개요
- Numpy 실습
- 선형 회귀란?
Numpy 실습
diag()
- 1차원 배열을 대각선 요소를 사용하여 생성하거나 추출함
import numpy as np
x = np.array( [
[1,2,3,4,5,6],
[6,5,4,3,2,1],
[11,12,13,14,15,16],
[76,75,74,73,72,71],
[86,85,84,83,82,81],
[96,95,94,93,92,91]
] )
print('diag 결과\n', np.diag(x))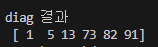
trace()
-
대각합을 구하는데 사용하는 합수
-
2차원 배열의 경우
import numpy as np
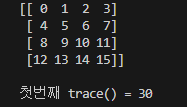
y = np.arange(16).reshape(4,4) # 4행* 4열
print(y)
print()
# trace는 대각값들 더하기
print(f'첫번째 trace() = {np.trace(y)}')
- 3차원 배열일 경우
- 3차원 행렬을 2차원으로 슬라이싱 해서 각 행렬의 1번, 2번 3번 값을 뽑아서 하나의 배열로 반환
z = np.arange(27).reshape(3,3,3)
print(z)
print(f'두번째 trace() = {np.trace(z)}') # [36 39 42]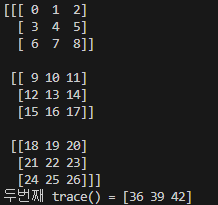
trace(z) = [(0 + 12 + 24) (1 + 13 + 25) (2 + 14 + 16)] = [36 39 42]
fromfunction
- 주어진 함수를 사용하여 지정된 shape의 배열을 생성
- 함수의 인자로 배열의 인덱스를 받아서 해당 인덱스에 대응하는 값을 계산하고, 그 결과를 배열에 저장
- 특정 규칙에 따라 값을 생성하는 배열을 만들 때 유용
import numpy as np
import time
def myEST(x,y):
ret = x*10 + y
return ret
print('일반함수 = ',myEST(3,7))
print( np.fromfunction(myEST,(3,7), dtype=int)) # 3 * 7열
print()
print('일반함수 = ', myEST(5,6))
print( np.fromfunction(myEST,(3,7), dtype=int) )
print()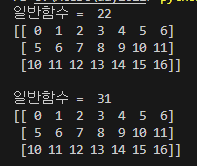
shuffle , permutation
- 배열의 순서를 랜덤으로 섞는데 사용
- shuffle의 경우 원본 데이터 값을 남기지 않음
- permutation의 경우 원본값을 유지함
import numpy as np
import time
dt = np.arange(1, 11)
print(dt)
# 배열 안의 순서를 랜덤으로 섞음
np.random.shuffle(dt) # 리턴값을 부여하면 none이 나옴
print(dt)
print('=' * 30)
data = np.arange(1, 11)
print(data)
print(np.random.permutation(data))
print(data) # 원본값을 유지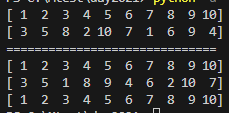
concatenate
- 배열을 결합함
- 행의 갯수가 틀려도 문제가 없음
- numpy의 차원은 동일하게 해야 에러가 발생하지 않음
# concatenate() 데이터 연결
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
ret1 = np.concatenate((a, b), axis = 0 ) # axis = 0성공
print(ret1)
print()
# trace()를 이용 가능
ret2 = np.concatenate((a, b.T), axis=1)
print(ret2) #출력결과 [ [1 2 5] [3 4 6] ]
print()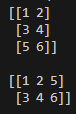
배열의 축(axis)
축은 n차원 배열을 구성하는 요소
axis = n은 바깥부터 안쪽 리스트 순으로 0부터 이름을 붙인 것
1차원 배열은 축이 1개, 2차원 배열은 축이 2개 3차원 배열은 축이 3개임
1차원 배열에서는 axis 0 = 축
2차원 배열에서는 axis 0 = 행 axis 1 = 열
3차원 배열에서는 axis 0 = 층 axis 1 = 행 axis 2 = 열
linalg.det
- 정사각 행렬의 행렬식을 계산하는 함수
- 정사각 행렬: n * n 행렬
import numpy as np
a = np.array([[1,2], [3,4]])
ret = np.linalg.det(a)
print(ret)
linalg.inv
- 주어진 행렬의 역행렬을 구하는 함수
역행렬(Inverse Matrix)이란?
