안녕하세요 오늘은 광학현미경의 영상을 깊이영상으로 바꿔주는 프로젝트를 진행하겠습니다.
데이터셋의 출처입니다.
https://dacon.io/competitions/official/235954/data
프로젝트의 목표입니다.
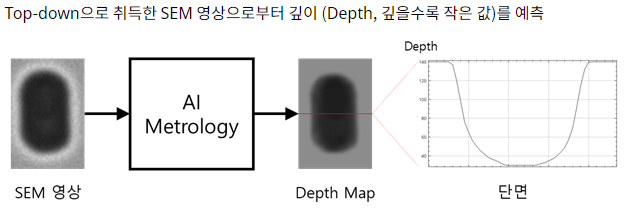
먼저 각 데이터에 대해서 살펴보겠습니다.
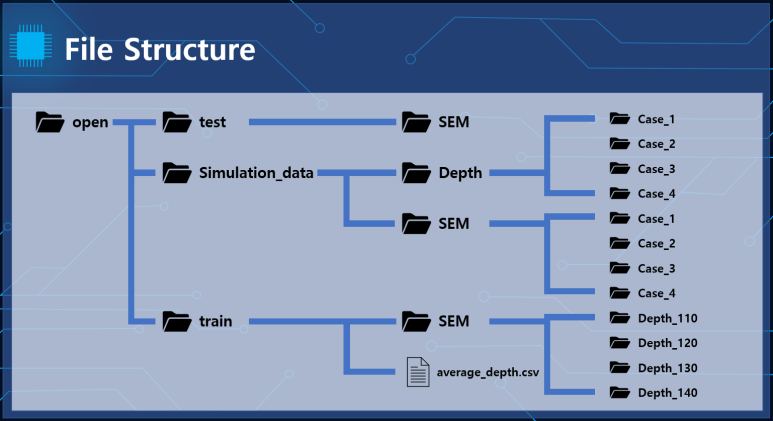
train 폴더입니다.

simulation 폴더입니다.

