AI
• 학습, 문제 해결, 패턴 인식 등 인지 문제를 해결하는 컴퓨터 공학 분야.
• 1943년 처음으로 개념이 등장.
• 최근 빅데이터와 컴퓨팅 성능 향상으로 인해 폭발적인 성장 중.
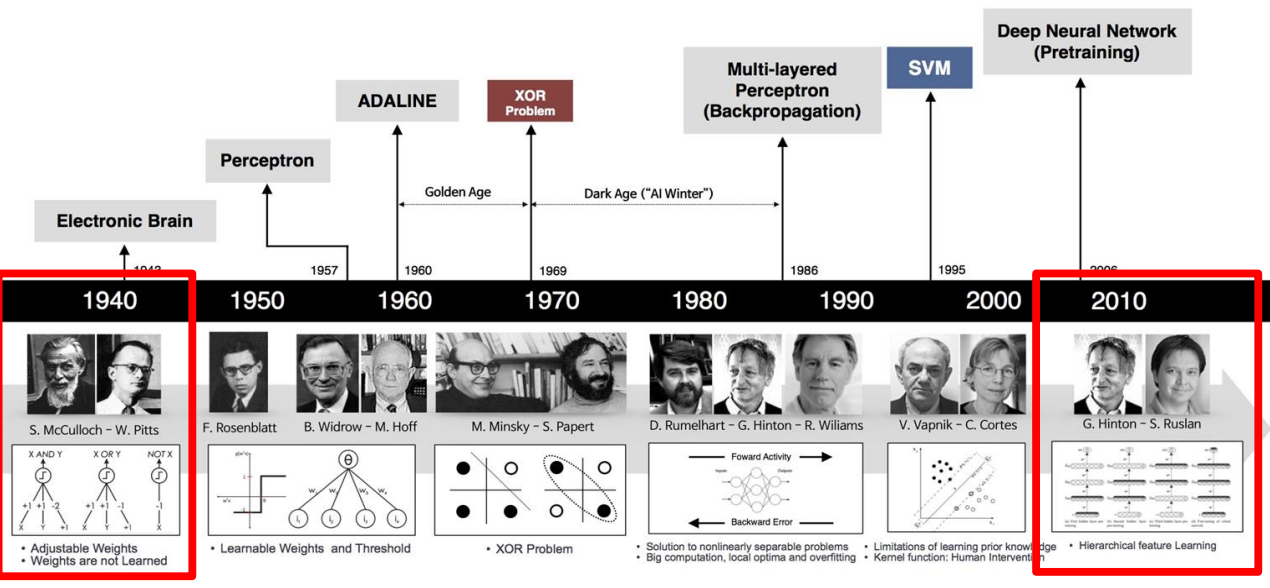
• Narrow AI
→좁은 영역에서 특정한 task만 가능하지만 정확도나 속도는 인간을 넘어섬.
• General AI
→하나의 task에서 습득한 지식을 여러 task에 적용 가능.
• Super AI
→인간을 뛰어넘은 성능을 보여주는 인공지능.
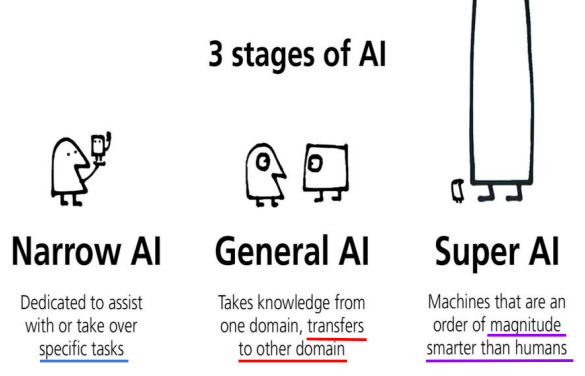
머신러닝 개요
머신러닝이란?
데이터로부터 기계가 학습을 하는 알고리즘!
• 인공지능을 구현하는 구체적인 접근 방식 중 하나.
• 기존의 방식은 코드를 통해서 수행 방법을 구체적으로 명시(심볼릭 AI).
• 머신러닝은 코드가 아닌 대량의 데이터로부터 학습을 하고, 학습된 모델을 통해 판단 또는 예측을 함.
ex)
1. 이탈리아에서 파스타를 먹고 지금까지 모든 파스타는 거짓이었음을 깨달음.
2. 집에 돌아와 같은 맛을 내보려고 시도 레시피는 없고 맛의 기억만 존재.
3. 어떻게 비슷한 파스타를 만들 수 있을까? → 기억하는 맛을 재현할 때까지 끝 없는 반복과 시행 착오
4. 수백번의 시도 끝에 비슷한 맛을 만드는데 성공.
