false
System.out.println(opt.equals(opt2)); //falsepackage ch14;
import java.util.*;
public class Ex14_8 {
public static void main(String[] args) {
Optional<String> optStr = Optional.of("abcde");
// String:: length == s->s.length()
Optional<Integer> optInt = optStr.map(String::length);
System.out.println("optStr =" + optStr.get());
System.out.println("optInt =" + optInt.get());
int result1 = Optional.of("123")
.filter(x->x.length() > 0)
.map(Integer::parseInt).get();
int result2 = Optional.of("")
.filter(x->x.length() >0)
.map(Integer::parseInt).orElse(-1);
System.out.println("result1 ="+result1);
System.out.println("result2 ="+result2);
Optional.of("456").map(Integer::parseInt).ifPresent(x->System.out.printf("result3=%d%n", x));
OptionalInt optInt1 = OptionalInt.of(0); // 0저장
OptionalInt optInt2 = OptionalInt.empty(); // 빈객체 생성
System.out.println(optInt1.isPresent()); //true
System.out.println(optInt2.isPresent()); //false
System.out.println(optInt1.getAsInt()); // 0
// System.out.println(optInt2.getAsInt()); // NoSuchElementException
System.out.println("optInt1="+optInt1);
System.out.println("optInt1="+optInt2);
System.out.println("optInt1.equals(optInt2)?" + optInt1.equals(optInt2));
}
}
optStr =abcde
optInt =5
result1 =123
result2 =-1
result3=456
true
false
0
optInt1=OptionalInt[0]
optInt1=OptionalInt.empty
optInt1.equals(optInt2)?false
ch-14 40~45 스트림 최종 연산
forEach()
스트림의 모든 요소에 지정된 작업을 수행
void forEach(Consumer<? super T> action) // 병렬 스트림의 경우 순서 보장 X
void forEachOrdered(Consumer<? super T> action) // 병렬스트림인 경우에도 순서 보장//123456789
// sequential은 직렬 스트림 -> 생략 가능
IntStream.range(1,10).sequential().forEach(System.out::println);
IntStream.range(1,10).sequential().forEachOrdered(System.out::println);
IntStream.range(1,10).parallel().forEachOrdered(System.out::println);
//6883295714 (순서 뒤죽박죽)
IntStream.range(1,10).parallel().forEach(System.out::println);allMatch(),anyMatch(),noneMatch()
스트림의 요소에 대해 지정된 조건에 모든 요소가 일치하는지, 일부가 일치하는지, 어떤 요소도 일치하지 않는지 확인할 때 사용하는 메서드
매개변수 : Predicate , 반환값 : boolean
boolean allMatch (Predicate<? super T> predicate) // 모든 요소가 일치하면 참
boolean anyMatch (Predicate<? super T> predicate) // 하나의 요소라도 일치하면 참
boolean noneMatch (Predicate<? super T> predicate) // 모든 요소가 불일치하면 참// 100점 미만 낙제자가 있는지 확인
boolean hasFailedStu = stuStream.anyMatch(s->s.getTotalScore()<=100)조건에 일치하는 요소 찾기(findFirst,findAny)
반환값이 null일수도 있어서 Optional< T > 반환
주로 filter와 함께 사용
Optional<T> findFirst() // 첫번째 요소를 반환(순차 스트림 사용)
Optional<T> findAny() // 아무거나 하나를 반환(병렬 스트림 사용)Optional<Student> result = stuStream.filter(s -> s.getTotalSocre() < 100).findFirst()reduce()
스트림 요소를 하나씩 줄여가며 누적연산(Accumulator) 수행
identity : 초기값
accmulator : 이전 연산결과와 스트림의 요소에 수행할 연산
comBiner : 병렬 처리된 결과를 합치는데 사용할 연산
Optional<T> reduce(BinaryOperator<T> accumulator) // 스트림의 요소가 하나도 없으면 null일수 있어서
T reduce(T identity, BinaryOperator<T> accumulator)
U reduce(T identity, biFunction<U,T,U> accmulator, BinaryOperator<U> combiner)//int reduce(int identity, IntBinaryOperator op)
int count = intStream.reduce(0, (a,b) -> a+1);
int sum = intStream.reduce(0, (a,b)->a+b);
int max = intStream.reduce(Integer.MIN_VALUE, (a,b) -> a>b? a:b)
int min = intStream.reduce(Integer.MAX_VALUE, (a,b) -> a<b? a:b);
// sum 동작 코드
int a = identity;
for(int b: stream)
a = a + b; // sum()package ch13;
import java.util.*;
import java.util.stream.*;
public class Ex14_9 {
public static void main(String[] args) {
String[] strArr = {
"Inheritance", "Java", "Lambda", "stream",
"OptionalDouble", "IntStream", "count", "sum"
};
Stream.of(strArr).forEach(System.out::println);
boolean noEmptyStr = Stream.of(strArr).noneMatch(s->s.length() == 0);
Optional<String> sWord = Stream.of(strArr)
.filter(s->s.charAt(0) == 's'). findFirst();
System.out.println("noEmptyStr="+noEmptyStr);
System.out.println("sWord =" + sWord.get());
// Stream<String>을 IntStream으로 변환 (s) -> s.length()
// 그냥 map을 쓰면 Stream<Integer>로 변환
