2차원의 이미지는 2차원의 텐서로 표현할 수 있지만, 3차원 데이터를 표현하는 데에는 다양한 방법이 존재한다. Voxel Grid, Point Cloud와 같이 explicit한 방식으로 표현할 수도 있지만, neural network를 통해서 implicit하게 표현하는 방법도 있다.
본 포스팅에서는 implicit한 3D scene representation을 바탕으로, 3D scene rendering 방법을 제안하는 NeRF라는 논문에 대해 소개한다.
어떤 카메라가 있을 때, 그 카메라의 위치에서 특정 방향으로 3D scene의 한 점을 바라볼 때 생기는 직선을 camera ray라고 한다.
임의의 위치에서 임의의 방향으로 3D scene을 통과하는 camera ray자체를 로 표현할 수 있다. 그리고 이 ray가 통과하는 직선상의 각 점에 상응하는 색상과 밀도 값을 바탕으로 적분(volume rendering)을 통해 2d view를 synthesize하는 것이 이 논문의 요지이다.
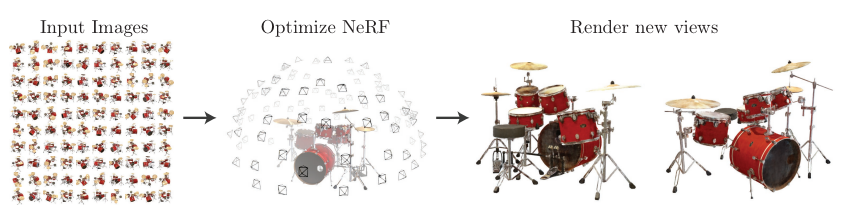
Application
-
3차원 scene이나 object를 voxel이나 point cloud로 표현하는 것은 많은 용량을 필요로 한다. 이에 반해, NeRF를 사용하면 MLP모델만으로 모든 coordinate에서의 view를 renedering할 수 있으므로, 더 효율적이다.(3d 게임이나 VR환경에 적용 가능)
-
3차원 voxel grid뿐 아니라, 심지어 각각의 coordinate에서 rendering한 image들을 저장하는 것보다 NeRF모델이 용량이 더 작다.
1. Neural Radiance Field Representation
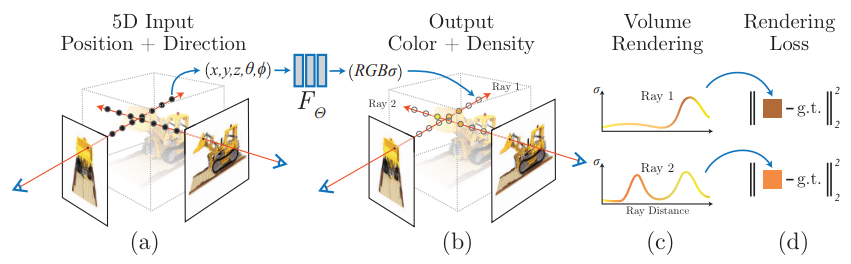
camera ray를 모델링함으로써 scene을 표현하는 함수 는 8 layer MLP로 parameterize 된다. 이 MLP를 학습하기 위해 사용되는 데이터는, 위 사진과 같이 하나의 사물을 multiple view에서 찍은 이미지 - 찍은 위치.각도 의 pair로 구성된다. 하나의 사물에 대한 (Image-coordinate) pair를 사용하여 MLP를 학습한 뒤에는, 임의의 coordinate에서 사물의 view를 2d image로 rendering할 수 있게 된다.
즉, MLP는 특정 scene에 대한 ray 자체를 모델링하는 역할을 하게 되고, 이렇게 학습된 MLP는 input coordinate(위치.방향)을 받아서, 해당 방향의 ray상에 존재하는 점들에 대한 색상과 밀도 를 산출한다. 이렇게 색상.밀도 정보에 대한 volume rendering으로 2d view가 합성되는 것이다.
모델의 세부적인 구조는 아래와 같다.()
어떤 point에서의 density는 사물을 바라보는 위치에는 영향을 받지만, 사물을 바라보는 각도에는 영향을 받지 않으므로, 는 에만 의존하도록 정의된다.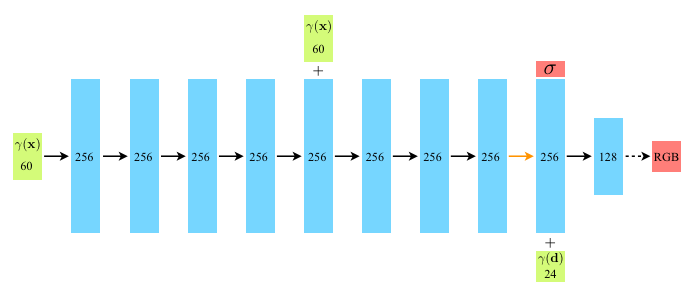
2. Differentiable Volume Rendering
개인적으로 이 부분을 이해하는 게 조금 힘들었다. 결국 를 받아서 를 산출하는 함수(MLP)를 학습하려면, loss가 필요하고 loss가 산출되는 전 과정이 미분가능해야한다.
neural rendering의 전 과정은 아래와 같이 요약할 수 있다.
