- 트레이닝을 위한 이미지 데이터의 준비
- 이미지 분류를 위한 단순 모델 생성 및 컴파일
- 이미지 분류 모델 트레이닝 및 결과 관찰
Kaggle
이 데이터 세트는 데이터세트와 기타 딥러닝 리소스를 찾기에 아주 좋은 웹사이트인 Kaggle에서 제공됩니다. 노트북에서 본 데이터세트와 '커널' 등의 리소스를 제공하는 것 외에도, Kaggle은 다른 이들과 매우 정확한 모델을 트레이닝하는 경쟁을 할 수 있는 경진대회도 주관합니다.
데이터 로드
MNIST와 동일한 방식으로 Keras를 통해 제공되지 않으므로 맞춤형 데이터를 로드하는 방법을 알아보겠습니다.
CSV형식으로 되어있습니다. 이는 트레이닝 및 검증 데이터세트에서 보이는 것처럼 상단에 레이블이 있는 행과 열로 이루어진 그리도 입니다.
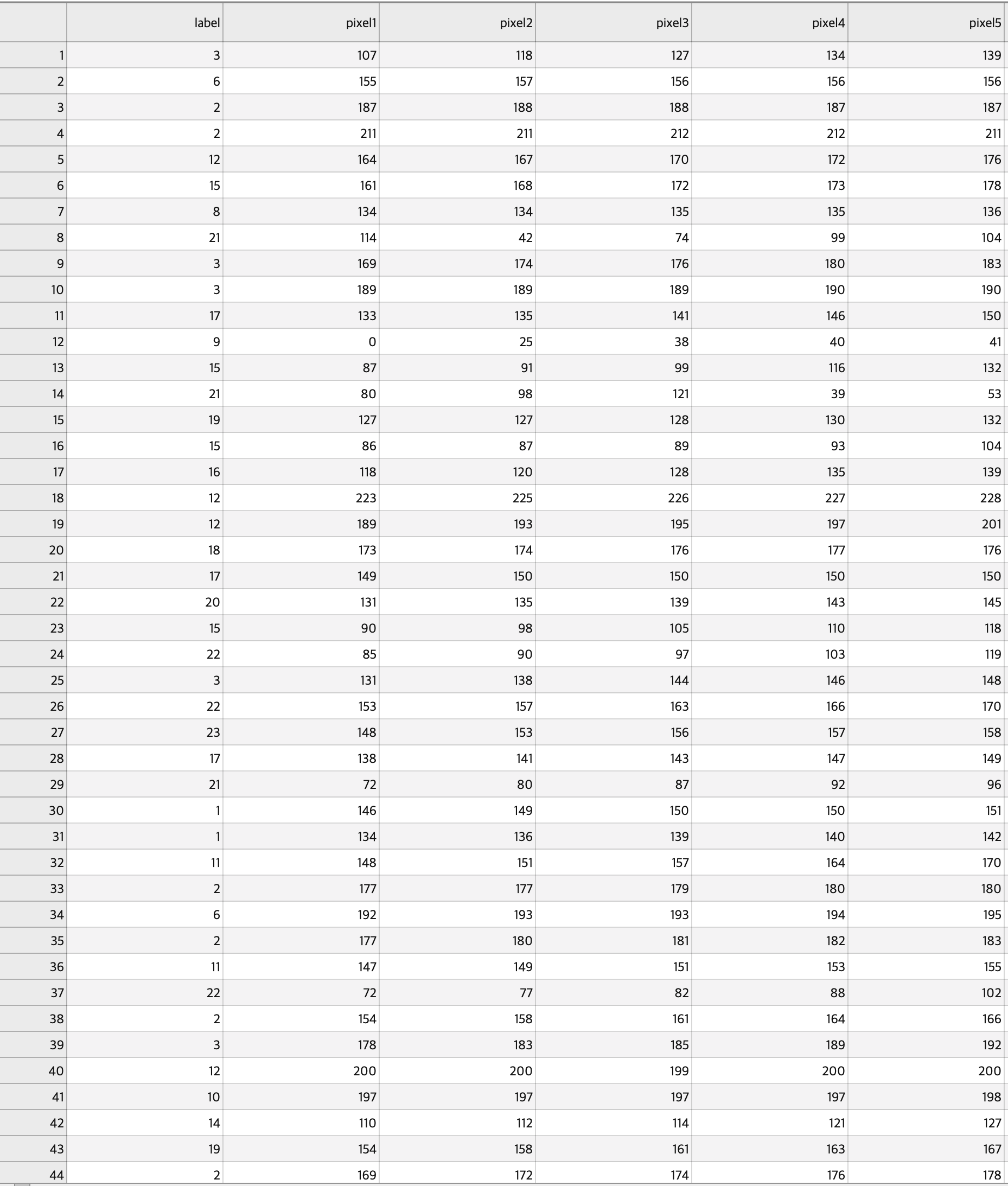
데이터를 로드하여 작업하기 위해 Pandas를 사용해서 CSV파일을 읽어 오겠습니다.
