ERNIE(Enhanced Representation through Knowledge Integration)
서론
BERT와 같은 여러 LM은 문맥 안에서 masked 단어를 예측하는 방식으로 학습한다. 이때, 문장에 대한 사전 지식은 고려하지 않는다. 예를 들어 “Harry Potter is a series of fantasy novels written by J. K. Rowling” 문장에서 mask인 Harry Potter를 쉽게 유추할 수는 있지만, Harry Potter와 J. K. Rowling 간의 관계는 알기 어렵다.

따라서 ERNIE은 Knowledge masking 방식을 사용한다. 즉, 기본적인 masking 전략에 더해, Entity-level masking과 Phrase-level masking을 사용한다. 따라서 BERT는 각 단어를 일정 확률로 masking하고 이를 예측하는 반면, ERNIE은 단어뿐만 아니라 Entity, Phrase 전체를 하나의 unit으로 masking한다.
본론

1) Basic-level masking
BERT와 동일하게, 기본 단위(영어는 한 단어, 중국어는 한 글자)를 masking하여 학습하는 단계이다.
2) Phrase-level masking
여러 단어나 글자를 하나의 개념적 단위로 묶어, phrase 안의 모든 단어(글자)를 masking하여 학습하는 단계이다.
영어의 경우, 어휘분석과 chunking, 언어의존적 분할 도구를 사용하여 phrase를 도출한다.
3) Entity-level masking
사람, 지역 등의 Named entity로 묶어, entity 안의 모든 단어(글자)를 masking하여 학습하는 단계이다.
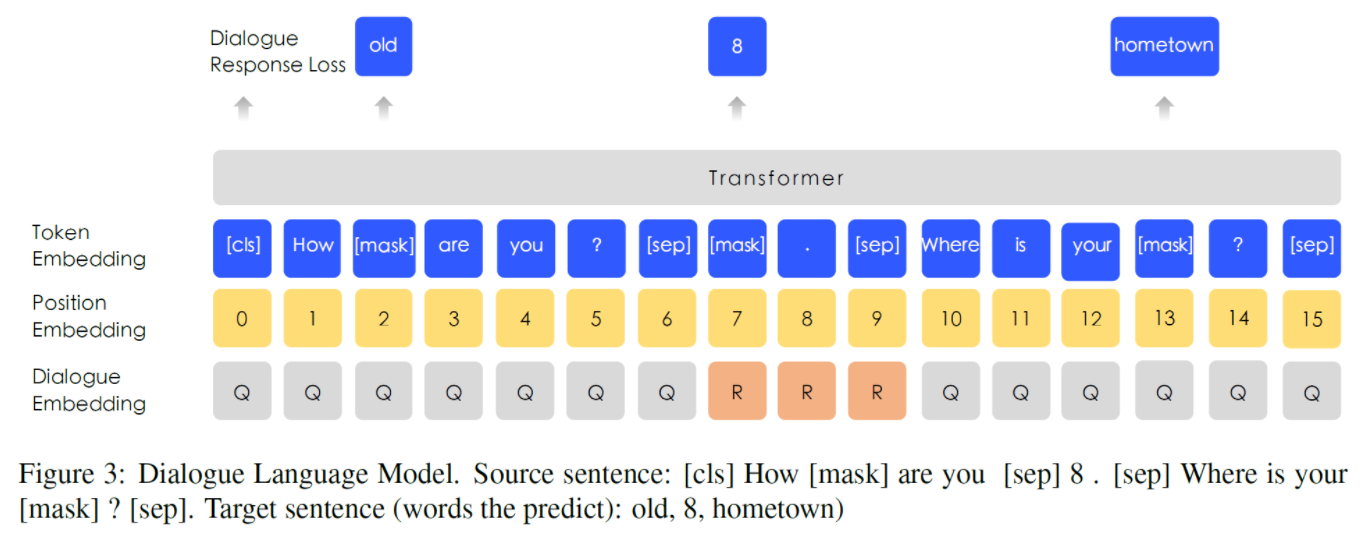
Dialogue embedding은 Segment embedding과 달리 multi-turn 대화를 나타내도록 embedding된다.(Question-Response-Question 등)
실험
비교를 위해 ERNIE 또한 12 encoder layers, 768 hidden units, 12 attention heads로 BERT-base와 동일한 크기를 갖는다.
중국 Wikipedia, Baidu Baike/News/Tieba 말뭉치를 사용하여 pretraining을 진행하였다. 각 문장 수는 21M~54M이며, 한자는 번체에서 간체로, 영어는 소문자로 변환하고, 17,964개의 공유 유니코드 문자를 포함한다.
5개의 중국어 NLP 태스크를 수행하였다.
1) 자연어추론: 모순, 중립, 함의를 포함하고 중국어 포함 14개 언어 쌍이 있는 XNLI(Cross-lingual NLI) 코퍼스를 사용하였다.
2) Semantic Similarity: LCQMC 코퍼스를 사용하여, 두 문장이 같은 내용(intention)을 포함하는지를 판별하였다.
3) Name Entity Recognition: Microsoft Research Asia에서 배포한 MSRA-NER 코퍼스를 사용하였다.
4) Sentiment Analysis: ChnSentiCorp 코퍼스를 사용하였다.
5) Retrieval Question Answering: NLPCC-DBQA 코퍼스를 사용하였으며, 평가 방법은 MRR과 F1 score 사용하였다.
실험 결과