IntStream intStream1 = Stream.of(strArr).mapToInt(String::length);
IntStream intStream2 = Stream.of(strArr).mapToInt(String::length);
IntStream intStream3 = Stream.of(strArr).mapToInt(String::length);
IntStream intStream4 = Stream.of(strArr).mapToInt(String::length);
int count = intStream1.reduce(0, (a,b) -> a+1);
int sum = intStream2.reduce(0, (a,b) -> a+b);
OptionalInt max = intStream3.reduce(Integer::max);
OptionalInt min = intStream4.reduce(Integer::min);
System.out.println("count" + count);
System.out.println("sum" + sum);
System.out.println("max" + max.getAsInt());
System.out.println("min" + min.getAsInt());
}
}ch14-45~49 collect()와 collector
collect()는 Collector라는 인터페이스를 매개변수로 하는 스트림의 최종연산
reduce()는 전체를 기준으로 리듀싱하는 반면 collect()는 그룹별로 리듀싱 가능
Object collect(Collector collector)
Object collect(Supplier supplier, BiConsumer accmulator, BiConsumer combiner)Collector(인터페이스)는 수집에 필요한 메서드를 정의해 놓은 인터페이스
public interface Collector<T,A,R> {
// T요소를 A에 누적한 다음, 결과를 R로 변환해서 반환
Supplier<A> supplier(); // StringBuilder::new (누적할곳)
BiConsumer<A,T> accmulator(); // (sb,s) -> sb.append(s) (누적 방법)
// 결합방법(병렬)
BinaryOperator<A> combiner(); // (sb1,sb2) -> sb1.append(sb2)
// 최종 변환
Function<A,R> finisher(); // sb -> sb.toString()
//컬렉터의 특성이 담긴 Set을 반환
Set<characteristics> characteristics();
...
}
Collectors(클래스)는 다양한 기능의 컬렉터를 제공
-> 대부분 인터페이스 구현안하고 가져다 사용만 잘하면 됨
변환- mapping(), toList(), toSet(), toMap(), toCollection(), ...통계- counting(), summingInt(), averagingInt(), maxBy(), minBy(), summarizingInt(), ...문자열 결합- joining()리듀싱- reducing()그룹화의 분할- groupingBy(), partitioningBy(), collectingAnThen() ...
스트림을 컬렉션으로 변환
toList(), toSet(), toMap(), toCollection()
// map : Stream<Student> -> Stream<String>
// collect : Stream<String> -> List<String>
List<String> names = stuStream.map(Student::getName)
.collect(Collectors.toList());
// Stream<String> -> ArrayList<String>
ArrayList<String> list = names.stream()
.collect(Collectors.toCollection(ArrayList::new));
// Stream<Person> -> Map<String,Person>
// String에는 주민번호 뽑아서 key로 사용, 참조 변수(주소)가 value로
Map<String,Person> map= personStream
.collect(Collectors.toMap(p -> p.getRegId(), p->p));스트림을 배열로 변환
스트림의 메서드 toArray() -> Object 배열 반환
Student[] stuNames = studentStream.toArray(Student[]::new); // OK
Student[] stuNames = studentStream.toArray() // 에러, 자동 형변환 불가
Object[] stuNames = studentStream.toArray(); // OK
// 이렇게 형변환 가능
Student[] stuNames = (Student[])studentStream.toArray() 스트림의 통계 - counting(), summingInt()
통계정보 제공
collect를 사용해야 그룹별로 통계를 낼 수 있다는 점 유의하자!
-> counting(), summingInt(), maxBy(), minBy(), ...
long count = stuStream.count();
long count = stuStream.collect(counting()); // Collectors.counting()long totalScore = stuStream.mapToInt(Student::getTotalScore).sum();
long totalScore = stuStream.collect(summingInt(Student::getTotalScore));OptionalInt topScore = studentstream.mapToInt(Student::getTotalScore).max();
Optional<Student> topStudent = stuStream
.max(Comparator.comparingInt(Student::getTotalScore));
// 그룹별로 max 구할수
Optional<Student> topStudent = stuStream
.collect(maxBy(Comparator.comparingInt(Student::getTotalScore));스트림을 리듀싱(reducing())
Collectors의 리듀싱 메서드
reduce()는 전체 리듀싱인 반면 reducing()은 그룹별 리듀싱 가능
Collector reducing(BinaryOperator<T> op)
Collector reducing(T identity, BinaryOperator<T> op)
// 변환 작업이 필요할 때 두번재 인자 추가
Collector reducing(U identity, Function<T, U> mapper,
BinaryOperator<U> op)IntSTream intStream = new Random().ints(1,46).distinct().limit(6);
// 전체 리듀싱
OptionalInt max = intStream.reduce(Integer::max)
// 그룹별 리듀싱
Optional<Integer> max = intStream.boxed.collect(reducing(Integer::max));
int grandTotal = stuStream.map(Student::getTotalScore).reduce(0,Integer::sum)
int grandTotal = stuStream.collect(reducing(0, Student::getTotalScore, Integer::sum)
Instream에는 매개변수 3개짜리 collect()만 정의되어 있으므로 boxed()를 통해 IntStream을 Stream< Integer >로 변환해야 매개변수 1개짜리 collect()를 쓸 수 있다.
