✅ 우선순위 큐 ADT

우편배달부: 우체국에서 그날 배달해야 할 우편물들을 가방에 넣어 우체국을 출발해서 배달처를 돌며 배달함
배달부A: 우체국에서 가방에 우편물을 담을 때 아무렇게 (fast), 배달 과정에서는 그때그떄의 배달처에 맞는 우편물을 찾아야 하니까 시간 걸림 (slow)배달부B: 우체국에서 가방에 우편물을 담을 때 배달처 주소 순서대로 차곡차곡 (slow), 배달 과정에서는 차례로 꺼내면 되기 때문에 시간 절약 (fast)
또 다른 예로는, 거둬들인 시험 답안지 100장을 학번 순서대로 점수표에 입력한다고 할 때
교수A: 답안지 더미에 놓인 순서대로 채점(fast), 채점완료된 답안지 더미에서 학번 순서대로 찾아내 점수표에 입력함 (slow)교수B: 채점을 마친 답안지를 학번 순으로 쌓고 (slow), 점수 입력함 (fast)
여기서 우리가 알 수 있는 것
공통적으로 "데이터를 저장소에 삽입하고, 이후 저장소로부터 순서대로 삭제함"
이때, 우편배달부의 경우
데이터는 우편물,저장소는 우편가방이고
교수의 경우에는데이터는 답안지,저장소는 채점완료된 답안지 더미이다.
위와 같은 사례에서 누가 더 잘했다고 말하기는 어렵다. 일하는 스타일이 다른 것
저장소의 역할을 하는 추상 데이터 구조를우선순위 큐 ADT라고 한다.
무엇이 우선순위 큐일까?
손에 들고 있는 편지? 신발? 이런게 아니고
바로 우편가방이겠지!
✅ Outline

✅ 5.1 우선순위 큐 ADT
5.11 우선순위 큐 ADT
ADT(Abstract Data Type): 임의의 데이터 항목이 삽입되며, 일정한 순서에 의해 삭제되는 데이터 구조
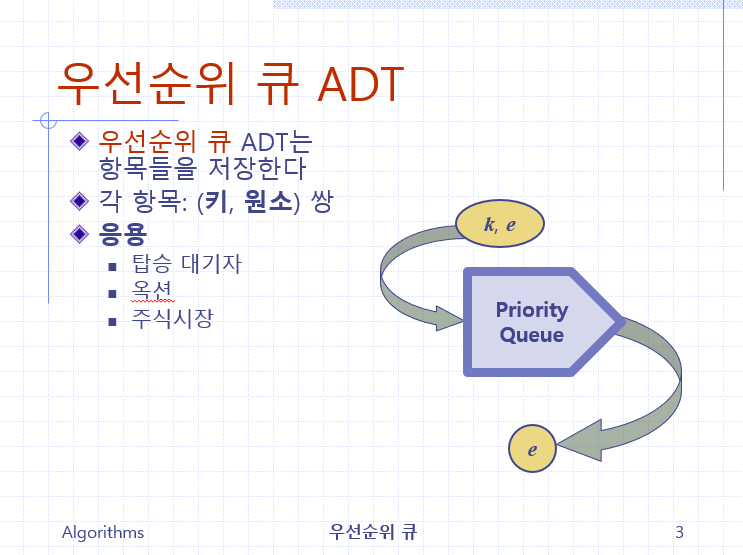
우선순위 큐에 저장되는 각 데이터 항목은 (키,원소)쌍으로 정의
일반적으로 키가 더 간단
우편물의 경우에는 (주소, 우편물)의 쌍이라고 할 수 있고,
답안지의 경우에는 (학번,점수) 쌍이라고 할 수 있다.
Q. 큐와 우선순위 큐의 차이점?
둘다 임의의 데이터 항목을 저장하고 주요 작업으로 삽입과 삭제가 가능하다는 점은 같다.
하지만, 큐가 삽입된 순서 그대로 삭제된다면, 우선순위 큐는 키 순서에 따라 삭제된다는 점에서 차이가 있음
5.12 우선순위 큐 응용
Q. 우선순위 큐 응용사례
ex1. 경매 시장
어떤 상품의 경매에 참여한 응찰자들 가운데 시간적으로 가장 먼저 응찰한 응찰자보다는 최고가를 써낸 응찰자 낙찰시킬 것이다.
