(1) Passage Retrieval - Scaling Up
1) Passage Retrieval and Similarity Search
Dense Retrieval이던 Sparse Retrieval이던 Passage Embedding이 잘 끝났다면 다음은 Query와 Passage간의 Similarity가 높은 매칭을 찾는, 즉 Similarity Search가 필요하다. 크게 두 단계로 생각해 볼 수 있는데, 방대한 양의 Passage Embedding 벡터들을 계산해서 저장해놓는 Indexing과 Indexing 된 벡터들 중 질문 벡터와 가장 유사도 점수(similarity score)가 높은 상위 k개의 벡터를 찾는 과정인 Search로 나뉘게 된다. 이전에는 Exhaustive Search로 모든 Passage에 대해서 일일히 유사도 점수(내적 등)을 계산했지만 Passage들은 말 그대로 방대하기 때문에 time-efficient하고 memory-efficient한 scheme이 필요하다.
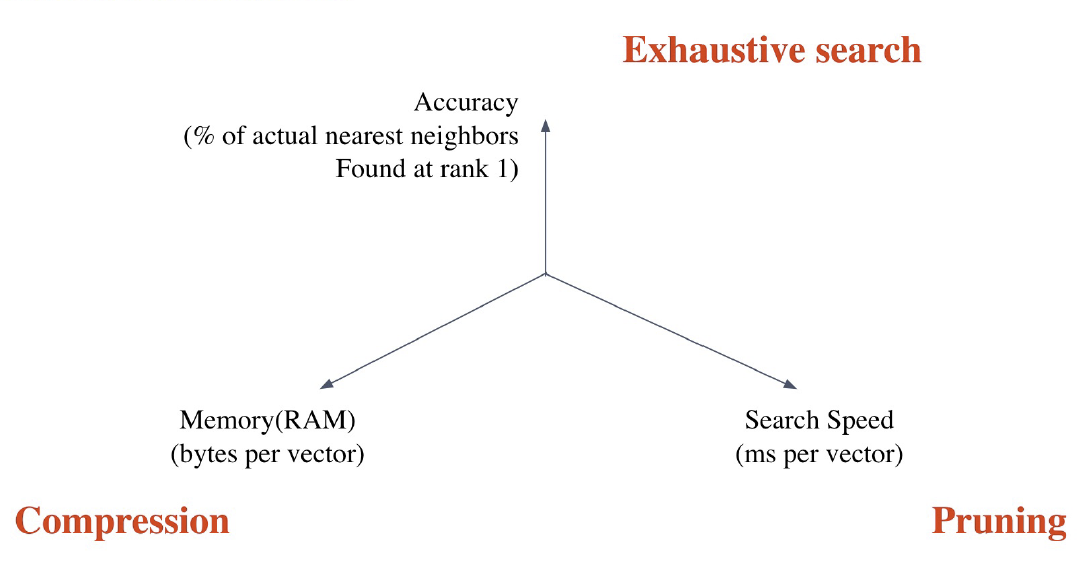
Similarity Search에서 크게 세 가지의 Trade-off를 생각해 볼 수 있다.
Search Speed
쿼리 당 유사한 벡터를 k개 찾는데 얼마나 걸리는지에 대한 부분이다. Pruning 등 Search 알고리즘을 개선하면 해결할 수 있는 부분이다.
Memory Usage
모든 Passage 벡터들을 어디에 올려놓고 사용할 것인지에 대한 부분이다. RAM을 이용한다면 빠르겠지만 많은 RAM 용량을 요구하기 때문에 썩 내키지는 않는다. 그렇다고 디스크에서 불러오기엔 속도가 너무 느리다. 이는 Compression으로 일부 개선할 수 있다.
Accuracy
Exhaustive Search와 얼마나 비슷한지에 대한 부분이다. 즉 모든 Passage를 일일이 확인한 것 대비 얼마나 정확도가 떨어지느냐에 대한 문제인 셈이다. 속도를 높이려면 아무래도 정확도를 희생해야 할 것이다.
2) Approximating Similarity Search
위의 trade-off들을 해결하고 절충하기 위해 각 trade-off 별로 해결방안이 제시되었다.
Compression - Scalar Quantization(SQ)
메모리 부분 문제를 해결하기 위해 각 벡터를 압축하여 용량을 줄이는 방법이다. 당연히 압축의 정도가 크면 클수록 정보의 손실 정도는 커질 것이기 때문에 적절한 압축정도를 정하는 것이 중요하다.
Compression의 대표적인 예로 Scalar quantizaiton이 있는데 이는 예를 들어 4-byte floating point를 1-byte (8-bit) unsigned integer로 압축하는 등의 Quantization을 의미한다.
Pruning - Inverted File(IVF)
Pruning이란 기본적으로 Search space를 줄여 search 속도를 개선하는 것이다. Search Space를 줄인다는 것은 곧 모든 데이터를 다 확인하는 것이 아니라 그 subset만 확인하는 것을 의미한다.
이를 위해 사용되는 방법은 Clustering + Inverted File이다. Clustering은 k-means clustering 같은 머신러닝 알고리즘을 통해 전체 vector space를 k 개의 cluster로 나누는 것이다. 그리고 Inverted File은 벡터의 index를 inverted list 형태로 저장하는데 이때 index를 전체 Passage index가 아닌 각 cluster의 centroid id와 해당 cluster 내의 각 벡터들의 index로 정의하게 된다. 이러한 과정을 Inverted File이라고 한다.