스트림을 문자열로 결합(joining())
문자열 스트림의 모든 요소를 하나의 문자열로 연결 해서 반환
구분자 및 접두사 접미사 지정 가능
// collectors 생략 생각
String studentNames = stuStream.map(Student::getName).collect(joining());
String studentNames = stuStream.map(Student::getName).collect(joining(","));
// map 없이 스트림을 바로 joining()하면 스트림의 요소에
// toString()을 호출한 결과를 결합
String studentInfo = stuStream.collect(joining(","));ch14-50~55 스트림의 그룹화와 변환
// partitioningBy()는 스트림을 2분할
Collector partitioningBy(Predicate predicate)
Collector partitioningBy(Predicate predicate, Collector downstream)
// groupingBy()는 스트림을 n분할
Collector groupingBy(Function classifier)
Collector groupingBy(Function classifier, Collector downstream)partitioningBy()
기본 분할
//학생을 성별로 분할
Map<Boolean, List<Student>> stuBySex = stuStream
.collect(partitioningBy(Student::isMale));
List<Student> maleStudent = stuBySex.get(true); // Map에서 남학생 목록 얻음
List<Student> femaleStudent = stuBySex.get(false); // Map에서 여학생 목록 얻음기본분할 + 통계분할
// Long에 counting() 값 들어감
Map<Boolean, Long> stuNumBySex = stuStream
.collect(partitioningBy(Student::isMale, collecters.counting()));
System.out.println("남학생 수:" + stuNumBySex.get(true));
System.out.println("여학생 수:" + stuNumBySex.get(false)); //maxBy의 반환값이 Optional
Map<Boolean, Optional<Student>> topScoreBySex = stuStream
.collect(
partitioningBy(Student::isMale,
maxBy(comparingInt(Student::getScore))
)
);
System.out.println("남학생 1등 :" + topScoreBySex.get(true));
System.out.println("du학생 1등 :" + topScoreBySex.get(false));
//남학생 1등 : Optional[[나자바, 남, 1, 1, 300]]
//여학생 1등 : Optional[[김자바, 여, 1, 1, 250]]
// 반환값을 Student으로 하고 싶은 경우
Map<Boolean, Student> topScoreBySex= stuStream
.collect(
partitioningBy(Student::isMale),
collectingAndThen(
maxBy(ComparingInt(Student::getScore)), Optional::get
)
)
);
// 이중 분할 -> 성별로 분할후 성적으로 분할
// 이중 Map
Map<Boolean, Map<Boolean, List<Student>>> failedStuBySex = stuStream
.collect(
partitioningBy(Student::isMale,
partitioningBy(s->s.getScore()< 150)
)
);
List<Student> failedMalestu = failedStuBySex.get(true).get(true);
List<Student> failedfeMalestu = failedStubySex.get(false).get(false);groupingBy()
Map<Integer, List<Student>> stuByBan = stuStream
.collect(groupingBy(Student::getBan), toList()); //toList()가 생략 가능(디폴트값)//이중 그룹화
Map<Integer, Map<Integer, List<Student>>> stuByHakandBan = stuStream
. collect(groupingBy(Student::getHak, //학년별 그룹화
groupingBy(Student::getBan) //반별 그룹화
));// 학년 그룹과 반별로 그룹화 한다음에 성적 그룹으로 변환(mapping)하여 setd에 저장
Map<Integer, Map<Integer, Set<Student.Level>>> stuByHakandBan = stuStream.
collect(
groupingBy(Student::getHak,
groupingBy(Student::getBan.
mapping(s-> {
if(s.getScore() >= 200) return Student.Level.HiGH;
else if(s.getScore() >= 100) return Student.Level.MID;
else return Student.LEVEL.LOW;
}, toSet())
)
)
);// 학년,반을 묶어 문자열로 하고 이것을 기준으로 그룹화
Map<String, Set<Student3.Level>> stuByScoreGroup = Stream.of(stuArr).
collect(groupingBy(s-> s.getHak() + "-" + s.getban(),
mapping(s -> {
if(s.getScore() >= 200) return Student3.Level.HIGH;
else if(s.getScore() >= 100) return Student3.Level.MID;
else return Student3.Level.Low;
}, toSet())
));활용 예시는 613page 자세히 참조
ch14-55 스트림의 변환