=> 응찰자 리스트: 우선순위 큐
=> 최고가 응찰자 찾아내 낙찰시키는 것: 삭제
ex2. 주식시장
=> 주식거래를 원하는 사자/팔자 주문들의 리스트: 우선순위 큐
=> 이 가운데 최고가 사자나 최저가 팔자 주문이 우선적으로 처리되는 것: 삭제
Q. 우선순위 큐의 중요한 응용: 정렬
정렬(sort): 데이터원소들을 일정한 키 순서에 의해 다시 배치하는 것
정렬과정에서 데이터원소들을 임시 보관하는 저장소를 이용하는 경우가 많은데, 우선순위 큐를 저장소로 이용하여 정렬하는 방법이 있다.
5.13 우선순위 큐 ADT 메쏘드

주요 메쏘드
insertItem(k,e): 들어가는 화살표
element removeMin(): 나가는 화살표
- min만 잘하면 max도 할 수 있으니까 min만 집중해서
일반 메쏘드
integer size(): 가방 속 배달 안한 우편물이 몇개
boolean isEmpty(): False, True 반환, 우편물을 다 배달하고 비어 있으면 True가 나오겠지
접근 메쏘드
삽입하거나 삭제하지 않고 들여다만 봄
element minElement(): 가방 속에 있는 우편물 중에 가장 가까운 주소의 우편물
element minKey(): 가방 속에 있는 우편물 중에 가장 가까운 주소
예외
emptyQueueException(): 우편물이 없는데 배달하라는 시도하는 경우
fullQueueException(): 가방이 꽉 찼는데 우편물을 더 넣으려는 경우
✅ 5.2 우선순위 큐를 이용한 정렬

크기 비교 가능한 원소 집합을 정렬하는데 우선순위 큐를 이용할 수 있다.
- 연속적인
insertItem(e,e)작업을 통해 원소들을 하나씩 삽입
(key=e로 전제함, 간단하게 표시하기 위해)
-> 어디에 삽입하나? 제 2의 장소를 만들어야겠지!- 연속적인
removeMin()작업을 통해 원소들을 정렬 순서로 삭제
-> 제 2의 공간에서 삭제를 하자는 말이지
🔅 알고리즘 PQ-Sort
Alg PQ-Sort(L)
input list L
output sorted list L
//비어 있는 '우선순위 큐 P'를 초기화
1. P <- empty priority queue
// 입력 리스트 L의 원소들을 차례로 삭제하여 P에 삽입
2. while (!L.isEmpty())
e <- L.removeFirst()
P.insertItem(e)
//P로부터 최소 키를 가진 원소부터 차례로 삭제하여 L에 삽입
3. while (!P.isEmpty())
e <- P.removeMin()
L.addLast(e)
//정렬된 리스트 L을 얻을 수 있음
4. return[그림 5-2]
key(키): 키(height)일 때 알고리즘 PQ-Sort를 이용하면 다음과 같이 나타남
➰ 알고리즘 PQ-Sort의 특징
알고리즘 PQ-Sort는 수행 대상인 리스트 L이 배열 or 연결리스트 중 어느 것으로 구현되었는지와 무관하게 작동함. 우선순위 큐 P에 대해서도 마찬가지로 P의 상세구현을 특정하지 않는다.
L와P처럼 상세 구현이 특정되지 않은 데이터구조:일반(generic) 데이터구조
일반 데이터구조를 사용한 알고리즘은 특정 데이터구조를 대상으로 작성된 알고리즘에 비해
한 차원 높은 추상의 차원에서 알고리즘을 제시하는 만큼 가독성이 높은 것은 물론 응용 범위도 넓다.
