Optimization
Neural network에서 가장 중요한 것은 Optiamization
1-order optimization
1. SGD

Stochastic Gradient Descent
minibatch를 활용한 경사하강법
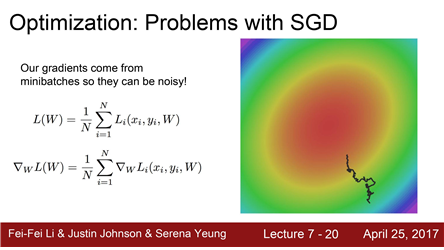
Example)
- X/Y축은 두 개의 가중치
- 각 색: Loss의 값

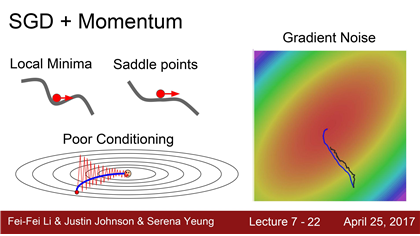
probloems with SGD 1. 느리게 변하는 손실함수
SGD의 문제점 중 하나는 손실함수가 이같은 형태(taco shell)로 생겼을 때 ,w1과 w2가 있다고 가정
둘중 어떤 하나는 업데이트를 해도 손실함수가 아주 느리게 변한다.
- 수평 축 가중치는 변해도 loss가 아주 천천히줄어든다
- loss는 수직 방향 가중치에 변화에 민감하다.
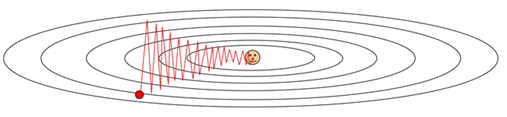
SGD의 학습과정은 어떨까?
손실 함수가 이런 식으로 생긴 환경에서 SGD를 수행하면, 이런 특이한 지그재그 형태
(gradient의 방향이 고르지 못하기 때문)
- 수평방향 차원의 가중치는 업데이트가 아주 느리게 진행
- 수직 차원을 가로지르면서 지그지그로 움직임
----> 고차원에서 더욱더 심각해집니다. (그림은 2차원 밖에 되지 않습니다만 실제로는
가중치가 수천 수억개 일 수 있을 것입니다.)

probloems with SGD 2. local minima 와 saddle points와 관련된 문제
▶ Local minima :우리는 최소의 loss를 찾으려고 SGD를 수행하는데 컴퓨터는 가까운 길에서 gradients가 0이되는 지점을 찾아버리므로 이게 최고의 loss다 생각하고 학습을 멈춰버리는 경우
▶ saddle points : 어느 방향에서 보면 극대값이지만 다른 방향에서 보면 극소값이 되는 점이다.
(한쪽방향으로는 증가, 다른 한쪽방향으로는 감소하는 지역)
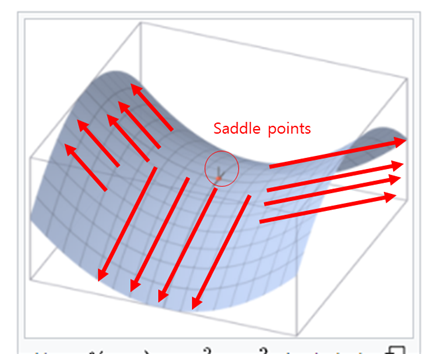
- 1차원의 예제만 봐서는 local minima가 엄청 심각하고 saddle point는 별로 안심각해보임
- 고차원 공간에서는 1억개의 차원에서 생각해보면 이는 정말 빈번하게 발생
probloems with SGD 3. 부정확한 loss 값
원래는 손실함수를 계산할 때는 엄청 엄청 많은 Traing set 각각의 loss를 전부 계산해야 합니다.
이 예시의 N이 전체 training set일 경우에 N개 만큼 계산을 해줘야합니다.
SGD 경우에는 미니배치의 데이터들만 가지고 실제 Loss를 “추정”하기만 합니다.
이는 매번 정확한 gradient를 얻을 수가 없다는 것을 의미합니다.
gradient의 부정확한 추정값(noisy estimate) 만을 구할 뿐입니다
2. SGD + Momentum

