ai 이론에 대해서 마저 작성하겠다.
-
퍼셉트론
:여러개의 입력을 받아 각각의 값에 가중치를 곱한 후, 모두 더한 것이 출력되는 형태의 모델
:아주 단순한 모델이며 , 실제 문제에서 적용되는 경우도 거의 없다. 하지만 신경망이나 딥러닝의 뿌리가 되는 모델
:하나의 선으로 분류할 수 없는 선형분리 불가능 문제, 즉 퍼셉트론 알고리즘은 너무도 단순한 모델이기에, 선형적으로 구분되지 않는 데이터 셋에는 수렴하지 못한다는 치명적인 단점이 있다. -
로지스틱 회귀
:분류를 확률로 생각하는 방식
:퍼셉트론의 간단함은 유지하고 이러한 분류문제를 해결할 수 있는 모델이 로지스틱 회귀

:z가 무한대로 커지면 지수함수의 값이 0에 가까워져 시그모이드 함수값이 1이되고 z가 무한대로 작아지면 지수함수의 값이 무한이 커져서 시그모이드 함수값이 0이 됨. 결국 어떠한 입력값이 들어와도 0~1사이의 값을 반환하게 되는 것으로, 이를 확률처럼 다룰 수 있음. 함수의 중간값은 0.5
하나의 직선으로 분류할 수 없는 문제→ 곡선을 사용하게 되면 조금 더 분류가 쉬워지지 않을까? 차수 늘려주기-> 곡선 형태로 결정경계가 구축됨. -
서포트 벡터 머신 (Support Vector Machine)
:SVM 의 목적은 마진을 최대화 하는 것
:우선 이 알고리즘은 레이블을 구분하기 위한 초평면(결정경계)를 그림.
:그 다음. 이 초평면은 마진 이란 것을 구하는데, 마진은 초평면과 가장 가까운 훈련 데이터들 사이의 거리로 정의한다. 이러한 데이터들을 서포트 벡터라고 한다.⭐분류가 목적이라면 로지스틱 회귀만으로도 충분한데 굳이 이렇게 큰 마진의 결정 경계를 원하는 이유는?
:일반화를 진행했을 때 오차가 낮아지는 경향이 있다는것이 밝혀짐:서포트 머신이 강력한 이유 중 또다른 이유는 선형 분리 불가능 문제에서도 강력한 힘을 발휘한다는 점이다. 2차원에서만 존재했던 데이터들이 3차원 공간으로 옮겨져 오면서 모델은 이 데이터들을 분류하기 위한 분리 가능 공간을 생성하게 된다. 이를 다시 2차원 공간으로 옮겨오게 되면 이렇게 비선형 결정경계로 바뀌게 됨
:서포트 벡터 머신의 단점은 계산비용
:2차원 공간에 분포한 데이터를 3차원 공간으로 매핑하다 보니 새로운 특성을 만들어야 하고 이러한 과정 속에서 상당한 컴퓨팅 파워가 필요. 그래서 이러한 높은 비용을 조금이나마 절감하고자 소위 커널 기법이 등장하게 됨. 이후 다수의 연구자들은 이 강력한 머신러닝 모델로 상당한 성과를 이뤄내기 시작함. 이러한 머신러닝은 대체로 설명이 가능하고, 대체로 높은 정확도를 이끌어냄 -
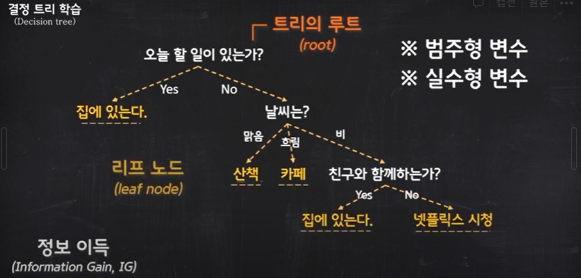
결정 트리
:일련의 질문에 대한 결정을 통해 데이터를 분해하는 모델
:훈련 데이터에 있는 변수 즉 특성을 기반으로 새로운 샘플의 클래스 레이블을 추정할 수 있도록, 일련의 질문을 학습하게 된다.