import pandas as pd
test_df = pd.read_csv(경로)
valid_df = pd.read_csv(경로)데이터 살펴보기
head메서드를 사용하면, Datafram의 처음 행 몇 개를 출력할 수 있습니다. 각 행은 label열, 그리고 MNIST 데이터세트처럼 이미지의 각 픽셀 값을 나타내는 784개의 값을 지닌 이미지 입니다.
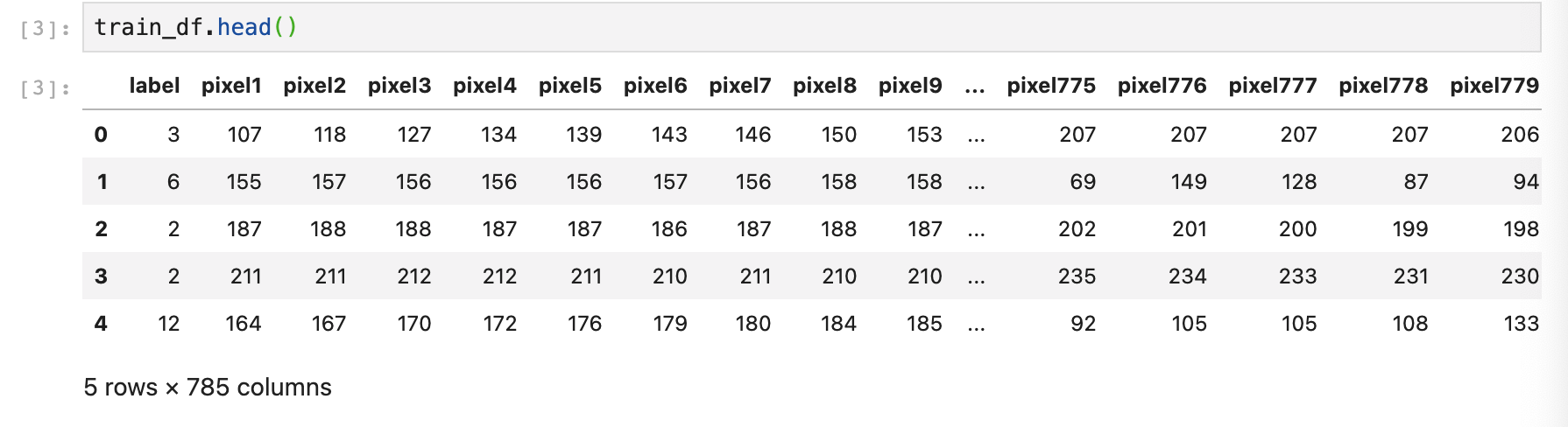
레이블 제외하면 784개
레이블 추출
MNIST와 마찬가지로, 트레이닝 및 검증 레이블을 y_train, x_train에 저장 하려고 합니다.
y_train = train_df['label']
y_valid = valid_df['label']
del train_df['label']
del valid_df['label']
x_train = train_df.values
x_valid = valid_df.values
이제 트레이닝을 위한 각각 784픽셀을 포함하는 27,455개의 이미지와, 레이블이 준비가 되었다.
