
02. Numpy
2-1. numpy 배열 연산
import numpy as np배열 간 연산 (1차원)
a1 = np.array([1, 2 ,3])
a2 = np.array([4, 5, 6])
print(a1 + a2)
print(a1 - a2)배열 간 연산 (2차원)
a1 = np.arange(1, 5).reshape(2, 2)
a2 = np.arange(11, 15).reshape(2, 2)
print(a1)
print(a2)
print(a1 + a2)
print(a2-a1)
# 배열과 스칼라 연산 (1차원)
a1 = np.array([1, 2, 3, 4])
print(a1 + 10)
print(a1 * 2)
# 배열과 스칼라 연산 (2차원)
a1 = np.arange(1, 5).reshape(2, 2)
a2 = np.arange(11, 15).reshape(2, 2)
print(a1)
print(a2)
print(a1 + 5)
print(a2 * 3)
print(a2 / 2)
# 배열의 구조가 다를 경우
a1 = np.array([1, 2])
a2 = np.array([1, 2, 3])
# print(a1 + a2) # ValueError: 행렬의 크기가 맞지 않아 오류 발생브로드캐스팅
- 자동으로 배열의 크기를 확장 -> 서로 다른 크기의 배열 간 연산을 가능하게 하는 기능
- 두 배열의 차원을 뒤(낮은 차원)에서부터 비교
- 크기가 같거나
- 한 쪽이 1인 경우 확장이 가능
a1 = np.array([[1, 2, 3,],
[4, 5, 6]]) # (2, 3)
a2 = np.array([10, 20, 30]) # 길이가 3인 1차원 배열 (3, )
# 1차원 길이 3
[10, 20, 30]
# 2차원으로 변형(1, 3)
[[10, 20, 30]]
# 2차원의 행이 2 -> 2로 확장
[[10, 20, 30],
[10, 20, 30]]
print(a1 + a2)
# 브로드캐스팅 예제
a1 = np.array([[1], [2], [3]]) # (3, 1)
a2 = np.array([10, 20, 30]) # (3, )
# a2: (3, ) -> (1, 3)로 변환됨
[[10, 20, 30]]
# a1과 a2 비교 -> (3, 1), (1, 3)
[[1, 1, 1], [2, 2, 2], [3, 3, 3]]
[[10, 20, 30], [10, 20, 30], [10, 20, 30]]
print(a1 + a2)실습 1-1
arr = np.array([1, 2, 3, 4])
print(arr + 3)결과

실습 1-2
arr = np.array([[5, 10],
[15, 20]])
print(arr * (-1))결과
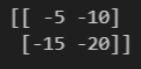
실습 1-3
arr1 = np.array([2, 4, 6])
arr2 = np.array([1, 2, 3])
print(arr1 * arr2)
print(arr1 / arr2)결과
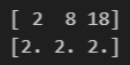
실습 1-4
arr = np.array([[95, 97],
[80, 85]])
print(100 - arr)결과
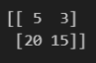
실습 1-5
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr[0, :] * 10, arr[1, :] * 100)결과

실습 1-6
arr = np.array([[10, 20],
[30, 40],
[50, 60]])
arr1d = np.array([100, 200, 300]).reshape(3, 1)
print(arr + arr1d)결과
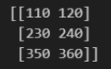
2-2. 통계 함수 및 집계 연산
a = np.array([[1, 2, 3], [4, 5, 6]])
print("원소의 합:", np.sum(a))
print("원소의 평균", np.mean(a))
print("표준편차:", np.std(a))
print("최댓값:", np.max(a))
print("최솟값:", np.min(a))
print("최댓값의 인덱스:", np.argmax(a))
print("최솟값의 인덱스:", np.argmin(a))결과
축(axis) 단위 연산
axis = 0 -> 가장 높은 차원 기준 -> 행 기준
- 행 기준 = 행을 따라 연산 = 행을 증가시키며 연산
axis = 1 -> 그 다음에 가장 높은 차원 기준 -> 열 기준
- 열 기준 = 열을 따라 연산 = 열을 증가시키며 연산
a = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print("행기준 합", np.sum(a, axis = 0))
print("열기준 합", np.sum(a, axis = 1))
print("행기준평균", np.mean(a, axis = 0))
print("열기준평균", np.mean(a, axis = 1))
# 누적 연산
arr = np.array([1, 2, 3, 4])
print(np.cumsum(arr))
print(np.cumprod(arr))실습 2-1
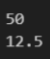
arr = np.array([5, 10, 15, 20])
print("합",np.sum(arr))
print("평균", np.mean(arr))결과
실습 2-2
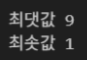
arr = np.array([[3, 7, 1],
[9, 2, 8]])
print("최댓값", np.max(arr))
print("최솟값", np.min(arr))결과

실습 2-3
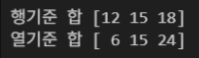
arr = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print("행기준 합", np.sum(arr, axis = 0))
print("열기준 합", np.sum(arr, axis = 1))결과
실습 2-4
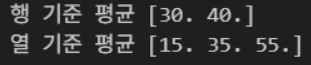
arr = np.array([[10, 20],
[30, 40],
[50, 60]])
print("행 기준 평균", np.mean(arr, axis = 0))
print("열 기준 평균", np.mean(arr, axis = 1))결과
실습 2-5
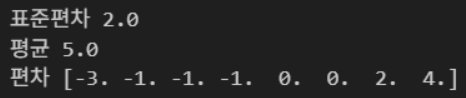
arr = np.array([2, 4, 4, 4, 5, 5, 7, 9])
print("표준편차", np.std(arr))
print("평균", np.mean(arr))
print("편차", arr - np.mean(arr))결과
실습 2-6
arr = np.array([[1, 2, 3],
[4, 5, 6]])
print("행 단위 누적 합", np.cumsum(arr, axis = 0))
print("열 단위 누적 곱", np.cumprod(arr, axis = 1))결과

