ai 이론에 대해서 마저 작성하겠다.
-
덴드로그램
:덴드로그램은 의미있는 분류체계를 만들어 줌으로1. 결과를 이해하는데 도움이 되고, 2. 누군가에게 군집결과를 설명하기에도 적합하다. 3. 클러스터의 수를 미리 지정하지 않아도 된다 -
계층 군집
:계층 군집을 형성하는 방법에는 병합 계층 군집과 분할 계층 군집 두 가지가 있다.
:분할 계층 군집은 전체 데이터를 포함하는 하나의 클러스터에서 시작해, 클러스터 속 데이터가 하나가 남을 때까지 반복적으로 클러스터를 나눈다.
:반면 병합 계층 군집은 이와는 밭대로, 클러스터당 하나의 데이터에서 시작하여, 모든 데이터가 하나의 클러스터에 속할 떄까지 가장 가까운 클러스터를 병합해 나간다.:이 병합 계층 군집을 이루는 두 가지 기본 알고리즘에는 4가지 연결 방법이 있는데,
1. 단일 연결을 사용하면 클러스터 쌍에서 가장 비슷한 즉, 가장 가까운 데이터 간의 거리를 계산한다. 그 다음, 그 거리의 값이 가장 작은 두 클러스터를 하나로 합치게 된다. 2. 완전연결 방식은 클러스터 쌍에서 가장 비슷하지 않은 데이터, 즉 가장 멀리 있는 데이터를 찾아 거리를 구한 후 가장 가까운 두 클러스터를 합쳐준다 3. 평균연결은 두 클러스터에 있는 모든 샘플 사이의 평균 거리가 가장 작은 클러스터 쌍을 합치는 방식. 4. 와드 연결법은 클러스터 내 SSE(두 군집이 합쳐졌을 떄의 제곱 오차합)이 가장 작게 증가하는 두 클러스터를 합치는 방법이다.
:완전연결 방식을 사용하기 위해 linkage함수를 호출. 이때 무작정 sqareform 함수를 통과시킨 데이터를 넣게 되면 우리가 기대한 값과는 다른 결과가 출력되기에
1. pdist 함수에서 축약된 거리 행렬을 입력 속성으로 사용할 수 있으며,
2. 아니면 linkage 함수에서 초기 데이터 배열을 전달하고 'euclidean'지표를 매개변수로 사용할 수 있다고 함
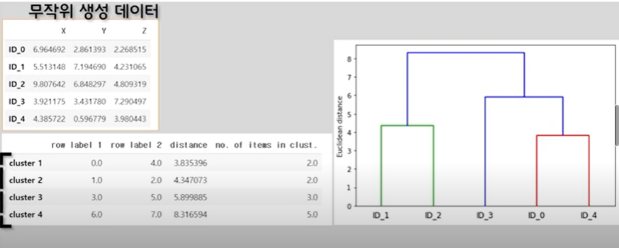
:표에 의하면 우리가 무작위로 선정한 다섯개의 데이터는 총 4개의 군집을 이뤘음을 알 수 있다. 첫번 째와 두 번째열은 각 클러스터에서 완전 연결방식으로 병합된 클러스터를 나타내는데, 첫번째 클러스터의 경우 데이터 라벨명인 ID_0와, ID_4가 병합되었다는 것을 알려주고 세번째 열은 클러스터 간 거리를 의미함. 첫번 째 클러스터의 경우 거리가 3.83, 그리고 4번째 열은 이 군집에 속한 데이터의 수는 2개라고 말해줌. ID_5는 ID_0과 ID_4가 병합한 클러스터의 명칭이 되는 것.
:덴드로그램 함수에 연결행렬을 넣어주면 됨. 그러면 이렇게 각 클러스터마다 색깔로 구분되는 덴드로그램을 얻어낼 수 있다. 이러한 시각적인 결과물은 확실히 앞에서 확인한 수칙적인 결과물과 함께 쓰였을 때 더 강력한 위력을 발휘하며, 이것이 바로 시각화가 가진 강점이 아닐까...-
히트맵
:일정한 이미지 위 혹은 측면에 열 분포 형태로 데이터를 효과적으로 표현하는 시각화 기법이다.