프로그래밍
규칙 + 데이터 = 해답
머신러닝
데이터 + 해답 = 규칙
머신러닝 사용의 장점
• 프로그램이 간단해 유지 보수가 쉽고, 대부분 정확도 더 높음
• 패턴 변경 시에도 별도의 작업을 하지 않아도 됨
• 전통적인 방식으로 해결하기에 복잡한 문제를 쉽게 해결 가능
• 전통적인 방식으로 해결 할 수 있는 알고리즘이 없는 경우에도 적용 가능
• 데이터 분석을 통해 전에 보이지 않던 패턴 발견 가능 (데이터 마이닝)
머신러닝의 종류
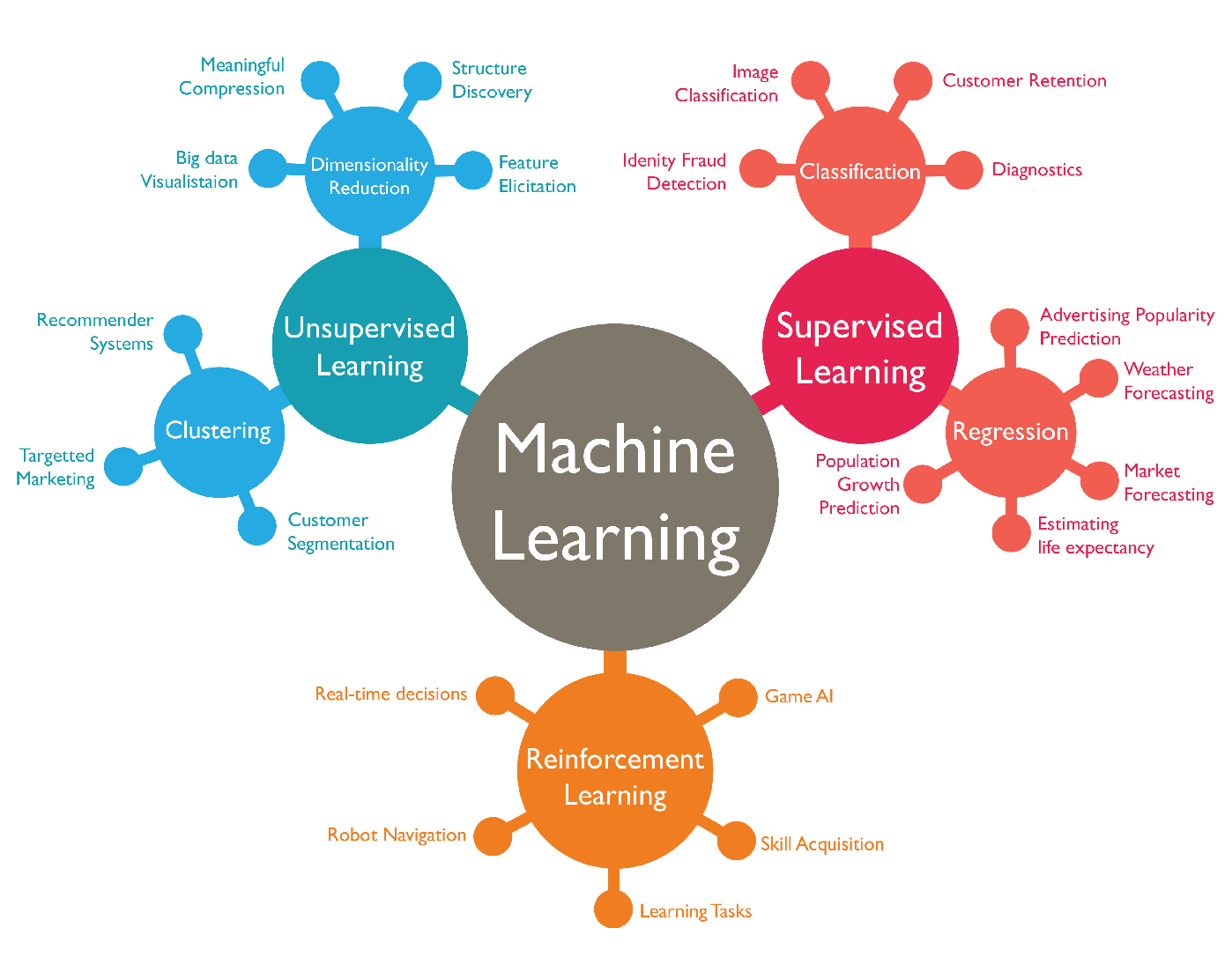
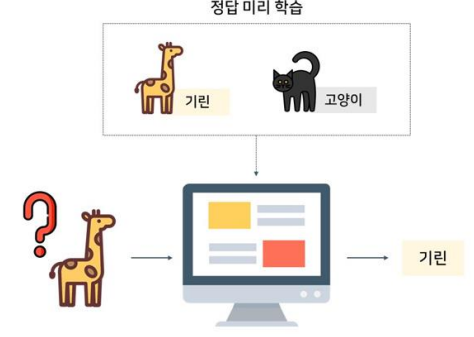
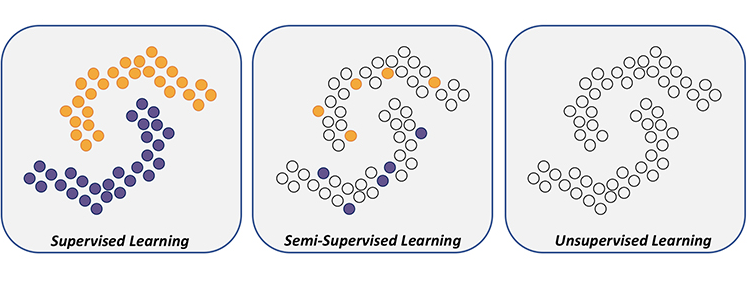
지도 학습 (Supervised Learning)
• 라벨이 붙여진 데이터 셋을 학습 후 신규 데이터에 라벨을 붙임
• 예) 이메일 스팸 필터링, 이미지 분류
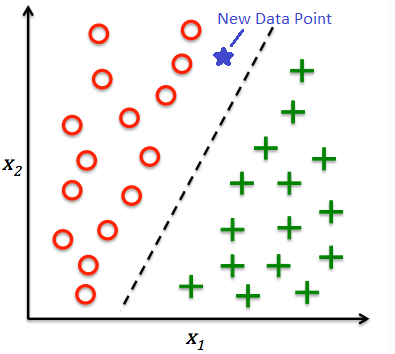
1) 분류 (Classification)
• 지도 학습
• 예측하고자 하는 값이 범주형 데이터인 경우 사용
• 문서 분류, 이미지 분류
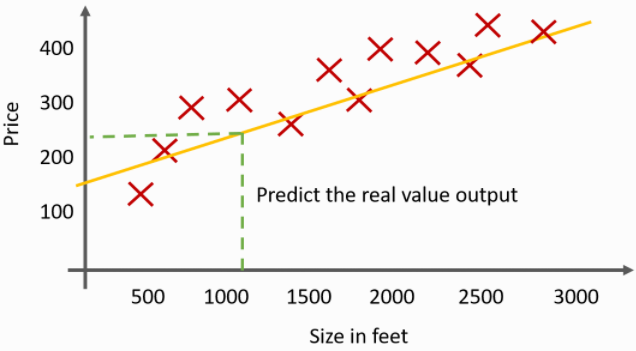
2) 회귀 (Regression)
• 지도 학습
• 예측하고자 하는 값이 연속형 데이터인 경우
• 주식 가격 예측, 부동산 가격 예측
비지도 학습 (Unsupervised Learning)
• 정답 라벨이 없는 데이터를 기반으로 학습하는 방식
• 라벨이 없는 데이터 들에서 패턴을 찾음
