💬 컴퓨터에서의 문자 표현
🔛 패턴 매칭
💬 컴퓨터에서의 문자 표현
글자 A를 컴퓨터는 어떻게 저장할까???
메모리는 숫자만을 저장할 수 있기 때문에 A라는 글자의 모양 그대로 비트맵으로 저장하는 방법을 사용하지 않는 한 (가능은 하지만 메모리 낭비가 심한 방법) 각 문자에 대해서 대응되는 숫자를 정해놓고 이것을 메모리에 저장하는 방법으로 사용한다.
이렇게 할 경우 영어의 경우 대,소문자 합쳐서 52개의 글자이므로 6(64가지 경우의수)비트면 모두 표현할 수 있게 된다. 이를 코드 체계라고 한다.
- ex ) 000000 -> ‘a’ , 000001 -> ‘b’
‘아스키(ASCII)’의 탄생
네트워크가 발전되기 전에는 미국의 각 지역 별로 코드체계를 정해놓고 사용했지만, 네트워크(인터넷 : 인터넷은 미국에서 발전했다)가 발전하면서 서로간 정보를 주고 받을 때 정보를 달리 해석한다는 문제가 생겼다.
따라서, 혼동을 피하기 위해 표준안을 만들기로 했다.
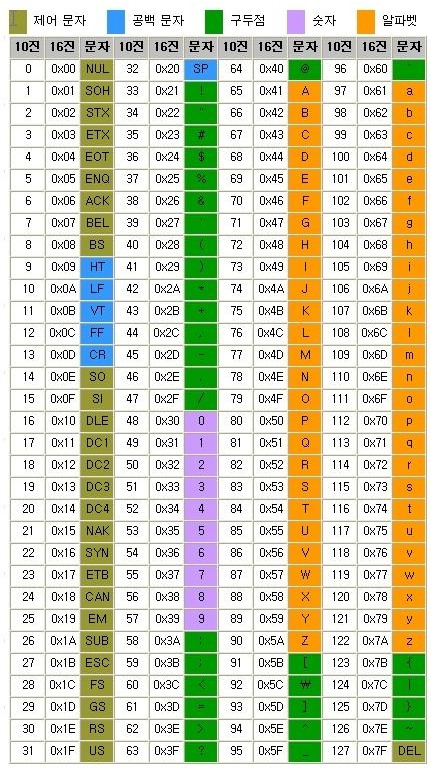
- ASCII(American Standard Code for Information Interchange)라는 문자 인코딩 표준
- ASCII는 7bit 인코딩으로 128문자를 표현하며 33개의 출력 불가능한 제어 문자들과 공백을 비롯한 95개의 출력 가능한 문자들로 이루어져 있음
유니코드의 탄생
인터넷이 전 세계로 발전하면서 ASCII를 만들었을 때의 문제와 같은 문제가 국가간에 정보를 주고 받을 때 발생했다
자국의 코드체계를 타 국가가 가지고 있지 않으면 정보를 잘못 해석할 문제가 발생하는 것이다.
따라서, 다국어 처리를 위해 표준을 마련했고 이를 ‘유니코드’라고 부르기로 했다.
