wecode 오프라인 생활 시작하고 가장 큰 난관인 데이터베이스 모델링을 하게 되었다.
database 관련해서 이론으로 수업을 받고, 기본적인 django 사용을 위해 쫒아가느라 정리하는 게 좀 늦어졌다;;;;;
1. 스타벅스 modeling 하기
기본적인 데이터베이스 정리
데이터베이스는 데이터를 저장하는 공간을 의미한다. 휘발성인 메모리와는 다르게 오랜기간 저장되어 있지만 속도가 느려서 주로 데이터를 저장하는 데만 사용이된다.
데이터베이스의 종류는 관계형 데이터베이스(mysql, oracleDB)와 비관계형 데이터베이스(NOsql)가 있다.
관계형데이터베이스(RDMS)는 데이터끼리는 상호관련성을 가진 형태로 표현한 데이터를 말합니다. 세 가지의 관계가 있는데
- A 한 row와 B의 row 한 개씩 매칭되어있는 'one to one', A의 row 한 개와 B의 여러 row가 매칭되어 있는 'one to many', A의 row 여러개와 B의 row 여러개가 매칭 되어 있는 many to many 관계가 있다.
비관계형데이터베이스는 데이터들을 저장하기 전에 정의를 할 필요가 없다. 관계형 데이터베이스는 데이터들을 저장하기 전에 어디에 어떻게 저장할 것인가를 정의 해야 한다. 즉 테이블을 정의해야함(테이블 이름, 테이블과 다른 테이블의 관계, 각 컬럼의 타입)
관계형 데이터베이스는 foreignkey로 연결을 한다.
하나의 테이블에 모든 데이터를 넣어서 관계형으로 하지 않으면 동일한 정보들이 불필요하게 저장되기 때문에 더 많은 디스크를 사용하게되고, 잘못된 데이터가 저장될 가능성이 높아집니다. 이런 점이 관계형 데이터베이스를 사용함으로써 디스크를 더욱 효율적으로 쓰고, 문제점이 사라지게 됩니다. 이를 정규화 라고 합ㄴ디ㅏ.
트랜잭션: 일련의 작업이 진행이 됨에 있어 한번에 하나의 작업처럼 취급되어서 모두 다 성공하거나 아니면 모두 시작하는 것을 이야기 합니다.
스타벅스 모델링 하기!!
기존에 배웠던 one to one, one to many, many to many를 데이터베이스로 직접만들어 볼 수 있었다.
- 메뉴(menu), 음료설정(), 알러지, 카테고리, 음료이미지, 영양정보, 신상여부
1. 메뉴 & 카테고리 - 한 가지의 메뉴는 여러 카테고리를 가지고 있습니다.
음료 - 콜드브루커피, 브루드 커피, 에소프레소, 프라푸치노, 블렌디드, 스타벅스피지오, 티(티바나)
-> 한 메뉴(A의 한 개의 row)와 여러 카테고리(B의 여러카테고리를 가지고 있습니다.) 즉 one to many의 관계입니다.
2. 카테고리 & 제품 - 한 가지의 카테고리는 여러제품들을 가지고 있습니다.
콜드브루커피 - 나이트로 바닐라크림.......등 등
-> 한 카테고리(A의 한 열)은 여러 제품들(B의 여러 열)에 매칭되어 있습니다. one to many의 관계이다.
3. 제품의 상세 정보 - 음료 제품 하나는 설명, 음료이미지, 신상 여부가 포함되어 있습니다.
-> 음료 제품 하나은 설명 1개, 음료 하나당 이미지, 음료 한개당 신상여부 의 열((A의 1개의 열 B의 1개의 열)에 매칭되어 있습니다. - one to one)으로 되있습니다. one to one 의 관계입니다.
-> 이 거는 만드는 방법에 따라서 one to one이 될 수도 있고 one to many가 될 수 도 있다.
4. 하나의 음료는 여러 알러지 정보를 가지고 있을 수 있습니다. 동시에 하나의 알러지 정보 또한 여러 음료를 가질 수 있습니다.
-> 하나의 음료는 여러개의 알러지 정보를 가질 수 있고, 한 개의 알러지 정보는 여러개의 음료를 가질 수 있기 때문에 many to many의 관계를 가질 수 있다. many to many의 관계는 만들때 중간 행을 만들어서 참조하는 형식으로 만든다.
5. 하나의 음료는 한가지의 영양정보세트를 가질 수 있습니다.
-> 하나의 음료는 한 가지의 영양정보세트 - one to one관계
6. 화살표는 foreignkey에서 Primary Key로 향한다.