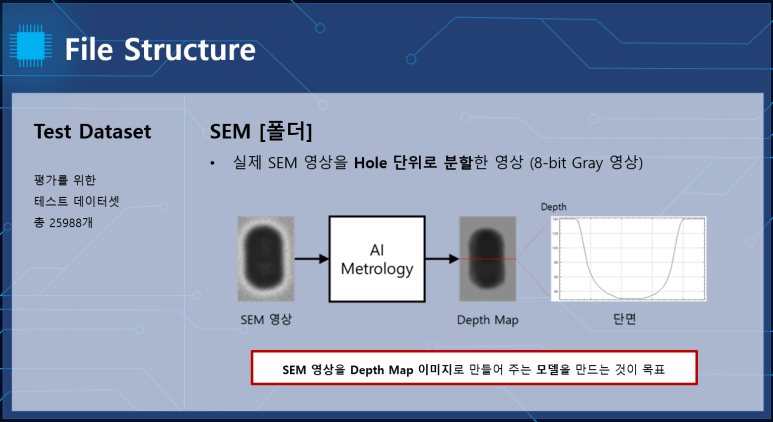
test 폴더입니다.
다음 EDA한 내용을 살펴보겠습니다.
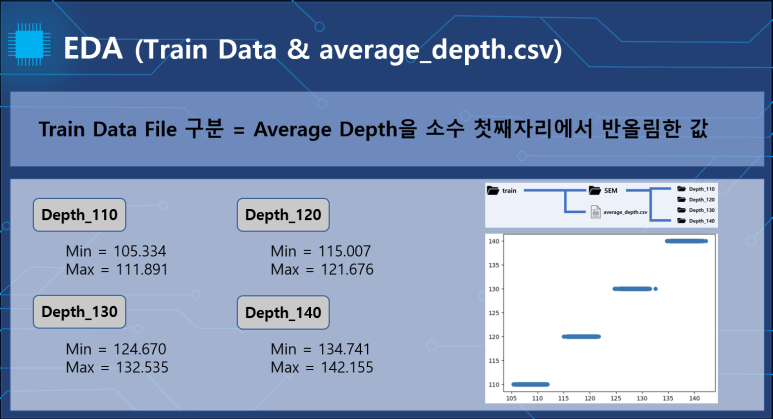
train 폴더의 Average depth.csv파일을 상위폴더인 파일명에 따라 구분시켜서 시각화했습니다.
depth_*에 따라 구분되어 있는것을 볼수 있습니다.
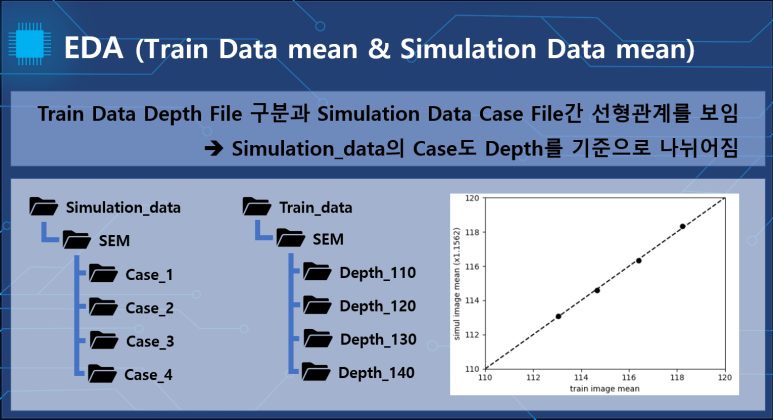
그래프의 각 dot들은 simulation의 case안의 이미지 파일들의 평균을 찍었습니다.
이들도 case에 따라 구분되면서 선형적인 형태를 띄었습니다.
이를 통해서 train의 depth와 simulation의 case가 선형적인 관계를 나타내며 대응되는 것을 가정하였습니다.
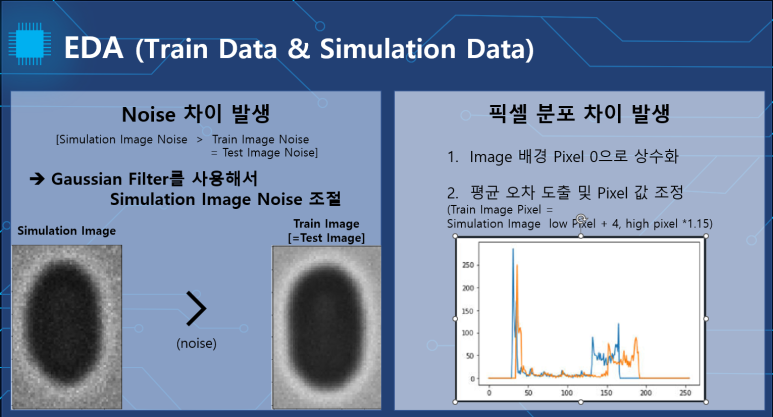
simulation case안 이미지의 평균 데이터를 살펴보니 train에 비해서 노이즈가 심하였고 픽셀 분포도 대응되지 않았습니다.
하지만 train과 test가 유사한 모습을 나타내었고 아웃풋으로 학습시켜야 할 depth image는 simulation 폴더에만 존재하였기 때문에 추후 학습시에 가우시안 상수 1의 가우시안 필터를 적용시킨후 각 위치의 픽셀을 직접 접근해 수정하여 train의 데이터와 유사하게 수정후 학습 진행했습니다.
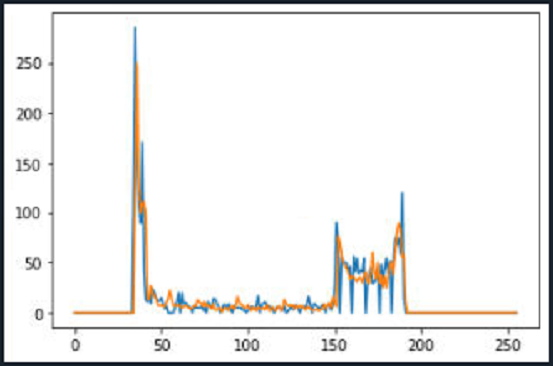
수정후의 히스토그램입니다.
어느정도 유사한 모습을 보여줍니다.