:실수형 특성에도 적용된다는 점이 매력적

:트리의 루트부터 시작해 정보이득이란 값이 최대가 되는 특성으로 데이터를 나눔. 이러한 결정을 리프노드가 순수해질때까지 모든 자식노드에서 이 분할작업을 반복
:하지만 이와 같은 분할 작업을 계속해서 하다보면 깊은 트리가 만들어지게 되는데, 이는 곧 과적합을 불러일으키게됨. 그래서 일반적으로 트리의 최대 깊이를 제한하여 트리를 가지치기 함. -
정보이득(IG)
:(부모 노드의 불순도 - 자식 노드의 불순도)의 합
:자식노드의 불순도가 낮을수록 정보이득은 커진다.
:대부분의 라이브러리들은 구현을 간단하게 하고 탐색공간을 줄이기 위해 이진 결정 트리를 사용함.
:이진 분류를 하기 위해서는 어떠한 분할 조건 혹은 불순도 지표를 사용해야함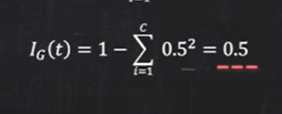
위는 대표적인 불순도 지표 3가지
- 엔트로피
한 노드의 모든 데이터가 같은 클래스라면 엔트로피는 0, 반대로 클래스 분포가 균등하다면 엔트로피는 최대 1
반대로 특정 노드 t에서 클래스 i가 1 또는 2고, 속한 비율이 각각 0.5로 균등하게 분포하면 엔트로피 값은 1이다.
!! 트리의 상호 의존 정보를 최대화 하는 것 !!
이진트리일때 최댓값
❗실제로 지니 불순도와 엔트로피 모두 매우 비슷한 결과를 나타냄
그래서 지니 불순도나 엔트로피를 바꿔가며 트리 평가를 진행하기 보다는 가지치기 수준을 바꿔가며 튜닝하는 것이 권장됨
- 분류 오차
:
: 노드의 클래스 확률 변화에 둔감하기 때문에 권장되지 않음
이렇게 구한 계수들을 바탕으로 분할된 노드에서 다시 특정 분류 기준에 의해 다시 자식 노드를 생성하고 이를 바탕으로 또다시 불순도를 구하며 가지를 뻗어 나간다. 그리고 최종적으로 불순도가 0에 수렴할 때까지, 즉, 하나의 클래스만을 가진 노드가 될 때까지 이를 반복해서 진행함. 무한으로 반복하다보면 과적합을 불러일으키기 때문에 가지가 뻗어 내려가는 수준을 지정해 줘야 한다.
-
K-최근접 이웃 (KNN)
:지금까지 봐왔던 알고리즘은 올바른 매개변수를 찾기 위한 학습과정을 진행. 하지만 이 알고리즘은 훈련과정을 진행하지 않는 머신러닝 모델
:알고리즘을 실행할때 마다 모든 학습데이터를 통해 분류를 진행 -> 매번 실행할 때마다 학습 데이터 필요
:고차원의 데이터로 훈련을 진행한다면 계산 복잡도 또한 훈련 데이터의 갯수에 비례하여 증가하는 경우도 발생
:그럼에도 KNN은 데이터 정제만 잘 해준다면 학습과정이 없으니, 빠르게 결과를 살펴볼 수 있다는 장점이 있음
: 순서
1. 숫자 k와 거리 측정 기준을 선택한다(유클리디안 거리 측정 방식)
2. 분류하려는 미지의 데이터에서 k개의 최근접 이웃을 찾음
3. 다수결 투표를 진행, 투표 결과에 따라 미지의 데이터 클래스 레이블을 할당:이 알고리즘의 핵심은 과적합과 과소적합 사이에서 올바른 균형을 잡기 위한 K값 설정이 그 무엇보다 중요하다. 또한 차원의 저주를 피하기 위해 올바른 변수의 선택, 차원 축소 기법 등을 사용해 주면 된다