기존 SGD 문제점들을 보완
왼쪽은 classic SGD (gradient 방향으로만 움직임)
오른쪽은 SGD + momentum (미니배치의 gradient 방향만 고려하는 것이 아니라 velocity를 같이 고려)
rho : momemtum의 비율 (velocity의 영향력을 rho의 비율 = 0.9 정도 사용)
-> gradient vector 그대로의 방향이 아닌 velocity vector의 방향
기존에는 방향성만 가지고 있었다면
momentum을 통해 velocity를 추가하여 계속해서 움직이므로 local minina와 saddle points 문제 둘다 해결이 가능해집니다.
이동을보면 지그재그로 움직이던게 noise가 평균화로 매끄럽게 움직임
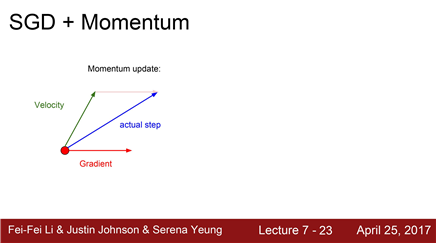
빨간 점 : 현재 지점
Red Vector : 현재 지점에서의 gradient의 방향
Green vector : Velocity vector
actual step : 실제 움직이는 vector (위 둘의 가중평균)
-> gradient의 noise 해결
3. Nesterov momentum
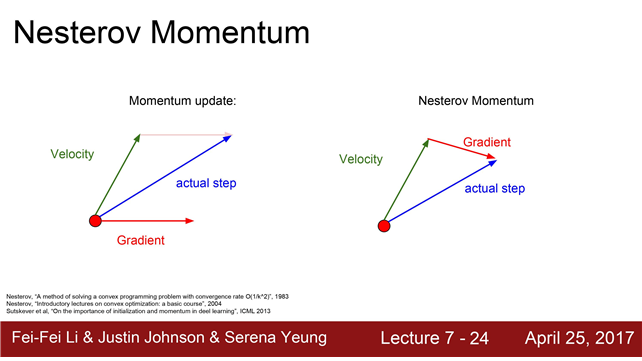
Momentum의 변형: Nesterov accelerated gradient (Nesterov momentum)
빨간 점에서 시작해서 우선은 Velocity방향으로 움직입니다.
그리고 그 지점에서의 gradient를 계산합니다. 다시 원점으로 돌아가서 둘을 합치는 것입니다.
-> 두 정보를 약간 더 섞어줌

nestroc 변형 : 에러보정 효과
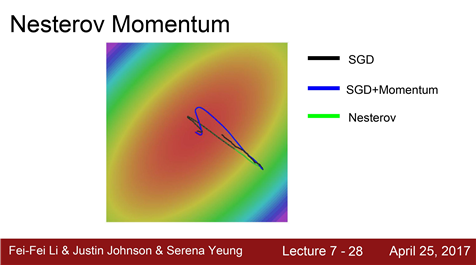
기본 SGD : 많이 느림
momentum : minima를 그냥 지나쳐 버리는 경향이 있습니다.이전의 velocity의 영향을 받기 때문입니다.
Nesterov: 일반 momentum에 비해서 overshooting이 덜 한 것을 알 수 있습니다.
4. Adagrad
#AdaGrad
grad_squared =0
while True:
dx = compute_gradient(x)
grad_sqaured += dx * dx #학습 도중 계산되는 gradient 제곱
x -= learing_rate * dx / (np.sqrt(grad_sqaured) + 1e-7)
# Update를 할때 Update term을 앞서 계산한 gradient 제곱 항으로 나눔 - 훈련도중 계산되는 gradients를 활용하는 방법
- Adagrad는 velocity term 대신에 grad squared term(학습 도중에 계산되는 gradient에
제곱을 해서 덧셈) 이용

