K-Nearest Neighbor(KNN)
- 새로운 데이터가 주어졌을 때, 가장 가까운 K개의 이웃의 정보로 새로운 데이터를 예측하는 방법 (Instance based learning)
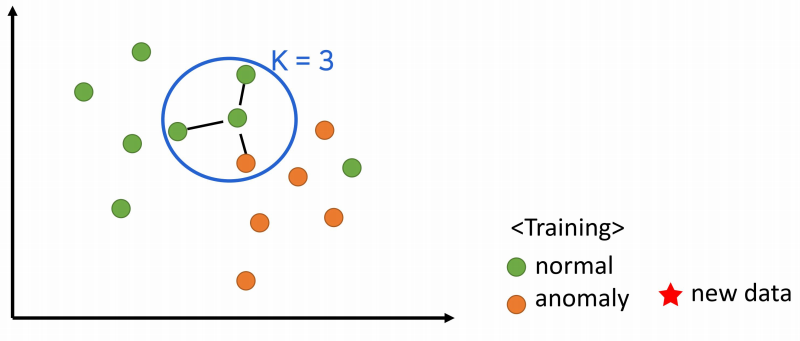
- 분류 : 다수결로 예측 KNeighborsClassifier
- 회귀 : 평균 값으로 결과 예측 KNeighborsRegressor
KNN 모델 성능의 주요 이슈
- 1) 데이터 간의 거리는 어떻게 측정하는가 (거리 측정 방법)
- 2) K 값의 크기는 어떻게 설정할 것인가 (탐색할 이웃의 개수)
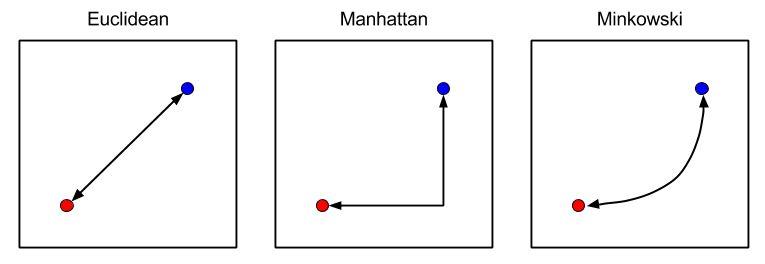
1) 데이터 간의 거리는 어떻게 측정하는가
- 어떤 계산법을 사용하느냐에 따라서 이웃의 선택기준이 달라짐
- 모델의 예측 결과에 영향을 줌
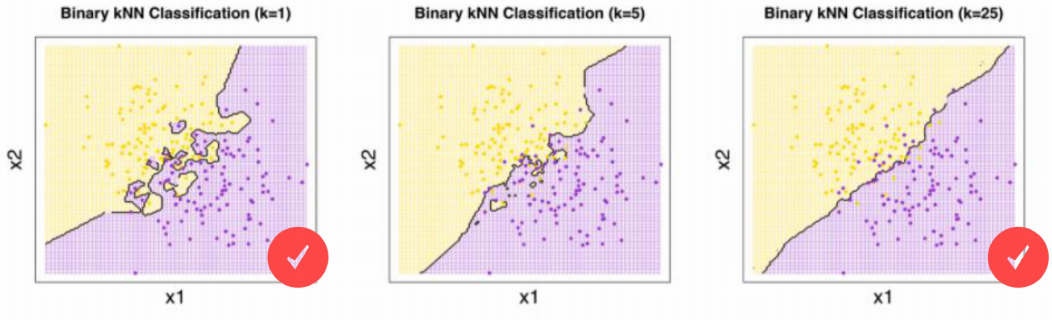
2) 적절한 K 값의 크기는 어떻게 설정할 것인가
- K 값이 너무 작으면, 민감도가 높아서 잘못 예측할 확률이 높아짐 (overfitting)
- K 값이 너무 크면, 분류나 예측 자체가 둔감해지기 때문에 결과가 좋지 않음 (underfitting)
- 최적의 K 값은 찾기 어렵기 때문에, 먼저 3으로 지정해고 변경해가며 찾음
KNN의 특징
- 매우 단순하고 직관적인 알고리즘, 노이즈 영향 X
- 실행 시점에 K값에 의한 거리 연산 발생(고비용)
- 최적의 K값을 찾는것이 중요
- 데이터의 스케일이 서로 다른 경우 별도의 정규화 과정 필요

I'm a Graduate student studying Deep Learning.KR👨💻