🔛 패턴 매칭
패턴매칭 알고리즘의 종류
- Brute Force(고지식한 패턴 검색)
- KMP
- 보이어-무어
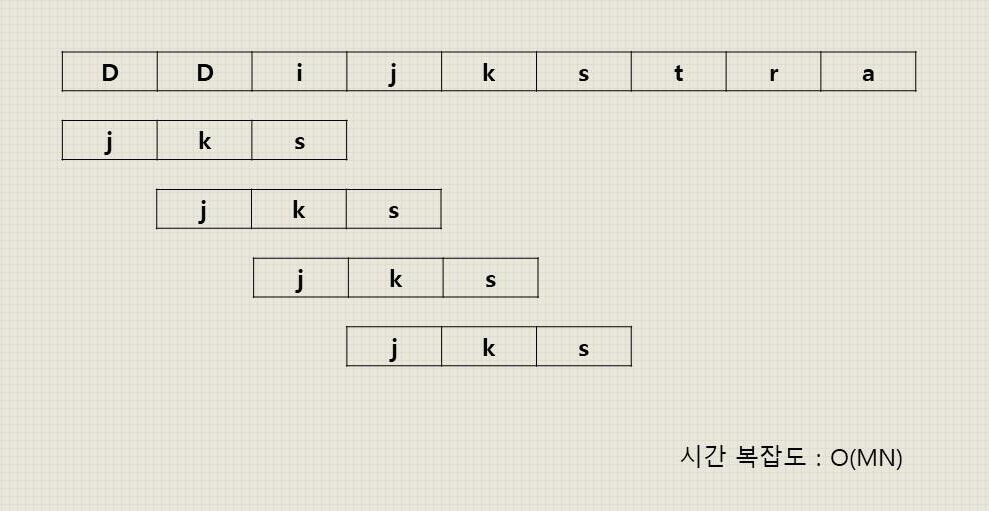
1. Brute Force
- 문자열 내의 글자를 하나하나 일일이 비교하는 방법
- 문자열의 길이가 길어질수록 비효율적인 방법
- 시간 복잡도 : O(MN) - 문자열길이 패턴길이)
python code
pattern = “is” # 찾을 패턴
text = “This is a book” # 전체 텍스트
M = len(p) # 찾을 패턴의 길이
N = len(t) # 전체 텍스트의 길이
def BruteForce(p,t):
i = 0 # text의 인덱스
j = 0 # pattern의 인덱스
while j < M and i < N:
if text[i] != pattern[j]:
i = i-j
j = -1
i = i + 1
j = j + 1
if j == M :
return i - M # 검색 성공
else:
return - 1 # 검색 실패2. KMP
-
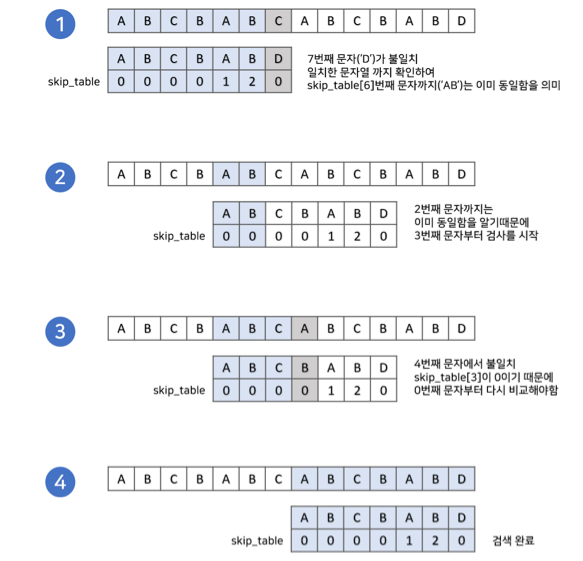
불일치가 발생할 텍스트 문자열의 앞부분에 어떤 문자가 있는지 미리 알고 있기 때문에 불일치가 발생한 앞부분에 대해서 비교하지 않으면서 매칭이 일어나는지 판단할 수 있는 알고리즘
-
시간 복잡도 : O(문자열 길이 + 패턴의 길이)즉, 선형 시간에 끝낼 수 있다.