위의 실험 결과와 같이, ERNIE가 모든 태스크에 대해 BERT를 능가하는 SOTA를 달성했다.

Word, phrase, entity level 각각의 masking 효과를 살펴보기 위해 전체의 10% 학습 데이터를 사용하였다. Phrase, entity level에서 성능 향상을 보였다. 10%의 학습 데이터만 사용하였을 때보다 전체 데이터를 사용하였을 때, 0.8%의 성능 향상을 보였다.

DLM을 학습에 포함시킨 경우가 그렇지 않은 경우에 비해 0.7%/1.0% 정도 성능이 향상했다.
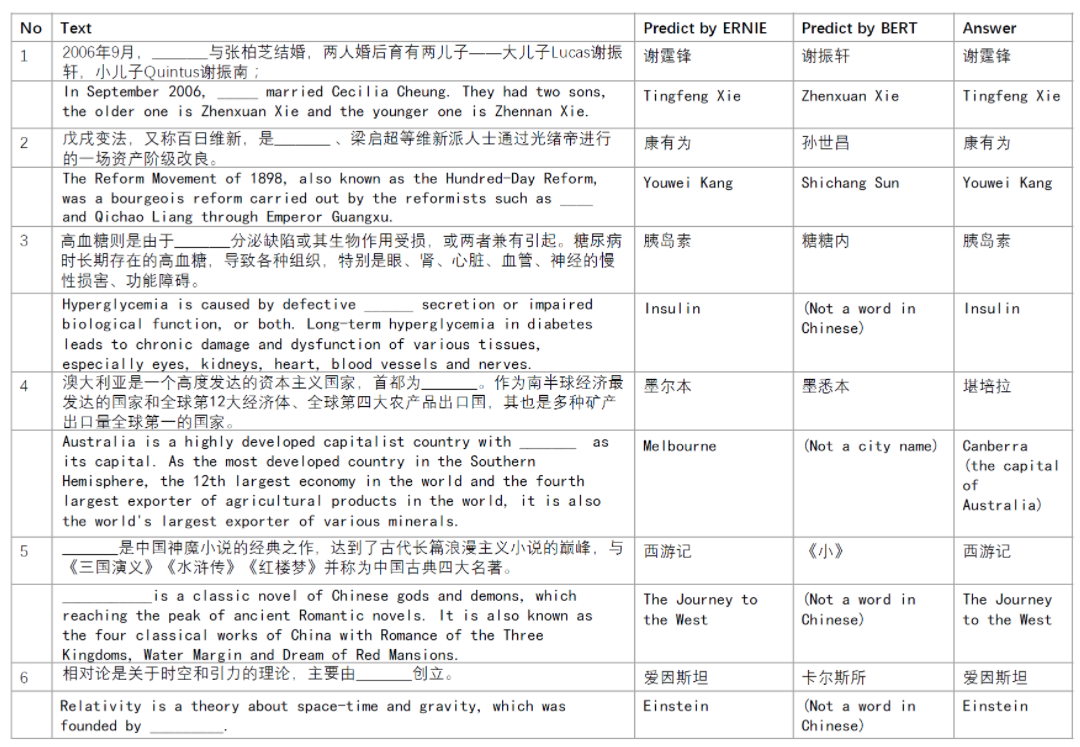
단락에서 Named Entity를 제거하고 모델이 이를 추론하는 Cloze test를 진행하였다. BERT는 문장으로부터 단순 복사한 반면 ERNIE는 기사에서 언급된 지식 관계를 기억하고 있었거나(Case 1), BERT가 entity 종류는 맞췄지만 제대로 채우는 데에는 실패했다거나(Case 2,5), 빈칸을 여러 글자로 채웠지만 의미는 맞추지 못한(Case 3, 4, 6) 예시가 있다.
결론
ERNIE는 knowledge를 명시적으로 입력받는 대신, 암묵적으로 학습하고 더 긴 의미적 의존성을 파악함으로써, 더 나은 일반화 및 적응 능력을 가질 수 있다.
Reference
https://greeksharifa.github.io/nlp(natural%20language%20processing)%20/%20rnns/2021/06/14/ERNIE/