➰ 알고리즘 PQ-Sort의 단계별 실행시간
우선순위 큐의 상세 구현에 따라 다름
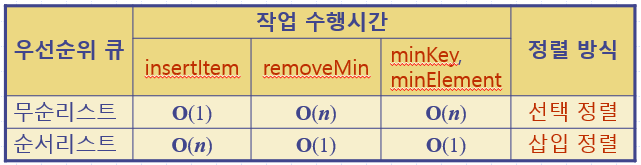
➰ 우선순위 큐 P를 '무순리스트(unordered list)'로 구현하는 경우
- 우선순위 큐의 항목들을 리스트에 임의 순서로 저장
- 성능
: 메쏘드 insertItem은 시간에 수행
(항목을 리스트의 맨 앞 or 맨 뒤에 삽입할 수 있기 때문)
: removeMin, minKey, minElement 등 작업은 시간 수행
(전체 리스트를 순회하면서 찾아야 하기 때문)
➰ 우선순위 큐 P를 '순서리스트(ordered list)'로 구현하는 경우
- 우선순위 큐의 항목들을 리스트에 키 순서로 저장
- 성능
: 메쏘드 insertItem은 시간에 수행
(항목을 삽입할 곳을 찾아야 하기 때문)
: removeMin, minKey, minElement 등 작업은 시간 수행
(최소 키를 가진 항목이 맨 앞에 있기 때문)
🔅 선택 정렬(selection sort)
PQ-Sort의 일종으로 우선순위 큐가 무순리스트로 구현
실행시간
- 회의
insertItem작업을 사용하여 원소들을 우선순위 큐에 삽입하기 때문에 시간 소요 - 회의
removeMin작업을 사용하여 원소들을 우선순위 큐로부터 키 순서로 삭제하는데 에 비례하는 시간 소요
즉, 선택정렬은 시간에 수행함
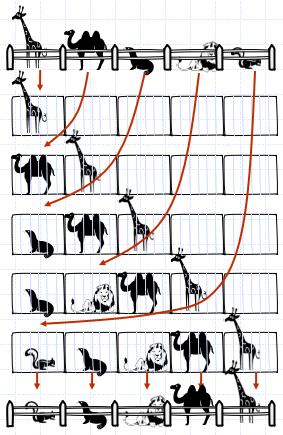
아래 예시를 살펴보면,
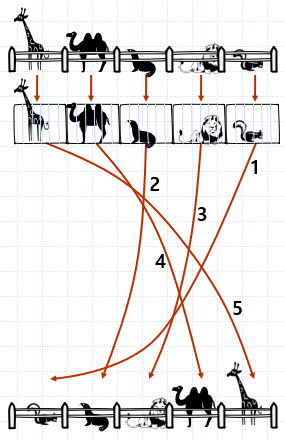 (1) 울타리 속 동물들은 하나씩 차례대로 우리로 옮겨진다.
(1) 울타리 속 동물들은 하나씩 차례대로 우리로 옮겨진다.
(2) 키가 작은 것부터 차례로 골라내(이 때문에 '선택정렬') 우리에서 울타리로 옮겨져 정렬이 완료
🔅 삽입 정렬(insertion sort)
PQ-Sort의 일종으로 우선순위 큐가 순서리스트로 구현
실행시간
- 회의 insertItem 작업을 사용하여 원소들을 우선순위 큐에 삽입하기 때문에 에 비례하는 시간 소요
- 회의 removeMin 작업을 사용하여 원소들을 우선순위 큐로부터 키 순서로 삭제하는데 시간 소요
즉, 삽입정렬은 시간에 수행함
아래 예시를 살펴보면,
(1) 울타리 속 동물들은 하나씩 차례대로 우리로 옮겨진다. 이때, 키 순서에 따라 자기 키에 맞는 위치에 삽입(이 때문에 '삽입'정렬)되는 방식으로!
(2) 삽입 단계가 완료된 후, 첫번째 우리부터 시작하여 차례로 울타리로 옮겨져 정렬 완성
선택정렬과 삽입정렬 관계에 대해
둘이 같은 알고리즘이지만. 주요 데이터구조인 우선순위 큐 P가 어떻게 구현되었는지에 따라 다른 것
- P를 무순리스트로 구현하면 선택정렬
- P를 순서리스트로 구현하면 삽입정렬
울타리:L의 역할우리:P의 역할
✅ 5.3 제자리 정렬
동물이 다섯 마리인 경우 동물들의 임시 저장소로서 정확히 다섯 개의 우리가 필요한데,
이 우리(Q)들은 원래 제공된 내부 공간인 울타리 이외에 정렬을 위해 추가로 소요되는 공간이므로
외부공간이라 할 수 있다.