Adagrad의 문제점
- dimension에 따른 속도
Small dimension에서는 gradient의 제곱 값 합이 작습니다. 이 작은 값이 나눠지므로 가속도가 붙게 됩니다.
Large dimension에서는 gradient가 큰 값 이므로 큰 값이 나눠지게 되겠죠. 그러므로 속도가 점점 줄어듭니다.
- Non-convex에서 AdaGrad의 멈춤
update 동안 gradient의 제곱이 계속해서 더해집니다. 때문에 이 값(estimate)은 서서히(monotonically) 증가하게 됩니다. 이는 Step size를 점점 더 작은 값이 되게 합니다.
손실함수가 convex한 경우에 점점 작아지는 것은 정말 좋은 특징이지만
non-convex case에서는 문제 saddle point에 걸려버렸을 때 AdaGrad는 멈춰버릴 수 있습니다.
5. RMSProp
#RMSProp
grad_squared =0
while True:
dx = compute_gradient(x)
grad_sqaured = decay_rate * grad_squared+(1-decay rate) * dx*dx
# 이전항 * decay_rate + 현재 gradient의 제곱 *(1 - decay rate)
x -= learing_rate * dx / (np.sqrt(grad_sqaured) + 1e-7)-AdaGrad의 gradient 제곱 항을 그대로 사용
-이 값들을 그저 누적만 시키는 것이 아니라
기존의 누적 값에 decay_rate를 곱
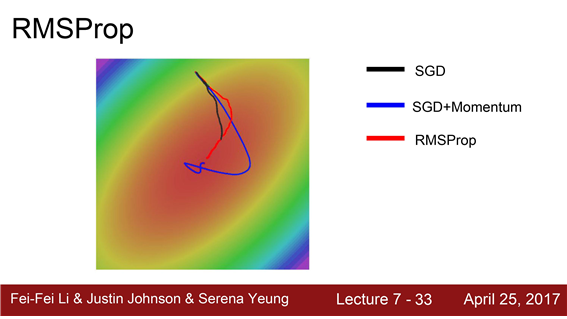
RMSProp은 각 차원마다의 상황에 맞도록 적절하게 궤적(trajectory)을 수정
6.Adam
- momentum , Ada계열의 조합
#Adam
first_moment =0
second_moment=0
while True:
dx = compute_gradient(x)
first_moment beta1 * first_moment + (1-beta1) *dx #momentum
second_moment = beta2*second_moment + (1-beta2) *dx*dx #AdaGrad/RMSprop #1번
first_unbias = first_moment / (1-beta1 **t)
second_unbias = second_moment/(1-beta2 **t) #bias correction #2번
x -= learing_rate * first_unbias / (np.sqrt( second_unbiast) + 1e-7) #AdaGrad/RMSprop #3번ADAM의 동작
- Adam은 first moment와 second moment을 이용해서 이전의 정보(estimate)를 유지
- Adam은 초기 Step이 엄청 커져 버릴 수 있고 이로 인해 잘못 가능성
-> Adam을 이를 해결하기 위해 보정하는 항을 추가 (bias correction term )- first/second moments를 Update하고 난 후 현재 Step에 맞는 적절한 unbiased term 을 계산
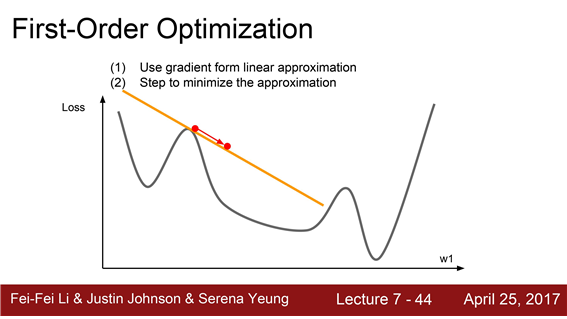
지금까지 배운 Optimization 알고리즘들을 모두 1차미분을 활용한(first-order) 방법이었습니다.
그림처럼 1차원의 손실함수가 있다고 생각해 봅시다.
우리는 지금 빨간색 점에 있는 것입니다.이 점에서 gradient 를 계산하겠죠
이gradient 정보를 이용해서 우리는 손실함수를선형함수로 근사시킵니다.이는 일종의 1차 테일러 근사입니다.
(first-order Taylor apporximation)
이 1차 근사함수를 실제 손실함수라고 가정하고 Step을 내려갈 것입니다.
이 근사함수로는 멀리갈 수 없습니다 현재 사용하는 정보는 1차 미분값일 뿐입니다.
2-order optimizaion
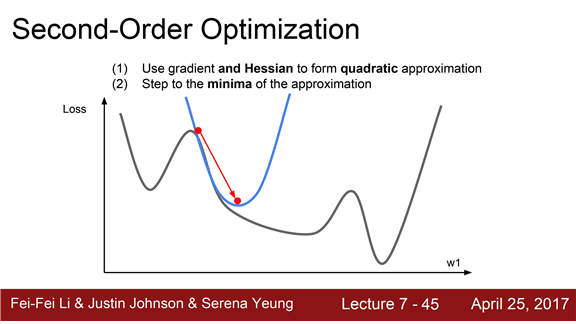
2차 근사 (second-order approximation)의 정보를 추가적으로 활용하는 방법이 있습니다.
이는 2차 테일러 근사 함수가 될 것이고 이 함수는 2차함수의 모양입니다.
2차 근사를 이용하면 minima에 더 잘 근접할 수 있습니다.
이것이 바로 2nd-order optimization의 기본 아이디어입니다.
1.Newton step

