numpy , pandas , matplot, 데이터 가공, 모델링 예시
NaN 값 파악후 없애기Pandas 데이터 전처리 예시Sequential apidummy encodingfunction apimake_column_transformeronehotencodertrain / test 분리상관계수 분석상관계수 확인원하는 열만 가져오기정규화조기종료특정 칼럼값 추출특정열 지우기특정열의 특정값만 남기기표준화해당 구분자로 분리
0
Python 데이터 분석
목록 보기
1/1

⚡데이터 가져와서 해당 구분자로 분리하고 원하는 열만 가져오기df_data = pd.read_csv('http://www.randomservices.org/random/data/Galton.txt', sep='\t', usecols=['Father', 'Gender', 'Height']) print(df_data.head(2)) # Father Gender Height #0 78.5 M 73.2 #1 78.5 F 69.2⚡특정열의 특정값만 남기고, 해당열은 지워버리기
son_data = df_data[df_data['Gender'] == 'M'].drop('Gender' , axis = 1) # Father Height # 0 78.5 73.2 # 4 75.5 73.5⚡특정 칼럼값 추출, 상관계수 분석
father_x = son_data.Father son_y = son_data.Height print('corrcoef : ', np.corrcoef(father_x, son_y))⚡train / test 분리
from sklearn.model_selection import train_test_split train_x, test_x, train_y, test_y = train_test_split(father_x, son_y, test_size=0.3, random_state=1) print(train_x.shape, test_x.shape)⚡Sequential api 모델
import tensorflow as tf from keras.models import Sequential from keras.layers import Dense # 1) 모델 네트워크 구성 model = Sequential() model.add(Dense(units=5, input_dim=1, activation='linear')) model.add(Dense(1, activation='linear')) print(model.summary()) # 2) 모델 학습 과정 설정 opti = tf.keras.optimizers.Adam(learning_rate=0.001) # adam 사용 model.compile(optimizer=opti, loss='mse', metrics=['mse']) # 3) 모델 학습 history = model.fit(x=train_x, y=train_y, epochs=50, batch_size=4, verbose=0) # 4) 모델 평가 loss_metrics = model.evaluate(x=test_x, y=test_y, verbose=0) print('loss metrics: ', loss_metrics) # loss metrics: [6.919643402099609, 6.919643402099609] # 5) 예측값 출력 print('실제값 : ', test_y.head().values) # 실제값 : [72. 70.5 66. 69. 72. ] print('예측값 : ', model.predict(test_x).flatten()[:5]) # 예측값 : [68.58027 69.07017 67.60047 68.58027 70.539856] # 6) 새로운 값 예측 new_height = [75, 70, 80] print('새로운 예측값: ', model.predict(new_height).flatten()) # 새로운 예측값: [74.45905 69.56007 79.35804] # 7) 시각화 import matplotlib.pyplot as plt plt.rc('font', family='malgun gothic') plt.plot(train_x, model.predict(train_x), 'b', train_x, train_y, 'ko') # train plt.show() plt.plot(test_x, model.predict(test_x), 'b', test_x, test_y, 'ko') # test plt.show() plt.plot(history.history['mse'], label='평균제곱오차') plt.xlabel('학습 횟수') plt.show()⚡Function api 모델
from keras.layers import Input from keras.models import Model # 각 층은 일종의 함수처럼 처리함 inputs = Input(shape=(1,)) # 이전층을 다음층의 파라미터로 넣어주는게 포인트 output1 = Dense(units=5, activation='linear')(inputs) outputs = Dense(1, activation='linear')(output1) model2 = Model(inputs, outputs) print(model2.summary()) opti = tf.keras.optimizers.Adam(learning_rate=0.001) model2.compile(optimizer=opti, loss='mse', metrics=['mse']) history = model2.fit(x=train_x, y=train_y, epochs=50, batch_size=4, verbose=0) loss_metrics2 = model2.evaluate(x=test_x, y=test_y, verbose=0) print('loss metrics: ', loss_metrics2) print('실제값 : ', test_y.head().values) print('예측값 :', model2.predict(test_x).flatten()[:5]) new_data = [75, 70, 80] print('새로운 예측 키 값: ', model2.predict(new_data).flatten())
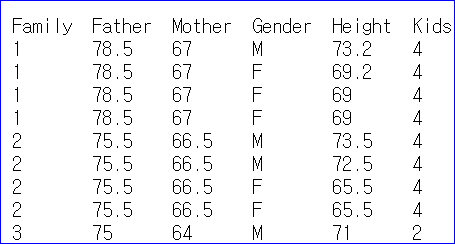
⚡ 상관계수 확인 예시
df = pd.read_csv("https://raw.githubusercontent.com/pykwon/python/master/data/train.csv", sep=',') df.drop(columns='datetime', inplace=True) # datetime열 빼기 # 상관계수 확인 co_re=df.corr() print(co_re['count'].sort_values(ascending=False) # count기준 상관계수 , 내림차순 #count 1.000000 #registered 0.970948 #casual 0.690414 #temp 0.394454 #atemp 0.389784 #season 0.163439 #windspeed 0.101369 #workingday 0.011594 #holiday -0.005393 #weather -0.128655 #humidity -0.317371 #Name: count, dtype: float64 # feature, label 나누기 x = df.loc[:,['registered','casual','temp','atemp','humidity']] # registered casual temp atemp humidity # 0 13 3 9.84 14.395 81 # 1 32 8 9.02 13.635 80 y = df.iloc[:,-1] # 0 16 # 1 40⚡ 정규화
값을 0~1 사이로 Scaling
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler(feature_range=(0,1)) x= scaler.fit_transform(x)⚡ 표준화
평균이 0 , 표준편차가 1로 Scaling
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() x_train = scaler.fit_transform(x_train) x_test = scaler.fit_transform(x_test)