-> 하지만 화살표 방향에 중요함을 두지 않았으면 한다. 현업에서 데이터베이스 모델링을 직접 만드는 것도 중요하지만, 이걸 보고 무슨 관계인지 파악하고 어떻게 구성되어있는지 아는 것이 중요합니다. !!!!!
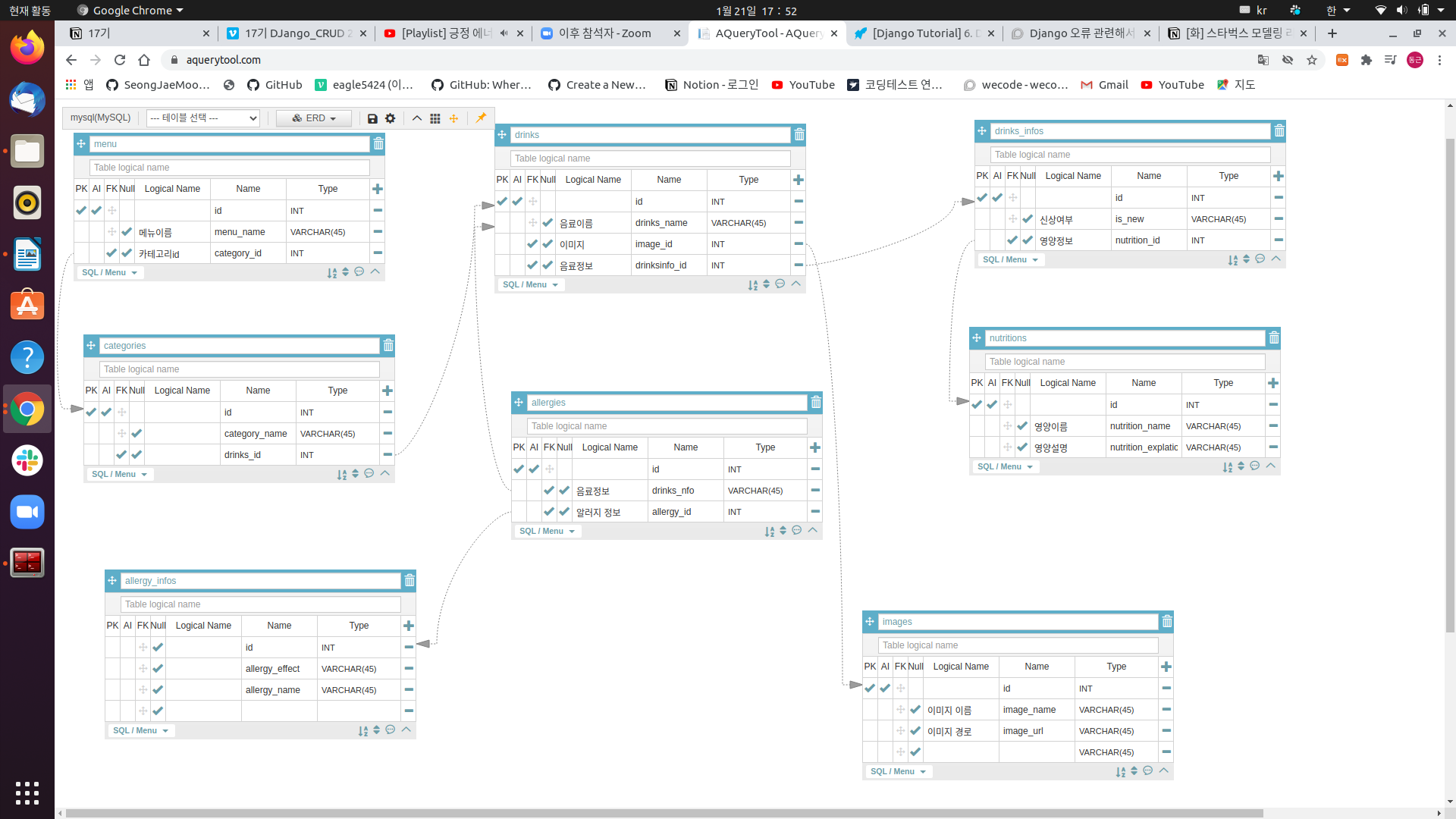
스스로 만들어 본 모델링이다.
데이터베이스 모델링에는 단 하나의 정답이 있는 것은 아닙니다. 현재 서비스에 가장 최적화된 구조를 찾아가는 과정입니다. Best Practice를 자주 찾아보고, 여러 서비스들의 서비스 구조를 파악해 보는 연습을 하는 것이 데이터 모델링 실력을 키우는 가장 좋은 방법입니다.
Best Practice