각 simulation depth image의 case별 특이점으로는 배경의 픽셀값이 하나의 상수로 다르게 나타났습니다.
이를 통해 case의 분류가 필요하다고 판단하였습니다.
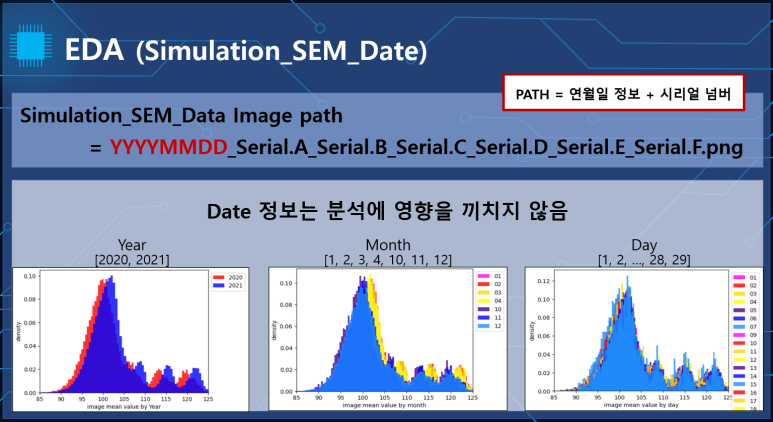

그 외의 정보는 어떠한 영향 결과에 끼치는 영향을 찾아볼 수 없었습니다.
다음 앞선 eda를 바탕으로 적절한 러닝 프로세스를 구상하였습니다.

simulation의 각sem파일을 train data와 유사하게 수정후 depth image를 생성해주는 모델을 case별로 4개 구성합니다.
train폴더의 depth_*의 폴더명 정보를 통해서 case를 구분해주는 classification 모델을 구성합니다.
test는 case classification모델을 사용하여 무슨 case인지 구분하고 그에 맞는 case의 depth estimation 모델을 적용시킨 후 배경을 case에 맞게 상수화하는것으로 진행하였습니다.
그리고 모든 모델은 원본, 상하반전, 좌우반전, 원점대칭 augmentation을 사용하여서 4배 데이터 증강 후 학습하였습니다.
class casemodel(nn.Module):
def __init__(self):
super(casemodel, self).__init__()
self.fc1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=True),
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=True),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
self.fc2=nn.Sequential(
nn.Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=True),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=True),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
self.flatten=nn.Sequential(
nn.Flatten()
)
self.fc3=nn.Sequential(
nn.Linear(13824,512),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512,256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256,4)
)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
x = self.flatten(x)
x = self.fc3(x)
return xcase classification 모델입니다.
간단한 cnn과 fully connected linear layer을 사용하여 구성했습니다.

