MNIST 데이터세트로 이미지 분류
-
처음 접한 이미지를 정확한 클래스로 올바르게 분류하도록 프로그램에 요청하는 이미지 분류는 기존 프로그래밍 기술로는 해결하기가 거의 불가능 합니다.
-
특히 처음 접하는 이미지를 고려할 때 어떻게 해서 프로그래머가 매우 다양한 이미지를 올바르게 분류하기 위한 규칙과 조건을 정의 할 수 있을까요?
-
딥러닝은 시행착오를 통한 패턴 인식에 뛰어난 면모를 보입니다. 충분한 데이터로 딥 뉴럴 네트워크를 트레이닝 하고 트레이닝을 통해 성능에 대한 피드백을 네트워크에 제공함으로써 네트워크는 엄청난 수의 반복이 요구되기는 하지만 그래도 올바른 방식으로 작동할 수 있는 기준이 되는 나름의 조건을 식별할 수 있습니다.
트레이닝 및 검증 데이터 및 레이블
딥러닝을 위해 이미지로 작업할 때에는 이미지 자체뿐 아니라 이러한 이미지의 올바른 레이블이 모두 필요합니다. 아울러, 모델 트레이닝을 위한 X,Y값이 둘 다 필요하며, 트레이닝 된 이후의 모델 성능 검증을 위한 별도의 X,Y가 필요합니다.
모델트레이닝을 위한 X,Y -> x_train, y_train
성능 검증을 위한 별도의 X,Y -> x_valid, y_valid
트레이닝과 성능 검증 의 차이
전문가의 데이터 검증 세트는 무엇입니까?
Generally, the term “validation set” is used interchangeably with the term “test set” and refers to a sample of the dataset held back from training the model.
-> 일반적으로, validation set는 test set라는 용어와 상호 호환되고, 훈련 모델에서 보류된 데이터 집합의 표본을 의미합니다.
To reiterate the findings from researching the experts above, this section provides unambiguous definitions of the three terms.
-> 상기 전문가 연구의 결과를 반복하기 위해 이 절에서는 세 가지 용어에 대한 명확한 정의를 제공합니다.
-
Training Dataset: The sample of data used to fit the model.
(모델을 맞추는데 사용되는 데이터의 샘플 입니다.) -
Validation Dataset: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters. The evaluation becomes more biased as skill on the validation dataset is incorporated into the model configuration.
(모델 하이퍼파리미터를 조정하는 동안 훈련 데이터 세트에 대한 모델 적합성에 대한 편견없는 평가를 제공하는데 사용되는 데이터 샘플 입니다. 검증 데이터 세트에 대한 기술이 모델 구성에 통합됨에 따라 평가가 더 편향됩니다.) -
Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset.
(훈련 데이터 세트에 대한 최종 모델 적합에 대한 편견 없는 평가를 제공하는 데 사용되는 데이터 샘플 입니다.)
MINIST(Modified National Institute of Standards and Technology database)
손으로 쓴 숫자들로 이루어진 대형 데이터베이스이며, 다양한 화상 처리 시스템을 트레이닝 하기 위해 일반적으로 사용된다.
데이터를 메모리에 로드(keras 사용)
다양한 프레임 워크가 있어 어떤 것을 사용할지 헷갈릴 경우가 클것이다. 고민할 필요없이, 다양한 버전 업그레이드가 일어났기 때문에, 오늘날에는 아무거나 사용해도 상관없다.
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_valid, y_valid) = mnist.load_dataMNIST 데이터 살펴보기
MNIST 데이터 세트에는 수기 문자로 이루어진 7만개의 회색조 이미지가 포함되어 있다.
- Keras가 트레이닝을 위해 6만개의 이미지, 검증(트레이닝 후)를 위해 만개의 이미지를 분할했으며 각 이미지 자체가 28 * 28 차원의 2D 어레이임을 확인 할 수 있습니다.