- Hessian matrix를 계산합니다. 2차 미분값들로 된 행렬입니다.
- Hessian matrix의 역행렬을 이용하게 되면 실제 손실함수의 2차 근사를 이용해 minima로 곧장 이동할 수 있을 것입니다.
- Learning rate가 없습니다.기본적인 Newton's method 에서는 learning rate는 불필요합니다.

Deep learning에서는 사용할 수 없습니다.
왜냐하면 Hessian matrix는 N x N 행렬입니다. N은 Network의 파라미터 수입니다.
N이 1억이면 1억의 제곱만큼 존재할 것입니다.
이를 메모리에 저장할 방법은 없으며 또한 역행렬계산도 불가능 할 것입니다.
2.LBFGS

- Hassian을 근사시켜서 사용하는 방법
- DNN에서는 잘 사용하지 않음
- L-BFGS에서 2차근사가 stochastic case에서 잘 동작하지는 않기 때문
- L-BFGS는 non-convex problems에도 부적합
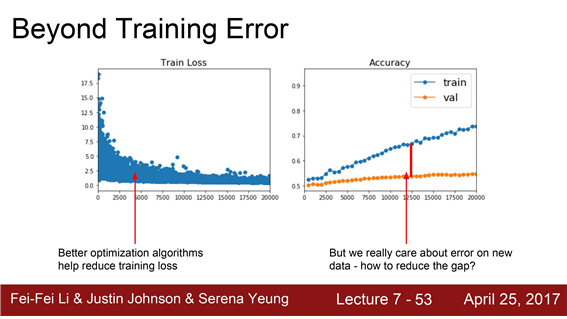
지금까지 Optimization : training error를 줄이기 위한 방법
- optimization 알고리즘들은 training error를 줄이고 손실함수를 최소화시키기 위한 역할을 수행
우리의 주된 관심사 한번도 보지 못한 데이터에 대한 성능!!!