동물이 마리라면 우리가 개 필요할 것
선택정렬, 삽입정렬 모두 크기의 외부 우선순위 큐를 사용하여 리스트 정렬함!
그러나
원래 리스트 자체를 위한 내부 공간 이외에 추가로 크기의 외부 공간만을 사용한다면
이를 제자리(in-place)에서 수행한다고 한다.
즉, 우리를 전혀 사용하지 않고 울타리만 사용하여 정렬을 수행한다면
제자리 정렬
❓ 제자리 정렬의 의의
제자리냐 아니냐는 종종 중요함
예를 들어, 우리 한 개를 빌려오는데 비싼 값을 치뤄야 한다고 가정한다면
정렬할 때마다 동물 수 에 비례하는 만큼의 비용이 들 것이다 ㅠ
반면에, 우리를 전혀 빌리지 않거나 겨우 몇 개, 즉 상수 개수의 우리로만 수행한다면 비용절감의 효과가 있을 것!
어떤 정렬 알고리즘이 정렬 대상 개체를 위해
원래 제공된 메모리에다 오직 상수 메모리만을 추가적으로 사용한다면
해당 정렬 알고리즘은제자리 수행한다고 얘기함
🔅 제자리 선택 정렬
선택정렬이 외부 데이터구조를 사용하는 대신 제자리에서 수행하도록 구현 가능함
- 리스트의 앞 부분을 정렬 상태로 유지
- 리스트에서 원소를 삭제하는 대신 원소들의 자리를 맞바꿈
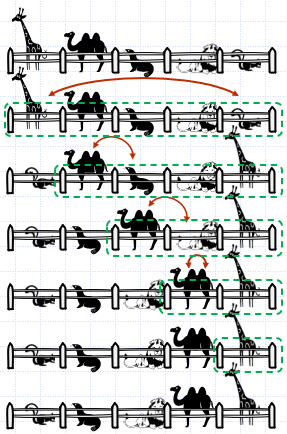
- 점선으로 둘러싸인 부분은
우리, 즉 우선순위 큐 역할을 하는 공간을 의미
정렬의 각 단계마다
현재 우선순위 큐에서 최소 키를 가진 동물을
우선순위 큐의 가장 왼쪽 자리의 동물과 위치를 맞바꾼다.
- 초기에는 입력 리스트 전체가 우선순위 큐로 설정되며 정렬이 진행됨에 따라 우선순위 큐의 크기가 5,4,3,2,1,0으로 왼쪽에서부터 한 칸씩 좁아짐
🔅 제자리 삽입 정렬
삽입정렬이 외부 데이터구조를 사용하는 대신 제자리에서 수행하도록 구현 가능함
- 리스트의 앞 부분을 정렬 상태로 유지
- 리스트에서 원소를 삭제하는 대신 원소들의 자리를 맞바꿈
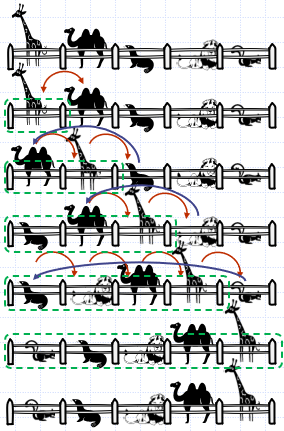
- 점선으로 둘러싸인 부분은
우리, 즉 우선순위 큐 역할을 하는 공간을 의미
정렬의 각 단계마다
현재 우선순위 큐에 십입되지 않은 동물 중 가장 왼쪽의 동물을
우선순위 큐 순에 따른 자기 자리에 삽입한다.
