이제 통계와 머신러닝에 대한 얘기를 끝내고 딥러닝에 대한 내용을 작성하도록 하겠다.
-
딥러닝
:딥러닝이란 인간의 신경망 이론을 이용한 인공신경망의 일종으로, 계층 구조로 구성되며 입력층과 출력층 사이에 하나 이상의 은닉층을 가지고 있는 심층 신경망이다.
:인공신경망은 인간의 뇌 구조를 모방하여 모델링한 수학적 모델이다.
:아주 크게 구분하자면, 신경세포인 뉴런과 시냅스 혹은 가중치인 연결로, 1. 신경세포인 뉴런과 2. 시냅스 혹은 가중치인 연결로 구분할 수 있는데, 신경세포부터 이야기해보면, 뉴런의 입력은 다수이고, 출력은 하나이며, 여러 신경세포로부터 전달되어 온 신호들이 합산되어 출력됨. 근데 또 출력이 무작정되는 건 아니고 합산된 값이 설정값 이상이면 출력신호가 생기고, 이하이면 출력신호가 생기지 않는다.
:생물학과 비교하여 이야기하자면, 수상돌기는 입력과 비교할 수 있고, 입력이 합산되는 지점은 세포체 혹은 노드, 그리고 출력을 담당하는 곳은 축삭이라고 할 수 있다.
:다음으로, 시냅스는 다수의 뉴런을 연결해주는 역할을 담당하고 있다. 그리고 이 인공신경망의 경우도 노드를 연결시키고 층을 만들며, 이러한 연결 강도는 가중치로 처리됨
:간단하게 얘기하면, 인간의 뇌를 형성하는 뉴런의 집합체를 수학 모델로 표현한 것이 인공신경망이다. -
합성곱 신경망
:CNN은 인식이라는 범주에서 한 발짝 더 나아가 화가들의 그림을 학습하고 이를 활용하여 일반 그림을 화풍에 맞게 그려주는 기술로 발전되기도 하였고, CNN 기반 SegNet은 자율주행을 위해 카메라에 담긴 주변 환경을 픽셀 수준으로 분할하여 인식하게 된다.
:이미지 인식이 주로 CNN 기반 딥러닝이 사용되었다면, 음성 혹은 글자와 관련된 부분에 있어서는 순환 신경망이 주를 이루게 됨 -
순환신경망
:음성과 텍스트의 공통점은 길이가 가변적이라는 것이며, 사람의 말을 정확하게 판단하기 위해서는 단어 하나하나를 파악하기보다는 말의 문맥을 활용할 줄 알아야 하는 것이 더 중요하다.
:그래서 이전의 기억을 어느 정도는 가지고 활용할 줄 알아야 하며, 순환신경망은 이러한 면에서 그 강점을 발휘하게 됨.
:이후 순환신경망은 LSTM, GRU 등으로 발전하게 되며 긴 문장에 대한 번역에서도 높은 성과를 달성 -
퍼셉트론
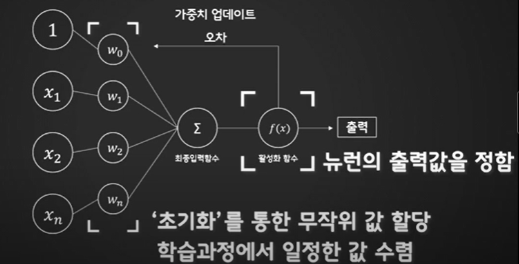
하나의 뉴런을 좀 더 자세하게 표현하면 이렇게 가중치와 활성화 함수가 숨어 있는 것을 확인할 수 있다. 이 때 이 활성화 함수는 뉴런의 출력 값을 정하는 함수로써, 가장 간단한 형태의 뉴런은 입력에 가중치를 곱한 뒤, 활성화 함수를 취하면 출력 값을 얻을 수 있다. 이 뉴런에서 학습할 때 변하는 것은 가중치이다.
가중치는 처음에 초기화를 통해 무작위 값을 넣고 학습과정에서 점차 일정한 값으로 수렴하게 된다. 학습이 잘 된다는 것은, 좋은 가중치를 얻어 원하는 출력에 점점 가까워지는 값을 얻는 것이라고 할 수 있다.