이미지 데이터 정규화
딥러닝은 0 ~ 1 사이를 인식하는 것이 더 좋으므로 정규화 작업을 진행 해 준다.
x_train = x_train / 255
x_valid = x_valid / 255
레이블 분류
레이블의 범주 인코딩을 해줄려고 한다. kears.utilis.to_categorical 메서드를 사용하여 여기에 인코딩할 값과 값을 인코딩할 범주 수를 전달해 범주 인코딩을 수행 할 수 있다.
y_train = keras.utilis.to_categorical(y_train, num_classes)
y_valid = kerasutilios.to_categorical(y_valid, num_classes)연습모델 구축
연습모델에서는 순차모델을 구축
- 밀집 입력 레이어를 지님, 이 레이어는 512개의 뉴런을 포함하고, 'relu'활성화 함수를 사용, (784,)모양을 가진 입력 이미지를 예상해야 합니다.
- 512개의 뉴런을 포함하고
relu활성화 함수를 사용하는 두번째 밀집레이어를 지님 - 뉴런수가 클래스와 동일하고
softmax활성화 함수를 사용하는 밀집 출력 레이어를 지님
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Densemodel = Sequential()
model.add(Dense(units=512, activation='relu', input_shape=(784,)))
model.add(Dense(units=512, activation='relu'))
model.add(Dense(units=num_classes, activation='softmax'))모델 요약
model.summary()

model.compile(loss='categorical_crossentropy',), metrics=['accuracy']Categorical_crossentropy vs binary_crossentropy
결론 부터 말하면 outpuy layer가 sigmond이냐 softmax이냐 라고 볼 수 있다.
- 내가 가진 label값이 0 or 1이면서 sigmod cross entropy를 loss로 하고 싶으면 binary_crossentropy를 쓰면된다.
- 내가 가진 label이 [0,1] or [1,0]의 형태면서 softmax_cross_entropy를 loss로 하고자 할 때는 categorical_crossentropy를 쓰면 된다.
softmax vs sigmod
sigmod
- 모든 범위의 실수를 취하고 0에서 1사이의 출력 값을 반환합니다.
- 시그모이드 함수는 'S'형태의 포함될 커브를 생성합니다.(누적 분포 함수)
사용
- 로지스틱 회귀 모델에서 이진 분류에 사용되는 시그모이드 함수
- Action function 기능으로 사용
- 통계에서 시그모이드 함수 그래프는 누적 분포 함수로 사용 됩니다.
softmax
- 일반적으로 이 함수는 가능한 모든 대상 클래스에 대해 각 대상 클래스의 확률을 계산 합니다. Softmax를 사용하는 주된 이점은 출력 확률 범위 입니다. 범위는 0에서 1이며, 모든 확률의 합은 1과 같습니다.
사용
- 다중 분류 로지스틱 회귀모델에 사용
NO Softmax Function SigmodFunction 1 logistic regression에서 muli-classification문제에서 사용 logistic regression에서 binary-classification 문제에서 사용 2 확률의 총합 =1 학률의 총 합은 1이 아님 3 출력층에서 사용됨(확률 표현) Activation 함수로 사용 될 수 있음(실제로 사용하지 않음) 4 큰 출력 값은 그 class에 해당할 가능성이 높다는 것을 뜻하면 실제 확률을 나타냄 큰 출력 값은 그 class에 해당할 가능성이 높지만 실제 그 확률 값을 나타내는 겂은 아님 결론
- sigmod: binary-classification에서 사용
- softmax: multi-classification에서 사용
모델 컴파일
model.compile(loss='categorical_crossentropy', metrics=['accuracy'])metrics: 측정항목 함수는 모델이 컴파일이 될때 metrics매개변수를 통해 공급이 됩니다.(metrics공식문서)
outputlayer가 우선 softmax이기 때문에 손실률은 Categorical_crossentropy를 사용하고 metrics에서는 'accuracy'만을 보여준다.
모델 트레이닝
모델의 fit을 메서드를 사용하여 위에서 생성한 트레이닝 및 검증 이미지와 레이블로 20에포크 동안 트레이닝을 진행했습니다.
model.fit(x_train, y_train, epochs=20, verbose=1, validation_data=(x_valid, y_valid))
컴파일에서 명시해준 손실률(loss)와 정확도(accuacy)가 train 과 valid 파일 각각 나와있다.
출처: 네이버 블로그