'한번도 보지 못한 데이터' 에서의 성능을 올리기 위해서는 어떻게 해야 할까요?
가장 빠르고 쉬운 길은 바로 모델 앙상블입니다. Machine learning 분야에서 종종 사용하는 기법입니다.
모델을 하나만 학습시키지 말고 10개의 모델을 독립적으로 학습시키는 것입니다.
결과는 10개 모델 결과의 평균을 이용합니다. 모델의 수가 늘어날수록 overfitting 줄어들고 성능이 조금씩 향상됩니다. 보통 2%정도 증가하죠
Regularization
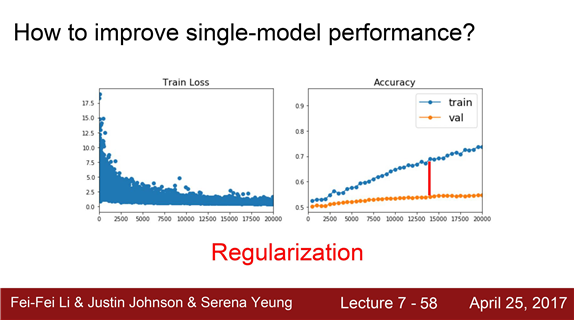
앙상블이 아닌 단일 모델의 성능을 향상시키기 위해서는 어떻게 해야 할까요?
regularization
우리가 모델에 어떤 것을 추가할 텐데 모델이 training data에 fit하는 것을 막아줄 것입니다.
그리고 한번도 보지 못한 데이터에서의 성능을 향상시키는 방법입니다.
1. dropout
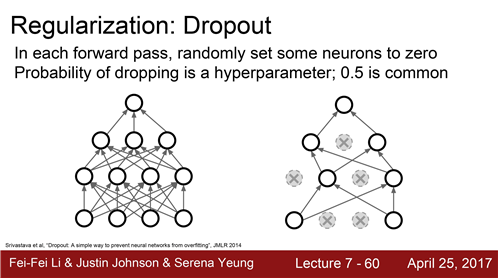
Neural network에서 가장 많이 사용하는 regularization은 dropout입니다.
왼쪽에는 dropout이 없고 오른쪽은 dropout이 적용된 경우입니다
dropout 진행 과정
- forward pass 과정에서 임의로 일부 뉴런을 0으로 만드는 것입니다.
- forward pass 할때마다 0이 되는 뉴런이 바뀝니다. Dropout은 한 레이어씩 진행하게 됩니다.
- 한 레이어의 출력을 전부 구합니다. 그리고 임의로 일부를 0으로 만듭니다.
- 다음 레이어로 넘어갑니다.
Dropout이 Overfitting을 어느정도 막아줍니다.
dropout code
#dropout
p=0.5 # dropout probability
def dropout(X):
# 1 layer
H1 = np.maximum(0,np.dot(W1,X)+b1) # 뉴런을 0으로 만듬
UI = np.random.rand(*H1.shape) < p # dropout probability만큼 0으로 만듬
H1 *= U1
# 2 layer
H2 = np.maximum(0,np.dot(W2,H1)+b2) # 뉴런을 0으로 만듬
U2 = np.random.rand(*H2.shape) <p # dropout probability만큼 0으로 만듬
H2 *= U2
# output layer
out = np.dot(W3,H2) +b3
단일 모델로 앙상블 효과가진 Dropout
-
Dropout을 적용한 네트워크를 살펴보면 뉴런의 일부만 사용하는 서브네트워크
-
Dropout으로 만들 수 있는 서브네트워크의 경우의 수가 정말 다양하다는 것을 알 수 있습니다.
-
서로 파라미터를 공유하는 서브네트워크 앙상블을 동시에 학습시키는 것이라고 생각할 수 있습니다.
-
아주 거대한 앙상블 모델을 동시에 학습 시키는 것이라고 볼 수 있겠습니다.