2-3. 논리 연산과 조건 연산
np.where()
- 조건 기반 선택 함수
arr = np.array([10, 20, 30, 40, 50])
result = np.where(arr > 30, "High", "Low")
result
arr = np.array([10, 20, 30, 40, 50])
# 조건만 넣을 경우 조건을 만족하는 원소의 인덱스르 반환
result = np.where(arr > 30)
print(result)
print(arr[result]) # Fancy Indexing논리 연산
- and: & - 모든 조건이 True여야 True
- or: | - 모든 조건 중 하나라도 True면 True
- not: ~ - 조건 반대 값
# and 연산 (&)
arr = np.array([10, 20, 30, 40, 50])
mask_and = (arr > 10) & (arr < 50)
print("&연산", arr[mask_and])
# or 연산 (|)
mask_or = (arr < 20) | (arr > 40)
print("|연산", arr[mask_or])
# not 연산 (~)
mask_not = ~(arr > 30)
print("~연산", arr[mask_not])실습 3-1
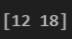
arr = np.array([5, 12, 18, 7, 30, 25])
print(arr[(arr > 10) & (arr < 20)])결과
실습 3-2
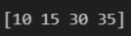
arr = np.array([10, 15, 20, 25, 30, 35])
print(arr[(arr <= 15) | (arr >= 30)])결과
실습 3-3
arr = np.array([3, 8, 15, 6, 2, 20])
arr[arr >= 10] = 0
print(arr)결과

실습 3-4
arr = np.array([7, 14, 21, 28, 35])
result = np.where(arr >= 20, "High", "Low")
print(result)결과

실습 3-5
arr = np.arange(0, 10)
arr_odd = np.where(arr % 2 == 0, arr * 10, arr)
print(arr_odd)결과

실습 3-6
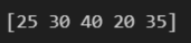
arr = np.array([[10, 25, 30],
[40, 5, 15],
[20, 35, 50]])
arr_condition = np.array(arr[(20 <= arr) & (arr <= 40)])
print(arr_condition)결과
실습 3-7
arr = np.array([1, 2, 3, 4, 5, 6])
# arr_3 = np.where(arr[arr % 3 != 0])
print(arr[arr % 3 != 0])결과

실습 3-8
arr = np.arange(0, 100).reshape(10, 10)
arr_change = np.where(arr >= 50, arr, 50)
print(arr_change)결과

실습 3-9
arr = np.array([[5, 50, 95],
[20, 75, 10],
[60, 30, 85]])
arr_change = np.where(arr >= 70, "A", np.where(arr >= 30, "B", "C"))
print(arr_change)결과

2-4. 행렬 곱셈
- 두 행렬을 곱해서 새로운 행렬을 생성하는 연산
- 첫 번째 행렬의 열수와 두 번째 행렬의 행수가 같아 야 곱셈이 가능함
- np.dot(), np.matmul() 사용
np.dot(a, b): 배열의 내적 연산
# 스칼라 연산(OD)
a = np.array(3)
b = np.array(4)
print(np.dot(a, b))
# 1차원 배열 간 연산 -> 내적
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(np.dot(a, b))
# 물건 구매
# 데이터 분석에서 벡터랑 배열
c = [1000, 2000, 5000, 10000]
d = [10, 3, 5, 7]
print(np.dot(c, d))
# 2차원 배열간 연산 -> 행렬 곱셈
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([[1, 2], [3, 4], [5, 6]])
print(np.dot(a,b))np.matmul(a, b)
- Matrix Multiplication
- 스칼라 연산 시도 시 에러
a = np.array(3)
b = np.array(4)
# print(np.matmul(a, b))1차원 배열간 연산 -> 내적
a = np.array([1, 2])
b = np.array([3, 4])
print(np.matmul(a, b))2차원 배열간 연산 -> 행렬 곱셈
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([[1, 2], [3, 4], [5, 6]])
print(np.matmul(a,b))
# 2차원 * 1차원 간 연산
c = np.array([[1, 2], [3, 4]])
d = np.array([5, 6])
print(np.matmul(c, d))
print(np.matmul(d, c))
# @ 연산자
e = np.array([[1, 2, 3]])
f = np.array([[1, 2],
[3, 4],
[5, 6]])
print(np.matmul(e, f))
print(e @ f)실습 4-1
A = np.arange(1, 10).reshape(3, 3)
B = np.full((3, 2), 2)
print(A)
print(B)
print(np.matmul(A, B))결과
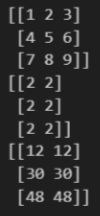
실습 4-2
I = np.eye(4, 4)
M = np.random.randint(0, 9, (4, 4))
print(np.matmul(I, M))
print(M)결과
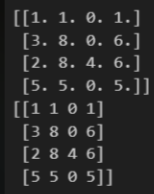
실습 4-3
X = np.ones((2, 5))
Y = np.arange(5, 15).reshape(5, 2)
print(X @ Y)결과
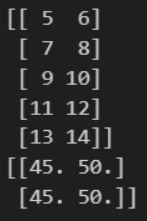
실습 4-4
C = np.random.randint(0, 5, (3, 2))
D = np.random.randint(0, 5, (2, 3))
print((np.matmul(C, D)).shape)결과
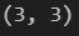

동윤2입니다.