• 예) 유사 단어 클러스터링, 유사 이미지 클러스터링
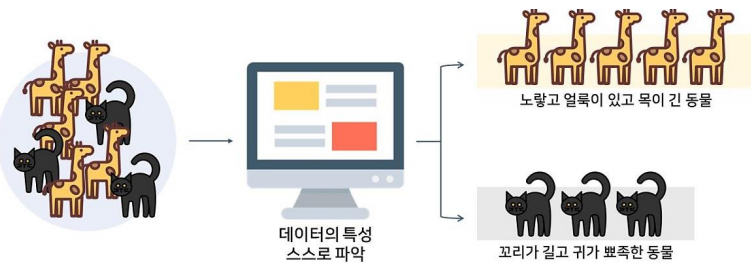
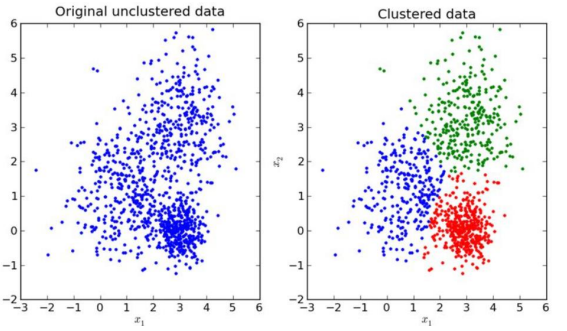
군집 (Clustering)
• 라벨이 없는 데이터를 분류하는 것
• 데이터의 특징, 구조를 통해 유사한 특성을 가진 데이터끼리 그룹화 하는 것
• ex) 고객 분류, 추천 시스템, 유사 단어 및 이미지 군집화
준지도 학습 (Semi-supervised Learning)
• 라벨이 있는 데이터와 라벨이 없는 데이터를 모두 사용하여 학습하는 방식
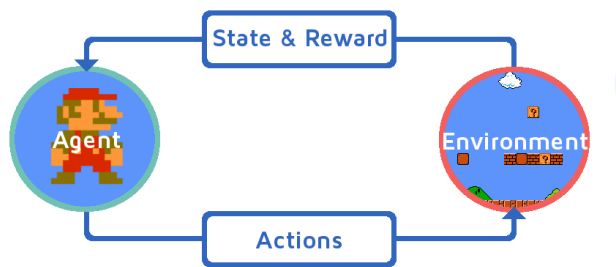
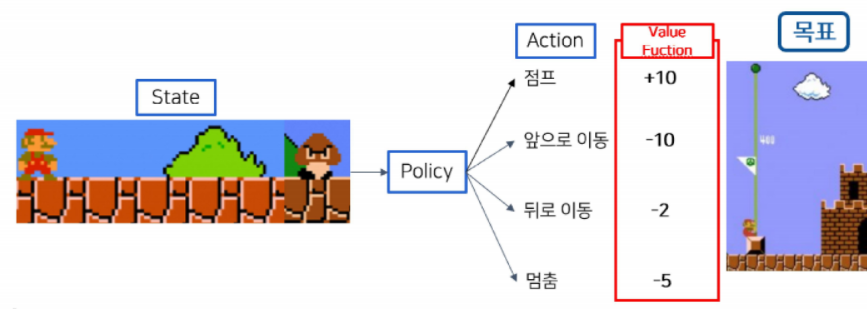
강화 학습 (Reinforcement Learning)
• 모델이 목표를 달성할 수 있도록 피드백 또는 보상을 통하여 학습을 진행
• 특정 목표를 달성하는데 최선의 전략을 선택하도록 학습됨
• 환경을 보고 목표를 위해 어떤 행동을 해야하는지 최선의 선택을 함
• 예) 체스게임, 알파고, 지능형 로봇
머신러닝을 위한 6단계
- 문제 정의 및 모델 선정
- 데이터 수집
- 데이터 전처리
- 특징 추출
- 학습
- 검증
1. 문제 정의 및 모델 선정
• 해결하려는 문제를 명확하게 정의
• 머신 러닝으로 모든 문제를 해결할 수는 없음
• 해결할 문제에 가장 적절한 모델(알고리즘)을 선정
2. 데이터 수집
• 데이터의 양이 학습된 모델의 품질을 결정