- 초기에는 우선순위 큐가 비어 있는 것으로 설정되며 정렬의 단계가 진행됨에 따라 우선순위 큐의 크기가 o,1,2,3,4,5 오른쪽방향으로 한 칸씩 넓어짐
제자리 선택 정렬 & 제자리 삽입 정렬 알고리즘 구현
제자리 버전인 만큼 입력 배열의 크기 n과 상관 없이
pass, minLoc, j, save 등 상수 메모리로 충분한 몇 개의 기초변수만 사용하는 것 유의하기!

Alg inPlaceSelectionSort(A)
input array A of n keys
output sorted array A
1. for pass // 0 to (n- 2)
minLoc <-pass //우선순위 큐 안에서 가장 첫번째 원소를 설정
for j // (pass+1) to (n-1) 우선순위 큐 안에서 가장 첫번째 원소를 제외하고 크기 비교하기
if (A[j] < A[minLoc]) // 첫번째 원소보다 작은게 있으면 바꾸기
minLoc <- j
A[pass] <-> A[minLoc]
2. returnAlg inPlaceInsertionSort(A)
input array A of n keys
output sorted array A
1. for pass // 1 to (n-1) 우선순위 큐에 십입되지 않은 동물 중 가장 왼쪽의 원소
save <- A[pass]
j <- pass-1 // 우선순위 큐에 십입된 동물 중 가장 오른쪽의 원소
while ((j>=0) & (A[j]>save)) // 우선순위 큐에 십입된 동물이 더 크다면 오르쪽으로 옮기기
A[j+1] <- A[j]
j <- j-1
A[j+1] <- save
2. return✅ 5.4 선택 정렬과 삽입 정렬 비교
🔅 공통점
전체적으로 시간에 수행함
중첩 반복문으로 작성되는데
- 내부 반복문은
선형 탐색을 수행하므로 시간에 수행 - 외부 반복문은 개의
정렬 단계(패스)로 구성
두 알고리즘 모두 제자리 버전은 공간을 소요함