⚡ 데이터 세트 Dummy Encoding
data = pd.read_csv('mushrooms.csv') print(data.head(3)) # class cap-shape cap-surface ... spore-print-color population habitat # 0 p x s ... k s u # 1 e x s ... n n g # 2 e b s ... n n m print(data.info()) # RangeIndex: 8124 entries, 0 to 8123 # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 class 8124 non-null object # 1 cap-shape 8124 non-null object # 2 cap-surface 8124 non-null object from sklearn.preprocessing import LabelEncoder encoder = LabelEncoder() for colname in data.columns: data[colname] = encoder.fit_transform(data[colname]) print(data.info()) # RangeIndex: 8124 entries, 0 to 8123 # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 class 8124 non-null int32 # 1 cap-shape 8124 non-null int32 # 2 cap-surface 8124 non-null int32
⚡ NaN 값 파악후 없애기
# 불러올 파일에 ? 값을 na로 대체했었던 dataset dataset = pd.read_csv('../testdata/auto-mpg.csv', na_values= '?') # nan 파악 print(dataset.isna().sum()) # mpg 0 # cylinders 0 # displacement 0 # horsepower 6 # weight 0 # acceleration 0 # model year 0 # origin 0 # dtype: int64 # nan 없애기 dataset = dataset.dropna() print(dataset.isna().sum()) # mpg 0 # cylinders 0 # displacement 0 # horsepower 0 # weight 0 # acceleration 0 # model year 0 # origin 0 # dtype: int64
⚡ 조기종료 (early stopping)
# loss가 5회 이내로 더 안떨어지면 조기종료하기 history = model.fit(x_train, y_train, epochs = 100, batch_size = 32, validation_split=0.25, callbacks=[tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)])
⚡ OneHotEncoder , make_column_transformer
train_df = pd.read_excel("../testdata/hd_carprice.xlsx", sheet_name='train') test_df = pd.read_excel("../testdata/hd_carprice.xlsx", sheet_name='test') print(train_df.head(2), train_df.shape) # 가격 년식 종류 연비 마력 토크 연료 하이브리드 배기량 중량 변속기 # 0 1885 2015 준중형 11.8 172 21.0 가솔린 0 1999 1300 자동 # 1 2190 2015 준중형 12.3 204 27.0 가솔린 0 1591 1300 자동 (71, 11) print(test_df.head(2), test_df.shape) # 가격 년식 종류 연비 마력 토크 연료 하이브리드 배기량 중량 변속기 # 0 1915 2015 대형 6.8 159 23.0 LPG 0 2359 1935 수동 # 1 1164 2012 소형 13.3 108 13.9 가솔린 0 1396 1035 자동 (31, 11) # 전처리 x_train = train_df.drop(['가격'], axis=1) # feature x_test = test_df.drop(['가격'], axis=1) y_train = train_df[['가격']] # label y_test = test_df[['가격']] print(x_train.head(2), x_train.shape, x_train.columns) # 년식 종류 연비 마력 토크 연료 하이브리드 배기량 중량 변속기 # 0 2015 준중형 11.8 172 21.0 가솔린 0 1999 1300 자동 # 1 2015 준중형 12.3 204 27.0 가솔린 0 1591 1300 자동 (71, 10) Index(['년식', '종류', '연비', '마력', '토크', '연료', '하이브리드', '배기량', '중량', '변속기'], dtype='object') print(set(x_train.종류)) # {'대형', '준중형', '소형', '중형'} print(set(x_train.연료)) # {'LPG', '가솔린', '디젤'} print(set(x_train.변속기)) # {'자동', '수동'} # OneHotEncoder로 해보기 from sklearn.preprocessing import OneHotEncoder # 3개를 한꺼번에 하기 --> make_column_transformer 사용 from sklearn.compose import make_column_transformer transform = make_column_transformer((OneHotEncoder(), ['종류','연료','변속기']), remainder='passthrough') transform.fit(x_train) x_train = transform.transform(x_train) # 세 개의 열이 참여해 원핫 수행 후 모든 칼럼을 표준화 x_test = transform.transform(x_test) print(x_train[:2]) # 16개 / 9-3 + 10 # [[0.000e+00 0.000e+00 1.000e+00 0.000e+00 0.000e+00 1.000e+00 0.000e+00 # 0.000e+00 1.000e+00 2.015e+03 1.180e+01 1.720e+02 2.100e+01 0.000e+00 # 1.999e+03 1.300e+03] # [0.000e+00 0.000e+00 1.000e+00 0.000e+00 0.000e+00 1.000e+00 0.000e+00 # 0.000e+00 1.000e+00 2.015e+03 1.230e+01 2.040e+02 2.700e+01 0.000e+00 # 1.591e+03 1.300e+03]] print(x_train.shape) # (71, 16) print(y_train.shape) # (71, 1)

열심히 할거야