학습률은 적당히 작은 값이 보편적으로 많이 사용된다.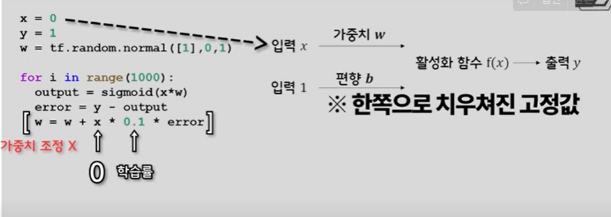
입력값에 0이 들어오는 순간 부터 그 어떠한 학습률 값을 넣어도 이후 가중치에 더해지는 값이 없다는 것. 즉 1000번의 가중치 조정은 의미가 없었다는 것 . 이러한 문제를 해결하기 위해서 편향이라는 것을 도입하여 해결
편향은 의미 그대로 입력으로는 늘 한쪽으로 치우처진 고정 값이며, 입력으로 받은 값이 0인 경우에 아무것도 학습하지 못하는 것을 방지한다. 이러한 편향 값도 가중치 처럼 난수로 초기화 되며 뉴런에 더해져 출력을 계산하게 된다.XOR 은 2개의 입력값이 서로 다를 떄 참을 출력하게 됨. XOR은 참과 거짓을 하나의 직선으로 구분할 수 없음
퍼셉트론 또한 이러한 XOR 연산에 대해 다양한 가중치를 바탕으로 학습을 진행해도 모든 결과값이 0.5 근처에 머물며 우리가 원하는 값으로는 수렴하지 않는다. -
다층 퍼셉트론
:해결책은 간단하게도 단층이 아닌, 다층 퍼셉트론을 활용하게 되면 어느 정도의 문제가 해결된다는 것.
:하지만 1969년 당시 연구진들은 이렇게 간단한 XOR 문제 조차 풀 수 없는 퍼셉트론을 그저 단순 선형 분류기에 불과하다 하였고, 인간의 뇌를 모방한 퍼셉트론의 한계는 곧 인공신경망 연구의 겨울을 불러오게 되었다.
:물론 저서 퍼셉트론에도 다층 퍼셉트론을 사용하게 되면 어느 정도 문제는 해결된다 하였지만, 크게 받아들여지지는 않았다. -
역전파
:신경망의 역전파는 그 이름에서도 알 수 있듯, 뉴런의 가중치를 효율적으로 조정하기 위하여, 거꾸로 무엇인가를 전파하는 방식
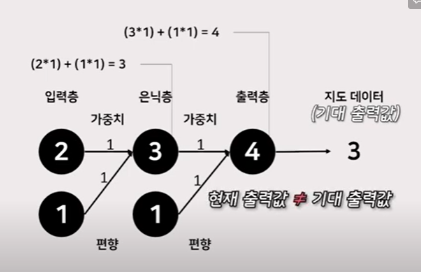
:예를 들어 3개의 계층과 편향이 있는 간단한 신경망이 있다. 그리고 이 신경망은 입력이 2일때, 출력값 3을 얻고자 함. 가중치는 현재 초기값으로 모두 1로 설정됬다고 가정하고 계산. 이 신경망에는 활성화 함수가 따로 없으니, 은닉층의 첫번쨰 노드는 3, 그리고 여기서도 가중치는 1이니까 최종 출력 값은 4라는 결과가 나옴. 현재 이 데이터에 대한 기대 출력값은 3이지만, 가중치를 모두 1로 설정한 결과, 현재 출력값은 3보다 큰 4라는 결과가 나오게 됨
:기대 출력값과 현재 출력값 과의 오차는 1. 따라서 역전파에서는 기존의 출력값을 지우고 새로운 출력값으로 3을 전달함. 단편적으로 이러한 값이 나오기 위해서는 당연히 바로 이전의 값을 무시할 수 없다. 그리고 바로 이전의 값에서 더 큰 값은 자연스럽게 더 큰 영향을 미치게 될 것.