훈련시킬 데이터 확인 하기
x_train.shape-> (6000, 28, 28)
검증 데이터 확인하기
x_valid.shape-> (10000, 28, 28)
이렇게 표시된 28x28 이미지가 0 ~ 255의 서명되지 않은 8비트 정수 값 모음으로 표현되는 것을 확인할 수 있습니다. 0은 검은색 1은 흰색, 나머지 색은 그 안의 값들에 해당
x_train.dtype
-> dtype('uint8') 8비트의 부호 없는 정수형 배열
x_train.min() -> 훈련시킬 데이터의 최솟값
x_train.max() -> 훈련시킬 데이터의 최댓값
x_train[0] 이렇게 하면 제대로 보이지 않는다.
for x in x_train[0]:
for i in x:
print('{:3} '.format(i), end='')
print()
사진이 배열로 변경 된 모습을 볼 수 있다.
Matplotlib을 사용하면 데이터세트에서 이러한 회색조 이미지 중 하나를 렌더링 할 수 있습니다.
import matplotlib.pyplot as plt
image = x_train[0]
plt.imshow(image, cmap='gray')그리고 이거에 대한 답은 y_train 데이터에 있습니다.
트레이닝을 위한 데이터 준비
딥러닝에서는 대부분의 경우 트레이닝을 위한 적합한 상태로 데이터를 변환해야합니다.
- 이미지 데이터를 평탄화 하여 모델에 입력되는 이미지를 간소화 해야합니다.
- 이미지 데이터를 정규화하여 이미지 입력 갓이 모델에서 더 쉽게 작동되도록 해야합니다.
- 레이블을 분류하여 레이블 값이 모델에서 더 쉽게 작동되도록 해야 합니다.
이미지 데이터 평탄화
딥러닝 모델에서 2차원 이미지를 사용할 수도 있긴 하지만 여기서는 간단하게 각 이미지를 784개의 연속 픽셀로 이루어진 단일 어레이로 재구성을 하겠습니다.
(원래는 28 28 로 있는데 784로 이미지 평탄화 작업)
x_train = x_train.reshape(60000, 784)
x_Valid = x_valid.reshape(10000, 784)이미지가 재구성되어 784개의 픽셀 값을 포함하는 1D 어레이의 모음이 되었음을 확인할 수 있습니다.
그래서 다시 데이터를 확인 해보면
x_train.shape-> (60000, 784)
이미지 데이터의 정규화
딥러닝 모델은 0에서 1사이의 부동 소수점 수를 처리하는데 더 뛰어납니다. 그래서 정수 값을 0에서 1 사이의 부동 소수점 값으로 변환 하는 것을 정규화라고 하며, 여기서는 데이터를 정규화 하기 위해 모든 픽셀값을 255로 나누는 단순한 접근 방법을 사용하겠습니다.
x_train = x_train / 255
x_valid = x_valid / 255그래서
x_train.dtype -> dtype('float64')로 바뀐 것을 확인 할 수 있다.
x_train.min() -> 0.0
x_train.max() -> 1.0
범주 인코딩
7-2의 답이 머냐고 물어봤을때 4라고 답하는 것은 9라고 답하는 것보다 훨씬 정답에 근접합니다. 하지만 이러한 이미지 분류의 경우는 이러한 추론은 배우지 않는 것이 좋다.
keras는 값을 범주 인코딩하는 유틸리티를 제공하며, 여기서는 이를 사용하여 트레이닝 및 검증 레이블 모두에 대한 범주 인코딩을 수행합니다.
| color | is Red | is Blue | is Green |
|---|---|---|---|
| Red | True | False | False |
| Green | False | False | True |
| blue | False | True | False |
| Green | False | False | True |
| color | is Red | is Blue | is Green |
|---|---|---|---|
| Red | 1 | 0 | 0 |
| Green | 0 | 0 | 1 |
| blue | 0 | 1 | 0 |
| Green | 0 | 0 | 1 |
이러한 값을 트레이닝에 사용한다면
values = ['red, green, blue, green']
하지만 이를 이해하기 어렵기 때문에
values = [
[1,0,0],
[0,0,1],
[0,1,0],
[0,0,1]
]
이렇게 변경된다.
레이블 범주 인코딩
import tensorflow.kerase as keras
num_categories =10
y_train = keras.utils.to_categorical(y_train, num_cateegories)
y_valid = keras.utils.to_categorical(y_valid, num_categories)모델 생성
데이터로 트레이닝할 모델을 생성해야 합니다. 이 첫 번째 기본 모델은 여러 개의 레이어로 이루어지며 3가지 주요 부분으로 구성됩니다.