• 많고 다양한 데이터를 수집해야 함
• 대표성을 갖고, 고품질의 데이터일수록 좋음
• 인공지능은 사람의 노가다(?)가 필수적임
• 데이터를 수집하면, 분활 작업 진행
• Training, Validation, Test 용도로 분할하며 교차 검증 (Hold-out Cross Validation)이라고도 함
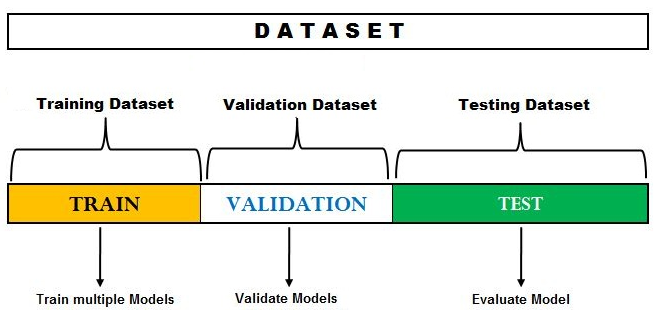
• Training : 머신러닝 모델의 학습에 사용되는 데이터 셋
• Validation : 학습된 머신러닝 모델의 성능을 평가하는데 사용되는 데이터 셋으로 모델 개선의 지표가 됨
• Testing : 학습 및 개선된 머신러닝 모델을 최종 평가하는 데이터 셋
3. 데이터 전처리
• 머신 러닝에서 가장 오래 걸리고 힘든 작업
- 사진의 경우 크기 조정, 밝기 조정, 중요한 부분 Crop 등의 작업
- 음성의 경우 노이즈 제거 작업, 단위 시간 별로 자르는 작업
- 자연어의 경우 오타 수정 등
• 지도 학습의 경우 데이터 Labeling 작업
- 수십, 수백만 장의 이미지에 Labeling (번호를 단다고 생각하면 됨)
4. 특징 추출
• 데이터 중 주요한 특징 (Feature)만 추출하는 작업
ex) Edge Detection

5. 학습 및 검증
• 전처리가 완료된 학습 데이터 셋으로 모델을 학습
• 최적의 값을 찾을 때까지 충분한 데이터로 모델을 학습
• 모델 학습이 완료 후 검증 데이터 셋을 사용하여 모델을 검증
• 다양한 검증 지표들 존재 ex) 정확도, 정밀도...
