(가)
서브쿼리까지 할 수 있다.
서브쿼리란?
쿼리 안에 포함된 또 다른 쿼리다. 다른 쿼리의 결과를 먼저 알아야 원하는 답을 구할 수 있을 때 사용한다.
SELECT * FROM albums
WHERE ArtistId = (SELECT ArtistId FROM artists WHERE Name = 'AC/DC');
이런 식으로 사용된다.
괄호 안에 들어있는 것이 서브쿼리이다.
서브쿼리는 중첩되어 쓰일 수 있다.
가장 바깥에 하나 있고 중간에 하나 있고 가장 내부에 하나 있는 방식과 같이 말이다..
예를 들어 "평균 가격보다 비싼 트랙"을 찾고 싶다고 하자.
서브쿼리를 쓰지 않을 경우
평균을 먼저 계산해 눈으로 확인해야한다.
SELECT AVG(UnitPrice) FROM tracks;
결과: 1.05
그 다음에 그 값을 직접 입력해야 한다.
SELECT Name FROM tracks WHERE UnitPrice > 1.05;
서브 쿼리를 사용하면 한 번에 입력할 수 있다.
SELECT Name FROM tracks
WHERE UnitPrice > (SELECT AVG(UnitPrice) FROM tracks);
WHERE vs HAVING
처음에 이렇게 하면 되지 않을까 생각했다:
sqlSELECT name FROM tracks
HAVING unitprice > AVG(unitprice); 근데 안됨
안 되는 이유: HAVING은 GROUP BY와 함께 쓰는 것이다.
MAX(COUNT())가 안 되는 이유
"가장 많은 트랙이 있는 앨범"을 찾고 싶을 때:
SELECT AlbumId
FROM tracks
GROUP BY AlbumId
HAVING COUNT() = MAX(COUNT(*)); 안된다.
집계함수 안에 집계함수는 못 쓴다. 따라서 서브쿼리로 우회해야 한다:
SELECT MAX(cnt)
FROM (SELECT COUNT(*) as cnt FROM tracks GROUP BY AlbumId);
별칭(cnt)이 필요한 이유는 바깥 쿼리에서 안쪽 컬럼을 참조해야 하기 때문이다.
예제도 달라고 해서 스스로 또 시도해본다.
가장 많은 앨범을 낸 아티스트 찾기
보통 안쪽 쿼리부터 바깥쿼리로 순차적으로 만든다고 한다.
안쪽쿼리
아티스트별 앨범 수
SELECT artistid, COUNT(*) as cnt
FROM albums
GROUP BY artistid;
중간쿼리
가장 많은 앨범을 가진 ArtistId를 구하기
사실 MAX 대신 ORDER BY + LIMIT1이 더 간단하다고 한다.
SELECT artistid
FROM (SELECT artistid, COUNT(*) as cnt
FROM albums
GROUP BY artistid)
ORDER BY cnt DESC
LIMIT 1;
바깥쿼리
SELECT name
FROM artists
WHERE artistid = (
SELECT artistid
FROM (SELECT artistid, COUNT(*) as cnt
FROM albums
GROUP BY artistid)
ORDER BY cnt DESC
LIMIT 1
);
결과: Iron Maiden (21개 앨범)
(나)
페캠 강의듣기
엑셀사용법 강의를 듣기
데이터 분석을 하는데 쓸 수 있다. 셀 참조(A1, B2 같은), 기본 수식(SUM, AVERAGE 등), 필터/정렬 기능 정도는 익숙해져야 한다.
F4 키 (절대참조/상대참조)
수식을 복사할 때 셀 주소가 자동으로 바뀌는 게 상대참조(A1), 고정되는 게 절대참조($A$1)다. 수식 입력 중 F4를 누르면 알아서 전환된다. 여러 행에서 같은 셀을 참조해야 할 때 절대참조를 쓴다.
VLOOKUP
어떤 값을 찾아서, 옆에 있는 데이터를 가져오도록 하는 함수다.
셀에 이렇게 입력한다.
=VLOOKUP(찾을값, 범위, 몇번째열, 정확히일치)
ex.=VLOOKUP(A2, Sheet2!A:C, 3, FALSE)
위 예시는 "A2 값을 Sheet2의 A열에서 찾아서, 3번째 열 값을 가져와라"라고 명령하는 것이다. 마지막 FALSE는 정확히 일치하는 것만 찾으라는 의미.
데이터 전처리로 분석 전에 데이터를 깔끔하게 정리하자.
피벗테이블
대량의 데이터를 요약, 집계, 분석할 수 있다.
원본 데이터가 이렇게 있다고 하자
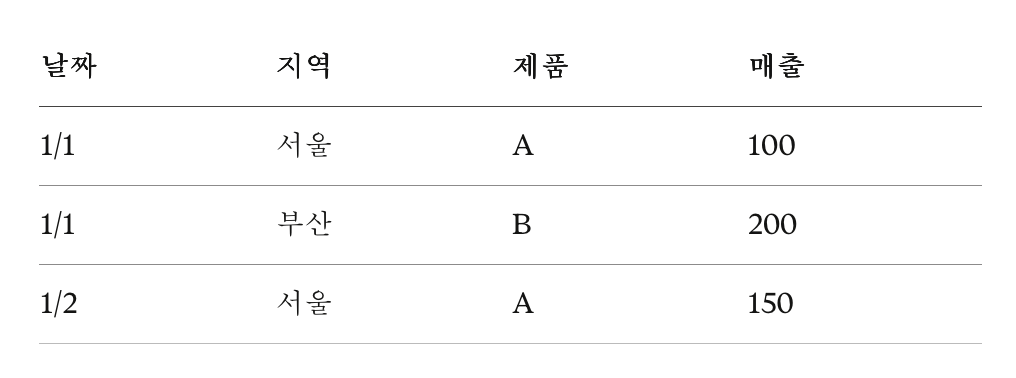
결과:

보기 불편하니까 편하게 모아 보겠다는 거다.
데이터 범위 선택
삽입 → 피벗테이블
필드를 원하는 영역에 드래그
원본 데이터는 빈곳 없이 정리되어 있어야 한다
데이터 추가 후 피벗테이블 우클릭
값 필드 설정에서 합계/평균/개수 등 변경 가능
그룹화 기능으로 날짜를 묶을 수 있다
상관분석
두 변수 간의 관계를 수치로 나타낸 것이 상관계수다. -1에서 1 사이 값을 가지며, 1이 양의 상관 -1이 음의 상관, 0이 상관없음을 의미하는 거다. 상관관계와 인과관계를 혼동하면 곤란하다. 아이스크림매출이 오른다고 해수욕장 관광객이 늘어나는 것은 아니니까
데이터 검정
통계적으로 유의미한지 보기.