-> MLP -> -> Volume Rendering -> rendered image
이 섹션에서 소개할 Volume Rendering은 미분가능한 연산들로 구성되어 있다.이 부분(를 바탕으로 rendered image pixel value를 산출하는 방법)에 대해서 자세히 소개하고자 한다.
Notations
- : ray의 시작점(위치 좌표)
- : ray의 진행 방향(각도 좌표)
- : 위치좌표 o에서 시작하여 방향 d로 향하는 직선의 ray상의 한 점
- : ray상의 한 점에서 물체의 밀도
- : ray상의 한 점에서 물체의 색상
- : 각각 ray가 3d scene에 대해 가지는 near bound와 far bound
- : 부터 ray상의 임의의 한 점인 t까지 축적된 투과율(transmittance) - t보다 앞에 있는 점들의 density의 합과 유사한 개념
이러한 요소들을 바탕으로, 특정 ray를 통해 한 픽셀에 대해 rendered된 pixel value 를 아래와 같이 구할 수 있다.
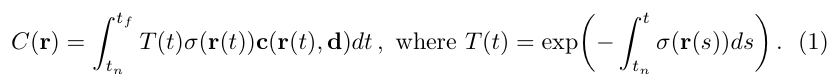
하지만 이 적분을 해석적으로 계산하진 않는다. 본 논문에서는 구적법(quadrature)를 활용하여 이 적분값을 수치적으로 계산한다. 즉, camera ray 상의 모든 연속적인 값들에 대해 해석적인 적분을 계산하는 것이 아니라, 사이의 구간에서 t값을 샘플링하여 수치적분값을 계산하는 것이다.
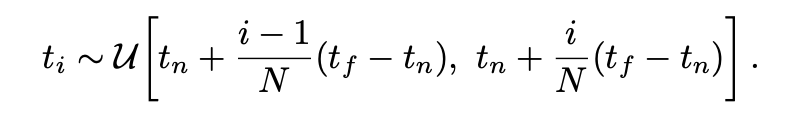 위와 같이 Uniform한 분포를 기준으로 t를 샘플링한다. 수치적분을 이용하게 되면, 위에서 언급한 수식이 아래와 같이 summation(discrete)으로 표현될 수 있다.
위와 같이 Uniform한 분포를 기준으로 t를 샘플링한다. 수치적분을 이용하게 되면, 위에서 언급한 수식이 아래와 같이 summation(discrete)으로 표현될 수 있다.
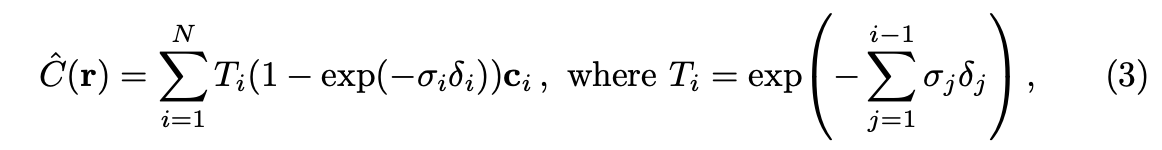
3. Optimizing NeRF(tricks)
3.1. Positional Encoding
하지만 단순히 를 model input으로 넣어주게 되면, color와 geometry의 high frequency variation을 제대로 rendering하지 못하게 된다. 이는 deep network가 low-frequency function을 학습하는 경향이 있기 때문이다. 따라서, 이 문제를 해결하기 위해서는 input을 higher dimensional space로 mapping 해 주어야 한다.
이러한 맥락에서, 본 논문에서는 input coordinate에 해당하는 와 에 아래와 같은 sinusodal positional encoding을 적용하여, high dimensional space로 mapping해준다.
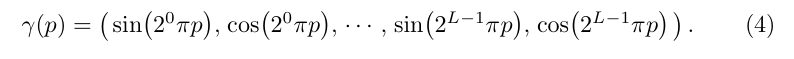
에는 L=10을 적용하여, dimension을 3x2x10 = 60으로 확대하고,
에는 L=4를 적용하여, dimension을 2x2x4 = 16으로 확대한다.

3.2. Hierarchical volume sampling
특정 위치에서의 view를 synthesize하기 위해서는, 한 점에서 여러 방향을 향하는 모든 ray들(픽셀의 개수 만큼에 해당)에 대해 를 산출해야 하고, 각 픽셀 별로 에 대한 수치적분값을 산출함에 있어, 많은 횟수의 샘플링이 필요하다. 이러한 inefficiency를 어느 정도 해결하기 위해, 저자는 hierarchical volume sampling을 제안한다.
기본적으로, 하나의 view synthesis를 수행함에 있어, 개의 pixel들에 대해 을 산출해야 한다. 하지만 3d scene상에서 빈 공간이나 가려진 부분의 픽셀값을 렌더링하는데에 동일하게 많은 횟수의 샘플링을 적용하는 것은 효율적이지 않다.
4. Result