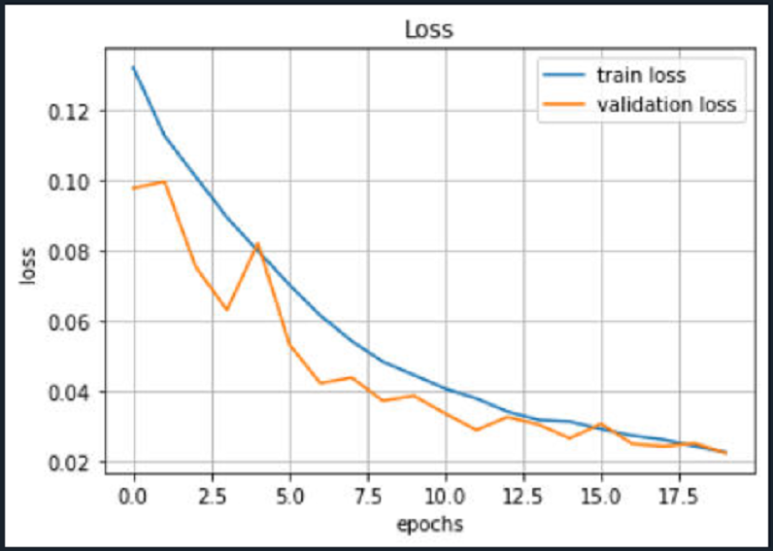
epoch은 20회 진행하였고 정확도는 99.2%로 높은 정확도를 보였습니다.
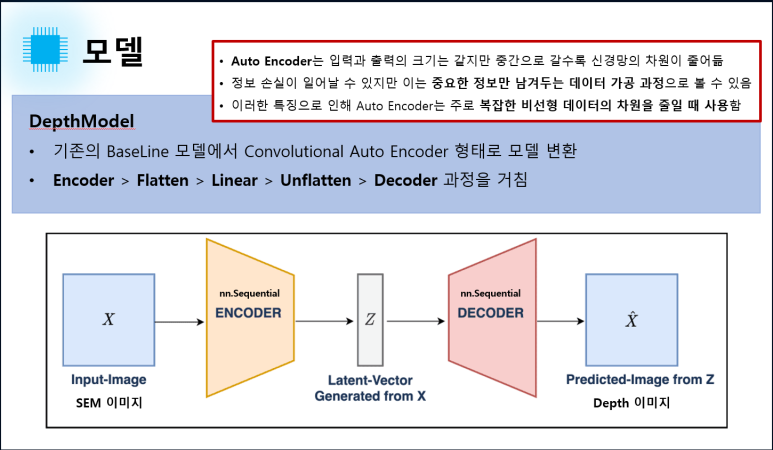 depth estimation 모델입니다.
depth estimation 모델입니다.
class depthmodel(nn.Module):
def __init__(self):
super(depthmodel,self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1,64,3, stride=2, padding = 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,128,3, stride=2, padding = 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,256,3,stride=2, padding = 1),
nn.ReLU()
)
self.flatten = nn.Sequential(nn.Flatten(start_dim = 1),
nn.Dropout(0.2))
self.encoder_lin = nn.Sequential(
nn.Linear(256*9*6,2048),
nn.ReLU(),
nn.Linear(2048, 256*9*6),
)
self.unflatten = nn.Unflatten(dim=1, unflattened_size = (256,9,6))
self.decoder = nn.Sequential(
nn.ConvTranspose2d(256,128,3,stride=2,padding = 1,output_padding = 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(128,64,3, stride=2, padding = 1, output_padding = 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64,1,3, stride=2, padding = 1, output_padding = 1)
)
def forward(self, x):
x = self.encoder(x)
x = self.flatten(x)
x = self.encoder_lin(x)
x = self.unflatten(x)
x = self.decoder(x)
#CNN->flatten->fully connected layer->unflatten->upsampling cnn
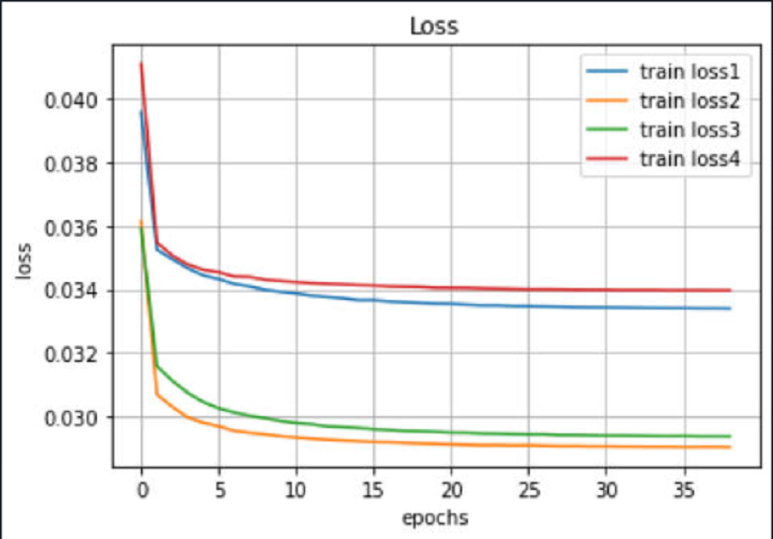
return xcriterion은 L1score, optimizer는 adam, scheduler로 epoch마다 0.9비율로 lr조정후 40epoch 진행하였습니다.
학습 loss 시각화입니다.
마지막 제출파트 입니다.
import zipfile
def inference(model1,model2,model3,model4,case_model,case_loader, test_loader, device):
model1.to(device)
model1.eval()
model2.to(device)
model2.eval()
model3.to(device)
model3.eval()
model4.to(device)
model4.eval()
case_model.to(device)
case_model.eval()
a1=torch.tensor([[0]]).to(device)
a2=torch.tensor([[1]]).to(device)
a3=torch.tensor([[2]]).to(device)
a4=torch.tensor([[3]]).to(device)
result_name_list = []
result_list = []
a=0
b=0
c=0
d=0
with torch.no_grad():
for sem, name in tqdm(iter(test_loader)):
sem_img = sem.float().to(device)