그럼 신경망은 당연히 은닉층 노드 값과 고정값을 비교하게 된다. 값이 큰 쪽의 가중치 혹은 편향을 더 크게 조정하여 출력 값을 3이 되도록 만들려고 함. 여기서는 은닉층 고정값이 1이니까 , 1/10 정도 조정한다 가정하고 편향과 가중치에서 1/10을 뺴서 0.7, 0.9로 조정함
그럼 이러한 조정을 통해 은닉층에서 전파할 오차는 총 0.4가 되므로 역전파를 적용한 신경망의 출력 값은 새로운 출력값 3에서 은닉층에 전파할 오차 0.4를 뺀 새로운 값인 2.6에 가까운 값이어야한다.
이러한 방식으로 입력층과 은닉층 사이의 가중치와 편향도 조정. 입력층의 가중치는 0.8로, 편향은 0.9로 조정.
이렇게 계산한 결과는 기대 출력값에 대해, 우리가 처음에 가중치를 1로 설정하여 계산한 결과보다 훨씬 가까워진 결과를 확인할 수 있다.
지금까지의 과정은 결국 신경망의 지도 데이터와 출력 값 사이의 오차로 가중치를 조정하는 것임으로 알 수 있다.
즉, 역전파는 출력값과 지도 데이터 사이에 생기는 '오차'를 이용해 출력층에서 입력층 쪽으로 가중치를 조정하는 것이다.
-
경사하강법
:이와 같은 신경망에서 손실함수를 정의해 보면, 손실함수는 출력값과 지도 데이터 사이의 오차라고 할 수 있다. 역전파는 이 손실함수가 최솟값일 떄의 가중치로 원래의 가중치를 조정해야 한다. 그래서 입력값 각각의 손실 함수 전체를 고려해야 한다.
:이어지는 이야기로, 특정 입력값에서의 손실 함숫값이 최소가 되더라도 전체를 생각했을 떄 크게 의미는 없다. 궁극적인 목표는 모든 입력값을 대상으로 손실 함수가 최솟값일 떄의 파라미터를 찾는 것이다.
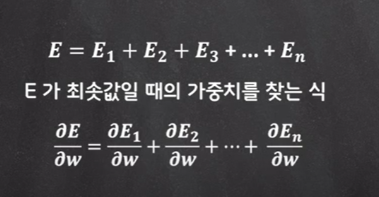
:이때 손실함수 E가 최솟값일 떄의 가중치를 찾는 것은 이 식처럼 E를 가중치 W에 관해 편미분하는 것이 되겠다.
:그리고 우리는 미분한 값이 0에 가까운 가중치를 찾아야 하는 것이다.
:0에 가까운 미분값을 찾는 이유는 이전에 살펴봤던 경사 하강법에서의 기울기 값이 0에 가까워졌을 떄, 손실 함숫값이 최솟값 후보가 되기 때문이다.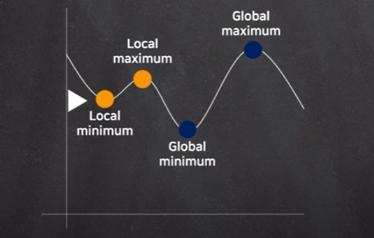
:후보라는 단어를 사용햇는데, 계산 결과를 통해 기울기가 0에 가까워졌다고 해도 그 값이 꼭 최솟값이라 확신할 수 없다.
:이유는 기울기에 대한 변화가 없다가 다시 점차 증가 혹은 감소하는 현상이 발생할 수 도 있으며, 마치 심하게 요동치는 파동과도 같은 모습을 보이는 경우가 다수 있기 때문이다.
:그렇기에 기울기가 0에 가깝게 수렴했을 때, 무작정 최솟값이라 단정 짓는 것은 꽤나 위험한 행동이 될 수 있다.
:이러한 식에서 E를 각각 전개하여 직접 편미분을 진행하면 꽤나 번거롭다.
:그렇기에 입력값 각각의 손실함수를 편미분 한 후에 합이 0에 가까운지 확인하는 것이 더 간단. 그럼 손실함수가 최솟값일 때의 가중치를 찾아보도록 하겠음
:이렇게 지도데이터가 한개인 신경망에서 손실함수가 최솟값일 때의 가중치를 찾는 과정을 살펴보겠음.
:은닉층과 출력층 사이에서 은닉층 가중치가 w, 은닉층 편향이 b라면 실제 출력값 z는 z=b + wy가 됨.