-
어느 정도 예상되는 형식으로 데이터를 수신하는 입력 레이어
-
각각 다수의 뉴런으로 구성된 여러 개의 숨겨진 레이어 각 뉴런은 가중치로 네트워크의 추측에 영향을 미칠 수 있으며, 가중치는 네트워크가 수많은 반복을 통해 성능에 대한 피드백을 수신하고 학습하면서 업데이트 하게 되는 값
하나의 인공 뉴런(node, 노드)에서는 다수의 입력 신호를 받아서 하나의 신호를 출력한다. 이는 실제 뉴런에서 전기신호를 내보내 정보를 전달하는 것과 비슷합니다. 이때 뉴런의 돌기가 신호를 전달하는 역할을 하듯이 인공 뉴런에서는 가중치(weight)가 그 역할을 한다.
-
주어진 이미지에 대한 네트워크의 추측을 보여주는 출력 레이어
모델 인스턴스화
인스턴스: 객체지향프로그래밍(OOP)에서 인스턴스는 해당 클래스의 구조로 컴퓨터 저장공간에서 할당된 실체를 의미한다. 여기서 클래스는 속성과 행위로 구성된 일종의 설계도이다. OOP에서 객체는 클래스와 인스턴스를 포함한 개념이다.
Keras의 순차 모델 클래스를 사용하여 데이터가 연속으로 통과할 일련의 레이어를 보유한 모델의 인스턴스를 인스턴스화 하겠습니다.
from tensorflow.keras.models import Sequential
model = Sequential()입력 레이서 생성
이 레이어는 밀집 연결되어 있습니다. 따라서 포함된 각 뉴런과 가중치가 다음 레이어의 모든 뉴런에 영향을 줍니다. Keras의 Dense레이어 클래스를 사용해야 한다.
from tensorflow.keras.layers import Dense- units: 레이어 내 뉴런 수를 지정합니다. 올바른 뉴런 수를 선택하는 것은 데이터 세트의 통계적 복잡성을 없애주는 일이므로, 데이터 사이언스 작업의 핵심이라고 할 수 있다.
- activation(활성화 함수): 네트워크가 일부 엄격한 선형 함수를 토대로 추측해야 하는 경우에 비해 데이터에 대한 좀 더 정교한 추측을 하는 방법을 배울 수 있게 도와 줍니다.
- input_shape: 수신되는 데이터의 모양을 지정하며, 여기서는 784개 값으로 이루어진 1D 어레이 입니다.
model.add(Dense(units=512, activation='relu', input_shape=(784,)))숨겨진 레이어 생성
밀집 연결된 추가 레이어를 더해보겠습니다. 이러한 레이어가 추측에 기여하는 더 많은 매개변수 즉, 정확한 학습을 위한 좀 더 예리한 기회를 네트워크에 제공한다는 사실
model.add(Dense(units=512, activation='relu'))출력 레이어 생성
각 레이어 값이 0에서 1 사이의 확률이 되도록 하고 레이어의 모든 출력이 1에 추가되도록 하는 활성 함수인 softmax 를 사용
이 경우에는 네트워크가 1에서 10까지의 가능한 범주에 속하는 단일 이미지에 대해 추측을 수행하므로 출력은 10개가 됩니다.
softmax: 다중 분류에 주로 사용이 되는 활성화 함수
- 세 개 이상으로 분류하는 다중 클래스 분류에서 사용되는 활성화 함수
- 분류될 클래스가 n개라 할 때, n차원의 벡터를 입력받아, 각 클래스에 속할 확률을 추청한다.
- 확률의 총합이 1이므로, 어떤 분류에 속할 확률이 가장 높을지를 쉽게 인지할 수 있다.
model.add(Dense(units=10, activation='softmax'))모델 컴파일
여기서는 트레이닝 중 모델에서 성능을 파악하는데 사용되는 손실함수를 지정합니다.