case_sem=sem.to(device)
logit = case_model(case_sem)
case = logit.argmax(dim=1, keepdim=True)
global model_pred
if case==a1:
model_pred = model1(sem_img)
a+=1
case_int=1
elif case==a2:
model_pred = model2(sem_img)
b+=1
case_int=2
elif case==a3:
model_pred = model3(sem_img)
c+=1
case_int=3
elif case==a4:
model_pred = model4(sem_img)
d+=1
case_int=4
else:
print('something wrong')
for pred, img_name in zip(model_pred, name):
pred = pred.cpu().numpy().transpose(1,2,0)*255.0
pred=pred.astype(int)
Min_value1=np.min(pred[0])
Min_value2=np.min(pred[71])
Min_value=min(Min_value1,Min_value2)
Class=case_int*10+130
pred[pred>=Min_value]=Class #define background brighter than min value from first line
pred[pred>Class]=Class #define background brighter than class value
save_img_path =f'{img_name}'
#im=torchvision.transforms.functional.to_pil_image(pred)
#im.save(save_img_path)
cv2.imwrite(save_img_path, pred)
result_name_list.append(save_img_path)
result_list.append(pred)
os.makedirs('/home/nvidia/Workspace/Samsung/submission', exist_ok=True)
os.chdir("/home/nvidia/Workspace/Samsung/submission/")
sub_imgs = []
for path, pred_img in zip(result_name_list, result_list):
cv2.imwrite(path, pred_img)
sub_imgs.append(path)
submission = zipfile.ZipFile("/home/nvidia/Workspace/Samsung/submission/beforeattach.zip", 'w')
case_list=[a,b,c,d]
print(case_list)
for path in sub_imgs:
submission.write(path)
submission.close()
주의해야 할 점은 test loader의 batchsize를 1로 조정해야 정상적으로 작동합니다.
case_model에 먼저 대입한 후에 case를 판별합니다.
그리고 그 case에 맞는 모델을 대입한 후에 depth image를 받게 됩니다.
하지만 여기서 끝이 아닌데요

이 image는 depth이미지중 하나를 가져온 것인데 보시면 모든 이미지의 물체가 항상 중앙에 위치하여 있습니다.
그리고 사이드는 항상 배경인것을 확인할 수 있는데요.
이미지의 첫row와 이미지의 마지막row중 가장 어두운 픽셀을 선정후 그 픽셀보다 밝거나 같다고 판별시에는 배경으로 인식해 case에 맞는 배경pixel로 상수화 후 제출하였습니다.
test 이미지들의 각 case 분류결과입니다.

균일하게 case가 분포되어 있네요
test의 첫번째 이미지

출력 결과값

최종score(RMSE 기준)

자세한 코드는 아래의 링크에서 확인할 수 있습니다.
https://github.com/wooseok-shim/SEM-depth-estimation
이상입니다 긴글 읽어주셔서 감사합니다.