두 알고리즘 모두 구현이 단순하다는 장점이 있으므로, 입력 크기 n이 작은 경우에 유용
🔅 차이점
if 초기 입력 리스트가 완전히 or 거의 정렬된 경우라면
제자리 삽입 정렬이 제자리 선택 정렬보다 빠르다
because 제자리 삽입 정렬 알고리즘의 내부 반복문이 매번 시간만 소요하기 때문
외부 반복문의 수행 횟수까지 곱하면 전체적으로 시간만이 소요됨
if 데이터원소끼리 교환작업(메쏘드 swapElements)에 시간이 걸리는 경우라면
제자리 선택 정렬이 제자리 삽입 정렬보다 빠르다
because 제자리 선택 정렬의 경우 교환 작업이 패스마다 회 수행되는데 비해
제자리 삽입 정렬의 경우에는 최악의 경우 패스마다 번 수행되어야 하기 때문
✅ 5.5 응용 문제
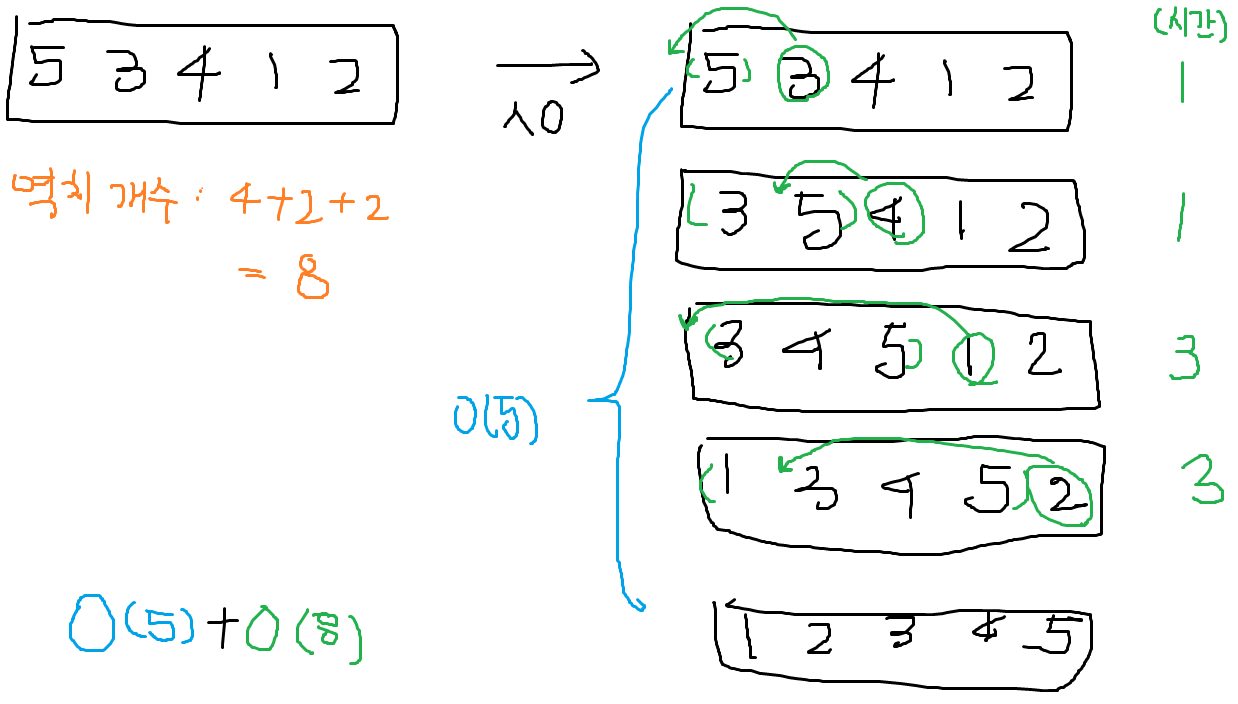
5.51 역치와 삽입 정렬
L을 n개의 원소로 이루어진, 전체 순서 관계가 정의된 리스트로 가정하자
L내의
역치(inversion)란 가 앞에 나타나지만
> 인 원소 쌍 를 말한다.
Q. 정수 범위의 유일한 원소로 이루어진 크기 의 리스트 내에 '최대 가능한 역치의 수'와 이때의 '의 원소 배치'를 구하라.
<최대 가능한 역치의 수>
<의 원소 배치>
내림 차순일 때(역정렬)
Q. 만약 모든 원소가 바른 자리(즉, 정렬 시점에 있어야 할 자리)에서 칸 이내에 위치한다면 에 대한 삽입 정렬 수행에 시간이 소요됨을 설명하라.
hint) 삽입 정렬 알고리즘을 검토하여 우선, 가 리스트 내의 총 역치의 수라고 할 때 삽입정렬이 시간에 수행함을 설명하라.
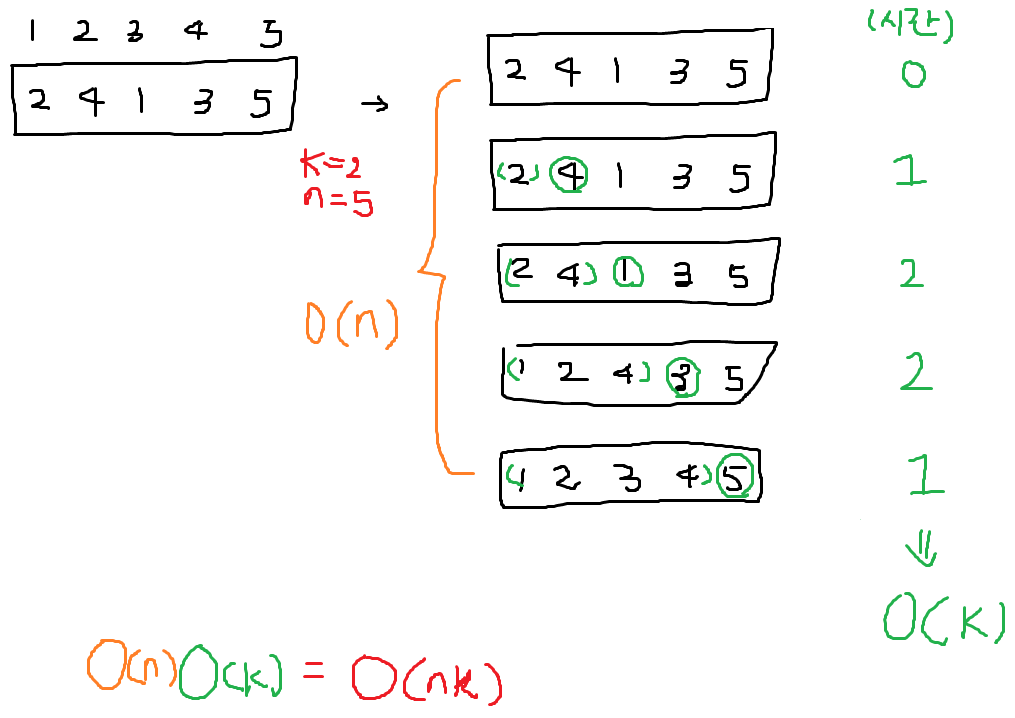
✅ 요약
우선순위 큐 ADT는 임의의 데이터 항목이 삽입될 수 있는 저장소로써 삭제 시에는 최소 키를 가진 항목부터 삭제되는 데이터 구조를 말한다.- 우선순위 큐를 이용하여 정렬을 수행할 수 있다.
