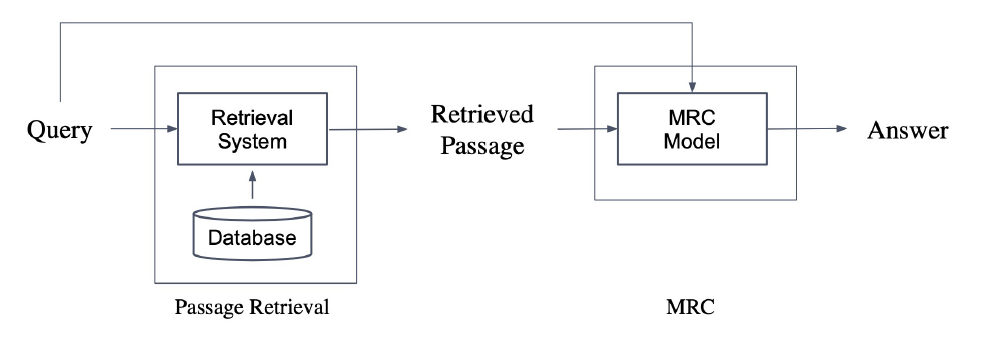
Passage Retrieval는 Open-domain QA task에서 질문에 맞는 문서(Passage)를 찾는 과정을 뜻한다. Open-domain QA는 보통 질문의 답을 얻을 수 있는 문서가 Pair로 주어지지 않고 전체 Corpus안에서 답변을 찾아야 하기 때문에 이런 과정이 필요한 것이다. Passage Retrieval를 통해 Query와 Passage를 임베딩하여 유사도를 매겨 가장 높은 Passage를 선택하는 과정이다. Passage Retrieval를 통해 선정한 Passage를 MRC Model에 넣어서 Answer를 찾는 과정이 Open-domain QA이다.
(1) Passage Sparse Embedding

Passage Sparse Embedding은 문서 내 단어의 빈도수 등의 통계적 지표를 기반으로 임베딩하는 것을 의미한다. 가장 쉬운 예시는 Bag-of-Words(BoW) 인데 문서내 모든 단어들을 사전으로 만들어 그 출현 여부를 binary하게 표시하여 문서의 임베딩을 나타낼 수 있다. 출현 빈도를 계산하는 기준이 되는 단어를 N-gram(unigram, bigram 등)으로 다양하게 옵션을 줄 수 있고 (1), 각 element value를 출현 여부에 따라 binary하게 값을 줄 것인지 아니면 출현 빈도를 값으로 줄 것인지, 혹은 Tf-idf 값을 사용할 것인지 등의 옵션을 사용할 수 있다. 실제로 Tf-idf를 많이 사용하는데 자세한 계산법은 밑에서 알아보도록 하자.
Word2Vec에서 언급했듯이 이런 Sparse Embedding은 크나큰 단점을 가지고 있다. 임베딩 벡터의 dimension이 단어의 개수와 같기 때문에 문서가 많아지고 커질수록 dimension이 커지며 또한 N-gram의 N값이 증가할수록 dimension이 커진다. dimension이 커짐에 비해 대부분의 element가 0의 값을 갖는 경우가 대부분이기 때문에 이는 연산의 측면에서 비효율성을 가진다. 하지만 통계적 지표를 사용하는 만큼 단어 혹은 단어들의 overlap을 정확히 capture 해야할 때는 유용할 수 있다. 하지만 semantic하게 정보를 담는 것은 불가하다. 즉, 동의어가 담긴 문서를 비슷한 임베딩 벡터로 만들기 어렵다는 뜻이다.
1) TF-IDF
단순히 문서내에서 단어의 출현 빈도만으로 임베딩 벡터를 구성하면 전체 문서들에서 단어가 갖는 통계적 의미를 전부 담기는 어려울 것이다. 그렇기 때문에 TF-IDF(Term Frequency - Inverse Document Frequency) 값을 사용한다. 여기서 TF는 단어의 등장빈도를 의미하고 IDF는 단어가 제공하는 정보의 양을 의미한다.
TF는 단순하게 해당 문서 내 단어의 등장 빈도를 값으로 갖지만 문서별 길이를 고려하여 빈도를 해당 문서의 길이로 나눠주는 방식으로 normalization 하기도 한다. IDF는 로 계산하는데, 이때 는 단어 t가 등장한 document의 개수를 의미하고 은 총 doucment의 개수를 의미한다. 즉 어떤 단어가 모든 문서에 자주 등장한다면 이 단어가 가지는 중요도를 낮게 보는 것이다.
최종적으로 document 안의 단어 에 대하여 로 계산하게 된다.
이제 본연의 목적으로 돌아와 Passage retrieval를 수행하기 위해선 어떤 Query 와 문서 에 대해 유사도를 다음과 같이 계산하게 된다.
계산을 통해 가장 높은 score를 가지는 문서를 선택하게 될 것이다.
2) BM25
TF-IDF의 개념과 식을 바탕으로 문서의 길이까지 고려한 점수 계산 방법이다. 이때 TF값에 한계를 두어 일정한 범위를 유지하도록 하고 평균적인 문서의 길이보다 더 작은 문서에서 단어가 매칭된 경우 그 문서에 대해 가중치를 부여하게 된다. 여러 부분에서 TF-IDF를 쓰는 것보다 더 좋아서 현재도 자주 쓰이는 알고리즘이다. 식은 다음과 같다.
은 TF의 값을 scaling해주는 역할이며 는 평균보다 적은 길이의 문서에게 가중치를 주는 역할이다.