:E에 관해 w로 편미분 할 때는 너무 복잡하니 연쇄 법칙을 이용하여 간단하게 할 필요가 있다.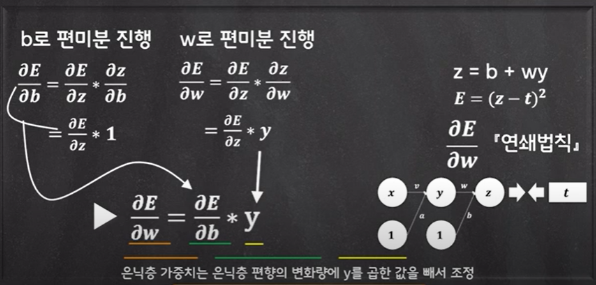
:b로 편미분 진행
:w로 편미분 진행
:은닉층 편향의 편미분으로 E에 관한 은닉층 가중치 w의 편미분을 정의할 수 있게 됨
:최종적으로 저 식을 통해 은닉층 가중치는 은닉층 편향의 변화량에 y를 곱한 값을 빼서 은닉층 가중치를 조정할 수 있는 것임.
:이와 같은 방식으로 입력층과 은닉층 사이도 가중치와 편향을 조정할 수 있다. 즉, 입력값의 가중치도 입력층 고정값이 1일 때 ,입력층 편향의 변화량에 x를 곱한 만큼 빼서 조정할 수 있다.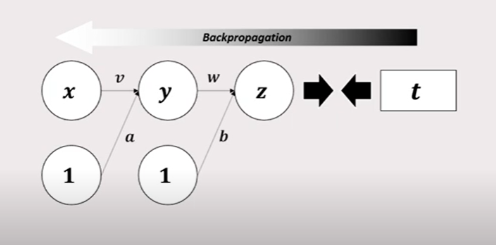
:이렇게 역전파를 활용하게 되면, 신경망의 출력 값부터 차례대로 이전 노드 값이 정해지게 되면서 이러한 역전파는 수열의 점화식처럼 오차를 전파하는 방법이기도 하다. 역전파를 역방향 미분이라고 하기도 한다.
:그만큼 역전파에 있어서 미분이 아주 중요 -
기울기 소멸
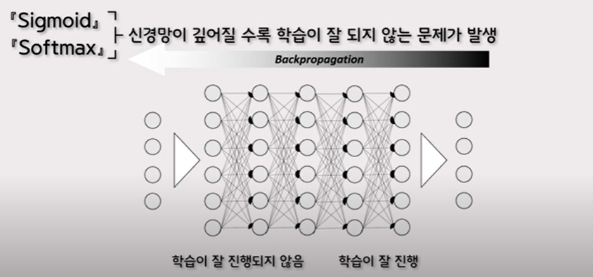
당시 역전파 알고리즘으로 학습을 진행하는데 있어, 주로 사용된 활성화 함수는 시그모이드와 소프트 맥스였다.우선 시그모이드의 경우 미분의 최대치가 0.3에 불과하며, 여러 층을 거칠 수록 기울기는 점차 0에 수렴하게 되는 문제가 발생함
소프트맥스함수는 출력 값으로 확률 벡터를 얻기 위해 사용되었는데, 각 출력 노드의 출력 값을 0에서 1 사이의 값으로 제한하였고 시그모이드나, 소프트 맥스는 최종 출력을 결정하는데 있어 합리적인 선택이 가능했으나 출력된 값들이 항상 너무 작은 값을 가지고 있었기에 신경망이 깊어지면 깊어질수록 오차의 기울기가 점차 작아지며, 끝으로 가는 도중 기울기가 소실돼버리면서 가중치 조정이 이뤄지지 않는다는 문제가 발생함.
이러한 기울기 소멸문제를 해결하기 위해 제프리 힌튼 교수는 다양한 함수를 제시하였으며 그중 ReLU라는 활성화 함수를 사용하게 되면 어느정도 문제가 해결됨을 발견하게 됨
이 활성화 함수는 입력이 음수일 때는 0, 양수일 때는 그 자체 양수값을 그대로 출력하기에, 다른 활성화 함수보다 기울기 소실 문제에 있어 어느정도 면역을 갖게 됨