선택 정렬은 우선순위 큐가무순리스트로,삽입정렬은 우선순위 큐가순서리스트로 구현된다. - 일반적으로 어떤 정렬 알고리즘이 정렬 대상 개체를 위해 원래 제공된 메모리에 추가하여 오직 상수 메모리만을 사용한다면, 해당 정렬 알고리즘이
제자리에서 수행한다고 말한다. - 선택 정렬과 삽입정렬은 모두 총 시간에 수행한다.
if 초기 입력 리스트가 완전히 or 거의 정렬된 경우라면 삽입정렬 faster
if 데이터 원소끼리의 교환 작업에 시간이 많이 걸리는 경우라면 선택 정렬 faster
✅ 연습문제
5-1 정렬 연습
Q. 다음 입력 리스트에 대한 제자리 선택 정렬과 제자리 삽입 정렬의 수행 내용을 예시하라.
입력 리스트 : 22 15 36 44 10 3 9 13 29 25
<제자리 선택 정렬>
(`22` 15 36 44 10 `3` 9 13 29 25)
3 (`15` 36 44 10 22 `9` 13 29 25)
3 9 (`36` 44 `10` 22 15 13 29 25)
3 9 10 (`44` 36 22 15 `13` 29 25)
3 9 10 13 (`36` 22 `15` 44 29 25)
3 9 10 13 15 (`22` 36 44 29 25)
3 9 10 13 15 22 (`36` 44 29 `25`)
3 9 10 13 15 22 25 (`44` `29` 36)
3 9 10 13 15 22 25 29 (`44` `36`)
3 9 10 13 15 22 25 29 36 (44)
3 9 10 13 15 22 25 29 36 44<제자리 삽입 정렬>
(22) `15` 36 44 10 3 9 13 29 25
(15 22) `36` 44 10 3 9 13 29 25
(15 22 36) `44` 10 3 9 13 29 25
(15 22 36 44) `10` 3 9 13 29 25
(10 15 22 36 44) `3` 9 13 29 25
(3 10 15 22 36 44) `9` 13 29 25
(3 9 10 15 22 36 44) `13` 29 25
(3 9 10 13 15 22 36 44) `29` 25
(3 9 10 13 15 22 29 36 44) `25`
(3 9 10 13 15 22 25 29 36 44)
3 9 10 13 15 22 25 29 36 445-2 최악의 제자리 삽입 정렬
Q. 제자리 삽입 정렬에 대한 최악의 입력 리스트의 예를 들어라. 또한 그러한 리스트에 대해 제자리 삽입 정렬이 시간에 수행함을 설명하라.
일단 외부 반복문에 대해서는 작업을 수행함
내부 반복문에 대해서 생각해보자.
최악의 경우 모든 원소마다 swap해야 하는 경우가 발생할 수 있음
따라서 =
본 게시물은 세종대학교 알고리즘 수업교재 '알고리즘 원리와 응용'(국형준 지음)을 정리하였습니다.