KMP를 사용해야 하는 이유
- 만약 문자열의 길이가 100,000이고 패턴의 길이가 1,000일 때
- brute-force의 경우, 100,000 * 1,000이기 때문에 1억번 검사를 수행
- KMP의 경우 100,000 + 1,000이기 때문에 101,000번만에 검사가 가능
예시 방법
python code
def kmp(all_string, pattern):
# kmp_table
table = [0 for _ in range(len(pattern))]
i = 0
for j in range(1, len(pattern)):
while i > 0 and pattern[i] != pattern[j]:
i = table[i-1]
if pattern[i] == pattern[j]:
i += 1
table[j] = i
# kmp
result = []
i = 0
for j in range(len(all_string)):
while i > 0 and pattern[i] != all_string[j]:
i = table[i-1]
if pattern[i] == all_string[j]:
i += 1
if i == len(pattern):
result.append(j - i + 1)
i = table[i-1]
return result
3. 보이어-무어
보이어 무어는 KMP알고리즘과 비슷한 이유로 만들어진 알고리즘으로, KMP알고리즘보다 개선된 알고리즘이라고 생각하면 된다.
특징
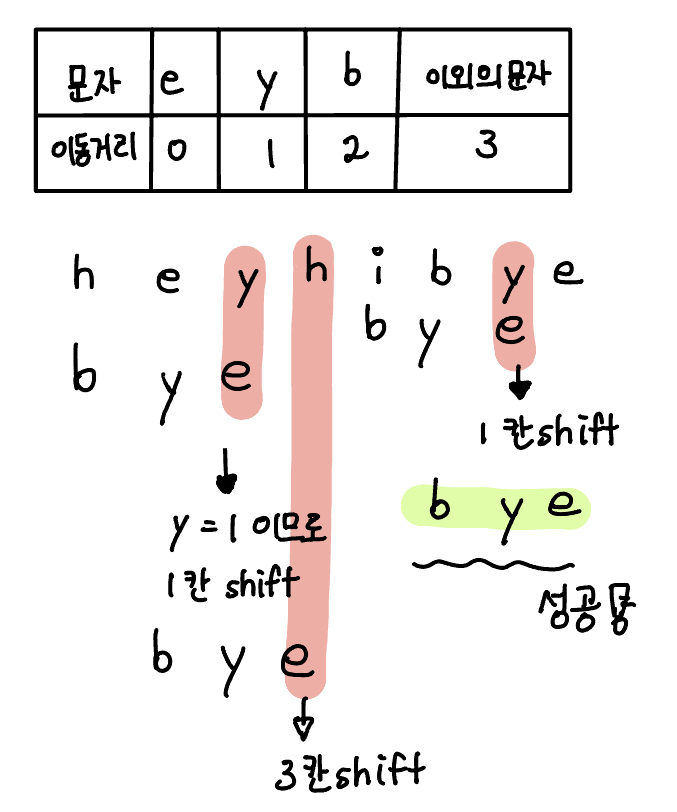
- 오른쪽부터 왼쪽으로 비교한다 (주로 뒤에서 패턴매칭이 틀린다는 생각에서 비롯된 아이디어)
- 뒤에서 부터 비교하다가 틀린부분이 나온다면 마지막 글자와 찾는 문자열 중 일치하는 글자가 있는곳까지 shift한다.
- 2에서 일치하는 부분이 하나도 없다면, 찾는 문자열의 길이만큼 이동한다.
- 현재 상용 프로그램에서 많이 채택한 아이디어이다.
예시 방법
python code
# 보이어-무어 알고리즘
def boyer_moore(pattern, text):
skip = list(reversed(pattern))
matchCnt = 0
nowIndex = len(str1) - 1
# 패턴 매칭 검색
while matchCnt != len(str1) and nowIndex < len(str2):
if str2[nowIndex] in skip:
if str2[nowIndex] == skip[matchCnt]:
matchCnt += 1
nowIndex -= 1
continue
else:
nowIndex += skip.index(str2[nowIndex])
matchCnt = 0
else:
nowIndex += len(str1)
matchCnt = 0
if matchCnt == len(str1):
return 1
if nowIndex >= len(str2):
return 0
T = int(input())
for tc in range(T):
str1 = input()
str2 = input()
print("#%d %d" % (tc + 1, boyer_moore(str1, str2)))