Task에 이를 적용하면, 우선 주어진 query vector에 대해 근접한 centroid 벡터를 찾은 뒤 해당 cluster의 inverted list 내 vector들에 대해 search를 수행하게 된다. 이렇게 하면 훨씬 적은 데이터를 탐색하면서 정확도를 어느정도 확보할 수 있다.
3) FAISS
위의 과정들을 직접 손으로 구현하는 것은 여간 어려운 일이 아니다. 다행히도 Facebook AI에서 이를 코드 몇 줄만으로 손쉽게 처리해주는 Tool을 제공하고 있다.
import faiss
num_clusters = 16 # Vector space를 몇개로 쪼갤 것인지
k = 5 ## 상위 몇 개의 유사한 Passage를 찾을 것인지
emb_dim = p_embs.shape[-1] ## Passage Embedding dimension
quantizer = faiss.IndexFlatL2(emb_dim)
indexer = faiss.IndexIVFScalarQuantizer(quantizer, quantizer.d, num_clusters, faiss.METRIC_L2)
indexer.train(p_embs)
indexer.add(p_embs)
D, I = indexer.search(q_embs, k) ## q_embs = query embedding위에서 설명한 전체 과정을 코드를 통해서 쉽게 계산하여 각 쿼리에 대한 상위 k개의 Passage 벡터들의 인덱스 I와 L2 distance D를 얻을 수 있다. 물론 적절한 num_clusters의 값을 지정하는 것이 가장 중요하겠지만 적절한 하이퍼파라미터 값을 설정하면 효율적으로 Similarity Search가 가능하다.
(2) Linking MRC and Retrieval
앞에서 배운 Reader와 Retriever를 연결해야한다. 우선 정리해보자면
- Retriever
- 입력 : Document or Passage corpus, Query
- 출력 : 관련성 높은 Passage
- Reader
- 입력 : Retrieved된 Passage, Query
- 출력 : Answer
Retriever는 TF-IDF나 BM25같은 Sparse Retrieval를 사용할 경우 학습이 필요없지만 Dense Retrieval의 경우 학습이 필요하다. Reader의 경우 SQuAD와 같은 MRC 데이터셋으로 학습하는데, 이 학습 데이터를 추가하기 위해 Distant Supervision을 사용한다. Distant Supervision의 기본적인 정의는 부족한 label의 데이터에 대해 unlabeled 된 텍스트나 데이터로부터 도메인에 맞는 labeled 데이터를 생성해내는 것을 의미한다.
Distant Supervision은 본래 관계추출 Task에서 주어진 Entity들 간의 관계를 바탕으로 이를 변형해가며 문장을 생성해 여러 relation의 데이터를 만드는 것을 목적으로 NLP에서 사용되었다. QA 에서는 context 없이 질문과 답만 주어진 몇몇 Dataset에 대하여 Evidence로 활용할 Context를 찾아서 MRC dataset에 추가할 목적으로 사용되었다. MRC dataset의 경우 데이터 수가 적은 경우가 많고 context가 주어졌을 때 정답을 맞출 확률이 훨씬 높기 때문에 이런 방법이 적용된 것으로 보인다.
다시 돌아와 Retriever-Reader의 Inference 과정에서는 Retriever가 주어진 Query에 대해 top k의 문서들을 출력하고 Reader는 이 문서들을 읽고 Answer span을 찾게된다. 이 중 가장 score가 높은 것(확률)을 최종 답으로 사용한다.
Issues & Recent Approaches
Different granularities of text at indexing time
쉽게 Passage라고 얘기했지만 사실 이 Passage의 범위를 어떻게 잡을 것인지는 Task마다 다를 것이다. 문서 전체를 Passage로 정의할 수도 있고 더 세분화해서 단락 또는 문장을 하나의 Passage로 정의할 수 있다. 세분화 할 수록 당연히 Passage 수는 불어날 것이다. 문장으로 나눈다고 생각해보면 정답을 포함하고 있는 문장에 대해 Distance가 많이 가깝게 나와 Clustering이나 Search에서 쉽게 답을 찾을 수 있을 거 같다는 생각이 들지만, 한 문장 만으로 정답 관계를 추론하기 어려운 질문도 있기 때문에 쉽게 단정할 수는 없는 문제이다. 또한 Top-k를 결정함에 있어 세분화 할 수록 k의 값을 크게 늘려주어야 할 것이다.
Single-passage Training vs Multi-passage Training
지금까지 설명했던 Passage Retrieval는 Single-passage Training이다. 즉, k개의 Passage들을 reader가 확인하고 특정 answer에 대한 예측 점수들을 모아 가장 높은 점수를 가진 answer span을 고르도록 하는 것이다. 하지만 이것이 각 retrieval passage들에 대한 직접적인 비교라고 보기는 어렵다는 것이다. 따라서 이를 각각 따로 보지 않고 하나의 긴 Passage로 concatenate하여 Reader 모델이 그 안에서 answer span 하나를 찾는 방식으로 하는 것이 Multi-passage Training이다. 하지만 문서가 너무 길어지기 때문에 GPU 메모리 문제도 발생하고 연산량도 그만큼 늘어나는 단점이 있다.
Importance of each passage
End-to-End Open-Domain Question Answering with BERTserini에서 제시한 방법인데, Answer의 점수를 매기는 과정에서 Span score, 즉 MRC 모델의 Span 위치 확률에 따른 점수만 고려하는 것이 아닌 처음 Passage Retrieval에서 top-k의 문서들을 뽑을 때 매겨졌던 similarity score까지 고려한다는 것이다. 이렇게 했을 때, 가장 연관성이 높다고 여겨진 문서에서 정답을 뽑아낼 확률을 조금 더 높일 수 있는 것이다.