(2) Passage Dense Retrieval
Sparse Embedding의 단점을 위에서 언급했지만 사실 dimension 크기가 큰 것은 matrix factorization 등의 차원 축소를 통해 극복할 수 있다(완벽히는 아니지만). 하지만 유사성을 고려하지 못하는건 극복할 수 없는 치명적인 단점이다. 예를 들어 동의어를 쓰거나 paraphrasing된 문서를 비슷한 임베딩 벡터로 나타내기 어렵다는 것이다.
이를 위해 Word2Vec처럼 더 작은 차원의 고밀도 벡터이자 대부분의 요소가 non-zero값인 Dense Passage 임베딩 벡터의 필요성이 대두되었다. Dense 임베딩을 사용하면 똑같은 단어나 문장구조를 쓰지 않아도 그 맥락을 충분히 임베딩벡터에 녹여낼 수 있다는 장점을 가진다. 또 학습을 통해 임베딩 벡터를 만들기 때문에 specific task에 따라 추가적으로 학습이 가능하다는 장점도 가진다. Pretrained-model을 활용하면 이런 approach를 쉽게 적용할 수 있다.
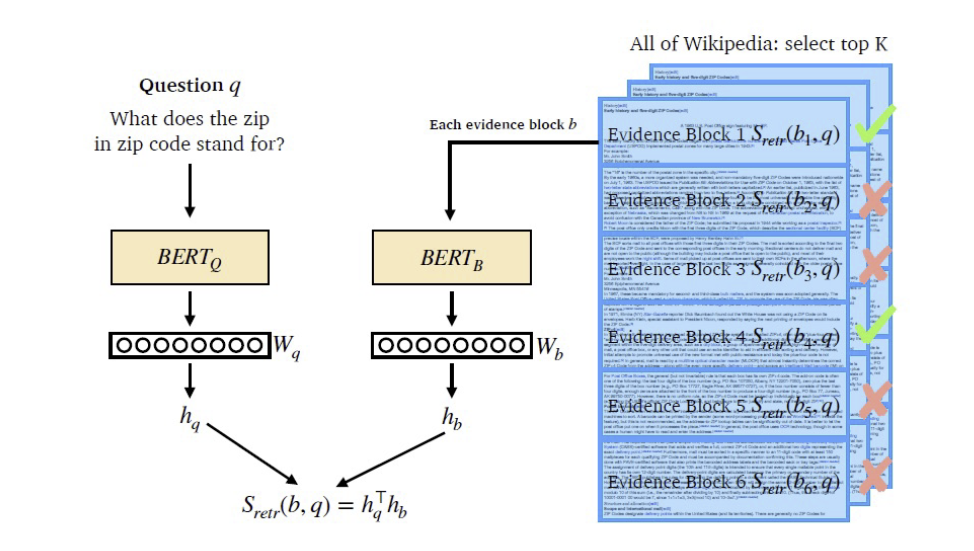
현재 가장 주가 되는 방법은 Encoder 계열의 모델(BERT)을 Query와 Passage별로 각각 만든 후 [CLS] 토큰의 출력값인 hidden state vector를 내적하는 방식으로 유사도를 구하는 방법이다. 유사도를 구하는 방식은 inner product 외에도 nearest neighbor, cosine distance 등 여러 방법이 있을 수 있다.
이 Encoder를 훈련시키려면 어떻게 해야할까? 방법은 기존 MRC 데이터셋을 활용하는 것이다. 기존 MRC 데이터셋은 Query와 Answer를 얻을 수 있는 Passage가 pair로 잘 정돈되어있다. 따라서 해당 Query와 Passage의 유사도가 높도록 학습시키면 되는 것이다. 하지만 이렇게만 하면 데이터가 부족하여 충분히 학습되기는 어려울 수 있다. 따라서 추후 이 논문에서 제안된 방법이 바로 Negative Sampling 이다. Word2Vec에서 본 적이 있는 이 Negative Sampling은 같은 매커니즘을 사용한다. 하나의 쿼리에 대해 pair로 등장하는 passage인 Positivie Passage와 연관이 없는 다른 Passage들인 Negative Passage들을 모아 하나의 train pair를 형성하게 되고 이를 loss 연산에서 한꺼번에 반영하게 된다. 전체 훈련 데이터셋의 정의와 loss 식은 다음과 같다.
이때 은 기존 MRC 데이터셋의 instance 개수를 의미하고 은 지정한 Negative sample 개수를 의미한다.
Negative Sample은 그럼 어떻게 뽑을 수 있을까? 간단하게는 Corpus 내에서 랜덤하게 뽑을 수 있다. 그러나 모델에게 좀 더 어려운 숙제(?)를 주기 위해 Query와 높은 BM25 score를 가지지만 답을 포함하지 않는 Passage들을 Negative sample로 사용할 수 있다. 또 Gold라고 칭하는 방법으로, 기존 MRC 데이터셋의 다른 쿼리와 pair를 맺은 Passage들을 사용할 수도 있다.
이후는 동일히다. Sparse Embedding 처럼 가장 유사도가 높은 Passage를 Query와 함께 MRC 모델에 넣어 답을 찾으면 된다.
Dense Retrieval은 아직 개선의 여지가 더 남아있다. 학습 방법을 더 개선할 수도 있고, Encoder로 사용하는 모델을 더 좋은 모델로 변경할 수도 있다. 당연히 데이터를 개선하는 것도 좋은 방법이다.