Dropout을 사용하면 Test time에 어떤 일이 일어날까요?
Dropout을 사용하면 Network에 z라는 입력이 추가됩니다.
z는 "random dropout mask"입니다. z는 random입니다. 하지만 test time에 임의의 값을
부여하는 것은 좋지 않습니다.
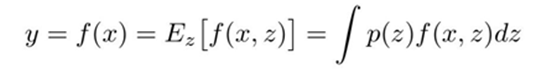
랜덤성을 없애면서 평균화하기 위한 dropout 적분법:
출력 : a
입력 : x, y
가중치 : w_1, w_2
dropout(p = 0.5)
dropout mask : 4가지 경우의 수
- 순수 적분 이용
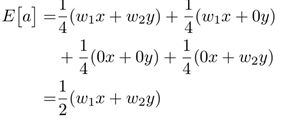
Test time에서 a는 w_1x + w_2y 입니다.
Train time에서 a의 기댓값은 1/2(w_1x + w_2y) 입니다.
- dropout probability 이용
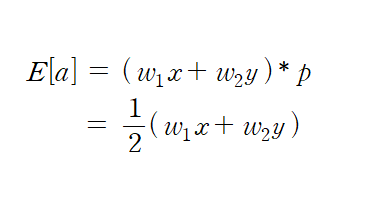
dropout probability(p)를 네트워크의 출력에 곱합니다.
Train time에서 a의 기댓값은 1/2(w_1x + w_2y) 입니다.
dropout test time code
#dropout test time
p=0.5 # dropout probability
def predict(X):
H1 = np.maximum(0,np.dot(W1,X)+b1) *p #activation scale 설정
H2 = np.maximum(0,np.dot(W2,H1)+b2)*p #activation scale 설정
out = np.dot(W3,H2) +b32. inverted dropout
#inverted dropout
p=0.5 # dropout probability
def train_inverted_dropout(X):
# 1 layer
H1 = np.maximum(0,np.dot(W1,X)+b1) # 뉴런을 0으로 만듬
UI = (np.random.rand(*H1.shape) < p) /p # inverted dropout
H1 *= U1
# 2 layer
H2 = np.maximum(0,np.dot(W2,H1)+b2) # 뉴런을 0으로 만듬
U2 = np.random.rand(*H2.shape) /p # inverted dropout
H2 *= U2
# output layer
out = np.dot(W3,H2) +b3
def predict(X):
H1 = np.maximum(0,np.dot(W1,X)+b1) # test time 효율성 증가
H2 = np.maximum(0,np.dot(W2,H1)+b2) # test time 효율성 증가
out = np.dot(W3,H2) +b3 ```효율성을 증가시키기 위해 Dropout을 역으로 계산하는 것입니다 (inverted dropout)
3. Batch normalization

- Train time의 BN를 상기해보면 mini batch로 하나의 데이터가 샘플링 될 때 매번 서로 다른 데이터들과 만남
- Train time에서는 각 데이터에 대해서 이 데이터를 얼마나 어떻게 정규화시킬 것인지에 대한 추론이 존재
- Batch normalization 은 Dropout과 유사한 Regularization 효과
4. Data augmentation
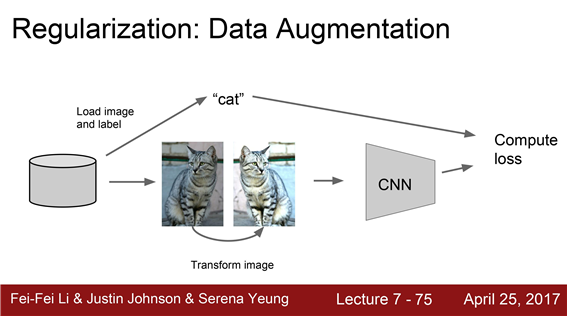
- 원본 이미지를 사용하는 것이 아니라 무작위로 변환시킨 이미지(flip,crop,corne...)로 학습
- 입력 데이터에 임의의 변환을 시켜주게 되면 regularization 효과
5. DropConnect
- DropConnect은 activation이 아닌 weight matrix를 임의적으로 0으로 만들어주는 방법
6. fractional max pooling
fractional max pooling
- 보통 2x2 maxpooling 연산은 고정된 2x2 지역에서 수행
- pooling연산을 수행 할 지역 임의 선정방법
7. stochastic depth
- train time에 네크워크의 레이어를 randomly drop
- train time에는 layer 중 일부를 제거해 버리고 일부만 사용해서 학습
- test time에는 전체 네트워크를 다 사용