:히트맵과 덴드로그램이 함께 쓰이게 되면 데이터 행렬의 개별 값을 색으로 표현할 수 있게 되고, 각 데이터셋을 조금 더 효과적으로 요약할 수 있다. -
밀집도 기반 군집
:이 알고리즘은 k-means 처럼 원형 클러스터를 가정하지 않는다. 이는 군집을 형성하는데 있어 생각보다 강력한 위력을 발휘함
:밀집도란 특정 반경 안에있는 샘플의 개수로 정의1. 첫 번째, 어떠한 데이터의 특정 반경(입실론) 안에 있는 이웃점이 우리가 임의로 지정한 개수(minpts)이상이면 이 데이터는 중심점이 됨 2. 두번째, 다음으로 가장 가까운 점 기준, 특정 반경 이내에 지정된 개수보다 이웃은 적지만, 다른 중심점의 반경 안에 있으면, 이는 경계점이 된다 3. 세 번째, 이러한 방식으로 점들을 할당하고 나서 그 어떠한 점에도 속하지 않는 모든 점들은 이상치가 된다.:이렇게 중심점, 경계점, 이상치로 각 레이블을 할당하게 되며, 이를 다시 정리해보면, 임의의 점을 중심으로 엡실론 반경 내의 최소 이웃수 이상의 점이 있다면 그 점을 중심으로 군집이 되고, 그점을 core point라고 한다.
:core point가 서로 다른 core point의 군집의 일부가 되면 그 군집은 서로 연결되어 있다고 하고 하나의 군집으로 연결한다.
:군집에는 속하지만 스스로 core point가 되지 못하는 점을 border point라고 하며, 주로 클러스터의 외각을 이루는 점들이다. 그리고 그 어떠한 클러스터에도 속하지 못하는 점들은 noise point가 된다.
:이 알고리즘의 대표적인 장점 중 하나는 처음에 이야기 했듯. 클러스터 모양을 원형으로 가정하지 않는다는 것, 그리고 모든 데이터들을 꼭 클러스터에 할당하지 않아도 되기에, 자연스럽게 이상치 데이터들을 구분할 수 있게 된다.
:kmeans 군집, 계층 군집은 반달모양 군집을 제대로 구분해 내지 못했지만, 밀집도 기반 군집은 잘 구분해 냈다. 즉, 밀집도 기반 군집은 복잡한 구조를 가진 데이터 셋을 구분하는데 있어, 그 능력이 출중하다는 것.
:이 알고리즘의 단점은?
이 알고리즘 역시 데이터의 특성이 늘어남에 따라 차원의 저주로 인한 역효과가 증가하게 됨. 하지만 이러한 차원의 저주 문제는, 밀집도 기반 군집분석에만 해당되는 문제가 아니다. 유클리디안 거리 측정 방식을 사용하는 다른 군집 알고리즘에도 영향을 미치게 된다. 그렇게 이러한 문제를 해결하고자, 차원 축소나 표준화 등등 다양한 방법이 사용되고 있다. -
하이퍼파라미터 최적화
:밀집도 기반 군집 알고리즘으로 좋은 군집 결과를 만들기 위해 우리가 해야할 일은, 이 두개의 하이퍼 파라미터를 최적화 시켜줘야 한다는 것. 하지만 알맞은 조합을 찾는 일은 그렇게 쉽지만은 않다. 지금은 시각화가 가능한 저차원 데이터셋을 사용했지만 실전에서는 어떠한 형태인지 시각적으로 표현할 수 도 없는 고차원 데이터셋인 경우가 많다.
하나의 알고리즘과 일정한 하이퍼 파라미터에 의존하지 말라
오히려 적절한 거리지표를 선택하고 실험 환경을 구성하는데 있어 도움을 줄 수 있는 도메인 지식을 갖추는 것이 매우 중요하다.
