
Link : 프로그래머스 > 2019 KAKAO BLIND RECRUITMENT > 실패율
Language : Python3
정답률 : 55.57%
2019 카카오 블라인드 코테의 8문제 중 2번째로 쉬웠던 문제라고 한다. 모든 테스트 케이스를 통과해야 문제를 푼 것으로 인정되었고, 효율적인 풀이에는 가산점이 붙었다.
Keyward
💡 정렬 - 특정 기준으로 정렬
💡 자료형 - 딕셔너리 or 리스트
Solution
- 주어진 배열의 길이를 이용하여 전체 사용자 수를 구한다.
- 각 스테이지별 실패율을 for문으로 순회하며 구한다.
→ (제한사항) 스테이지에 도달한 사용자가 0명인 경우 예외 처리.- 실패율을 내림차순으로 정렬한다.
→ (제한사항) 만약 실패율이 같은 스테이지가 있다면, 작은 번호의 스테이지가 먼저 오도록 한다.
나의 코드
채점 : 테스트케이스 실패
리스트로 실패율을 구하는 것 까지는 옳은 리턴이 나오는 것을 확인했다.
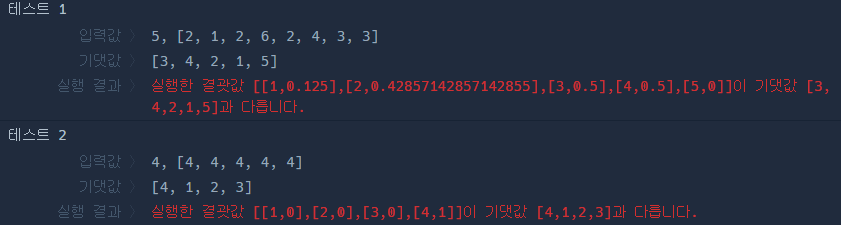
그러나 내림차순구하기에서 막혀서 본격적으로 검색하며 풀기 시작했다. 특정 기준으로 정렬하는 방법을 몰랐던 것이다.
def solution(N, stages):
answer = []
failure = []
decominator_user = len(stages);
# 실패율 구하기
for i in range(1, N+1):
numerator_user = stages.count(i)
# 스테이지에 도달한 유저가 없을 때의 예외처리
if numerator_user == 0:
failure.append(0)
else:
failure.append(numerator_user / decominator_user)
decominator_user -= stages.count(i)
# 내림차순 정렬
answer =
return answer최적화된 코드
다른 사람의 코드를 보니 접근 방법은 아래와 같이 나뉘는 듯 했다.
1. 실패율 구하기
⑴ N을 기준으로 for문 순회 ›› better
⑵ input stages를 기준으로 for문 순회
실패율의 경우는 예외처리를 줄일 수 있는 방법으로 잘 구현한 것 같았다.
2. 내림차순 정렬
⑴ 리스트로 내림차순
처음 프로그래머스로 문제를 킬때 answer 의 자료형이 리스트였어서 failure도 리스트로 구현할 생각만했다. 딕셔너리로 정렬하는 것이 더 간결한 코드가 나온다고 하지만, 일단 생각했던대로 리스트로 정렬을 해보았다.
""" 리스트로 내림차순 """
def solution(N, stages):
answer = []
failure = []
decominator_user = len(stages);
# 실패율 구하기
for i in range(1, N+1):
numerator_user = stages.count(i)
# 스테이지에 도달한 유저가 없을 때의 예외처리
if numerator_user == 0:
failure.append(0)
else:
failure.append(numerator_user / decominator_user)
decominator_user -= stages.count(i)
# 내림차순 정렬
answer = sorted(failure, key=lambda x: (-x[1], x[0]))
answer = [i[0] for i in answer] # list(zip(*answer))[0]
return answerfailure 자료형을 리스트로 내림차순을 할 땐, 스테이지와 실패율 중 스테이지만을 취하는 answer = [i[0] for i in answer] 과정이 필요했다.
⑵ 딕셔너리로 내림차순 ›› better
딕셔너리 자료형을 사용하면 key 와 value로 값을 꺼낼 수 있어 특정 열을 취하기 위한 for문이 불필요해졌다. 코드가 더욱 간결해졌고, 테스트의 속도도 미세하게 더 빨랐다.
""" 딕셔너리로 내림차순 """
def solution(N, stages):
answer = []
failure = {}
decominator_user = len(stages);
# 실패율 구하기
for i in range(1, N+1):
numerator_user = stages.count(i)
# 스테이지에 도달한 유저가 없을 때의 예외처리
if numerator_user == 0:
failure[i] = 0
else:
failure[i] = numerator_user / decominator_user
decominator_user -= stages.count(i)
# 내림차순 정렬
# key와 value중 value를 기준으로 정렬한다.
answer = sorted(failure, key=lambda x: failure[x], reverse=True)
return answerNote
1. 2차원 리스트 특정 열 취하기
Python 답게 inline for loop를 사용하자.
a = [
[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9],
]b = [i[0] for i in a]
print(b) # output : [0, 2, 4, 6, 8]2. list.sort()와 sorted()의 차이
list.sort()
- list 내장 메서드.
- list를 제자리(in-place)에서 수정한다.
None을 반환한다.
sorted()
- 내장 함수.
- 정렬된 새로운 리스트를 반환한다. 원래의 리스트는 영향을 받지 않는다.
- list 뿐만 아니라, 반복 가능(iterable)한 모든 작업에 적용 가능하다.
두 메서드는 반환값 자체가 다르므로 용도가 다르다.
list.sort() 는 기존의 list의 정렬 정보가 필요없고 그 객체 자체를 정렬하고 싶을때 사용하고, sorted()는 기존 list의 정렬 정보가 유의미하고 다른 객체를 생성해 저장하고 싶을때 사용하면 된다.
성능면을 생각하면 어떨까?
list.sort()는 복사본을 만들 필요가 없으므로 sorted()보다 연산이 빠르다. 따라서 list만을 정렬하고 연산량이 많을때는 list.sort()를 사용하는 것이 나을 수 있다. 그러나 메모리의 부담이 없는경우에는 sorted() 를 사용하는게 안전할 것이다.
list가 아닌 iterable에서는 어쩔 수 없이 sorted()를 사용해야 한다.
3. key Functions
list.sort(), sorted() 를 통한 정렬 시 비교 기준이 되는 key 파라미터를 가질 수 있다.
key가 하나일 때의 정렬
"""arr 에 속하는 각 원소들을 x 라고 생각했을 때, x[0]를 기준으로 정렬"""
arr = ['bac', 'bca', 'abc']
arr2 = sorted(arr, key=lambda x : x[0])
print(arr2); # output: ['abc', 'bac', 'bca']key가 여러개일 때의 정렬
"""x[0]를 기준으로 정렬하고 같을 경우 x[1]를 기준으로 정렬하기"""
arr = ['bac', 'bca', 'abc', 'abc']
arr2 = sorted(arr, key=lambda x : (x[0], x[1]))
print(arr2); # output: ['abc', 'abc', 'bac', 'bca']