행렬 A, B가 각각 n*n행렬일때, AB = BA = I(항등행렬)인 행렬 B가 존재할때 A는 가역적 이라하고, AB = BA = I가 성립하는 하나뿐인 행렬 B를 A의 역행렬 이라함
이때 로 나타내는데
가 항상 성립함
import numpy as np
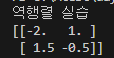
print('역행렬 실습')
a = np.array([[1,2], [3, 4]])
ret = np.linalg.inv(a)
print(ret)
Numpy와 선형 대수 함수
- 2월 20일에 사용한 함수 및 오늘 위의 실습 함수들은 numpy에서 자주 사용되는 선형 대수 함수
- 선형 대수(Liner Algebra)
- 벡터, 선형 변환, 행렬, 연립 선형 방정식 등을 연구하는 수학의 한 분야
- 공학, 자연과학, 사회과학, 경제학 등 응용에 매우 중요한 역할을 담당
- AI분야에서 선형대수는 이미지 처리, 기계학습, 딥러닝등의 분야에서 핵심적인 역할을 함
- 선형 대수를 활용하여 현실 세계의 다양한 데이터와 구조를 표현하고 다루는데 필수적임
자주 사용하는 선형 대수 함수
단위행렬(Unit matrix): np.eye(n)
영행렬(Zaro matrix): np.zero((m, n))
대각행렬(Diagonal matrix): np.diag(x)
전치행렬(Transpose matrix): np.T, np.transpose(a)
내적(Dot product, inner product): np.dot(a, b)
대각합(trace): np.trace(x)
행렬식(Matrix Determinant): np.linalg.det(x)
역행렬(Inverse of a matrix): np.linalg.inv(x)
고유값(Eigenvalue), 고유백터(Eigenvector): w, v = np.linalg.eig(x)
특잇값 분해(Singular Value Decomposition): u, s, vh = np.linalg.svd(A)
연립방정식 해 풀기: np.linalg.solve(a, b)
최소자승 해 풀기: m, c = np.linalg.lstsq(A, y, rcond=None)
선형회귀 모델
- 알려진 다른 관련 데이터 값을 이용하여 알수 없는 데이터 값을 예측하는 데이터 분석 기법
- AI 분야에서 데이터 분석과 예측 모델링을 하는데 중요한 역할을 함
- 선형회귀 모델은 가장 기본적이면서 강력한 예측 모델 중 하나
선형회귀 모델 실습
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname='C:/Windows/Fonts/malgun.ttf').get_name()
rc('font', family=font_name)
import numpy as np
# 1단계 총합계, 평균 구하기
x = [2, 4, 6, 8, 10] #총합계 30 /5 평균 6시간
y = [81, 93, 91, 97, 98] #총합계 460 /5 평균 92점
# 다항식 회귀 분석을 수행함
su = np.polyfit(x, y, 1)
print('결과', su) # 결과 [ 1.9 80.6]
# 단계2 선형회귀 공식 y = w가중치 * 시간 + b편향
y_pred = np.array(x)*su[0] + su[1]
print(y_pred) # 예측값 [84.4 88.2 92. 95.8 99.6]
print()
# 단계 3
plt.plot(x, y_pred, color='hotpink') #예상=예측값
plt.scatter(x, y, color='red') #실제값
plt.plot(x,y) #line기본모양
for i,v in enumerate(x):
plt.text(v, y[i], y[i], fontsize=12, color='blue',
horizontalalignment='left',
verticalalignment='bottom'
)
plt.title('시간투자 성적점수 선형회귀 EST')
plt.xlabel('공부시간 est')
plt.ylabel('시험점수 est')
plt.show()
print('시각화 작업 확인 ')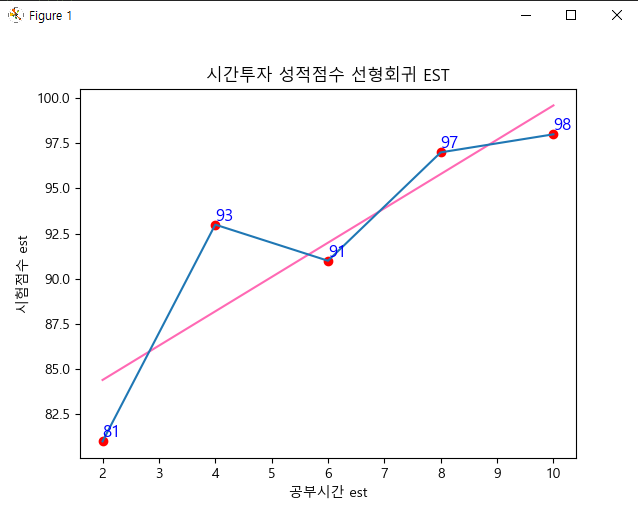
>선형대수 및 선형회귀 모델 같은 경우 좀더 공부 및 정리 할 필요가 있음

안녕하세요. 도야입니다