손실함수
통계학, 결정 이론 및 경제학 분야에서 손실 함수 또는 비용 함수는 그 사건과 관련된 경제적 손실을 표현 하는 실수로 사상하는 함수이다.
model.compile(loss='categorical_crossentropy', metrics=['accuracy'])모델 트레이닝
트레이닝=흔히 모델을 데이터에 맞춘다고고 합니다. 모델을 데이터에 맞춘다는 말은 주어지고 있는 데이터를 좀 더 정확하게 이해하기 위해 모델이 점차적으로 모양을 바꾼다는 점을 부각 한다.
Keras로 모델을 맞추는(트레이닝) 경우에는 모델의 fit 메서드를 사용합니다.
- 트레이닝 데이터 -- x_train
- 트레이닝 데이터의 레이블 -- y_train
- 전체 트레이닝 데이터세트에 대해 트레이닝 해야 하는횟수(Epoch-에포크)- epoch
- 검증 또는 테스트 데이터 및 해당 테이블 - validation_data = (x_valid, v_valid)
history = model.fit(x_train, y_train, epoch=5, verbose=1, validation_data = (x_valid, y_valid))x_train: 트레이닝 데이터
y_train: 트레이닝 데이터의 레이블
epoch: 전체 트레이닝 데이터 세트에 대해 트레이닝 해야하는 횟수
verbose: 트레이닝 과정을 어떻게 보여줄 것인지
0 = silent,
1 = progress bar,
2 = one line per epoch.
validtaion_data: 검증 또는 테스트 데이터 및 해당 테이블
결과
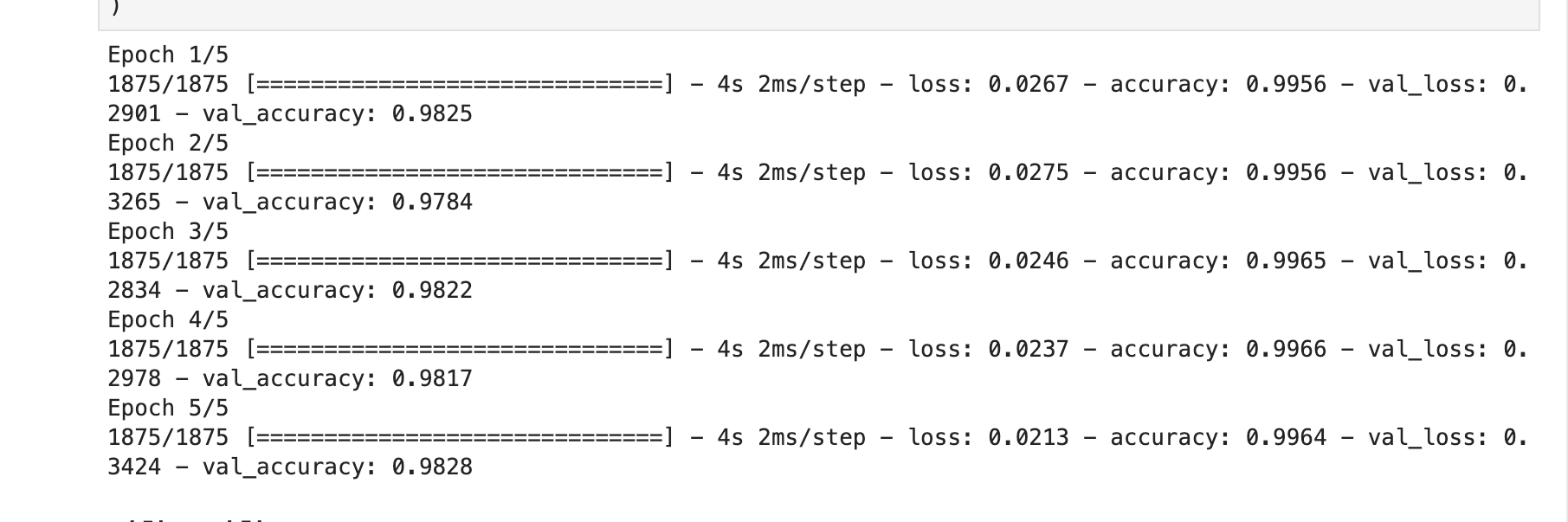
5회의 epoch 각각에 대해
- 손실률(loss),
- accuracy(모든 트레이닝 데이터에 대한 에포크 동안의 모델 성능이 어땠는지를 명시힙니다.),
- val_accuracy(모델을 트레이닝하는 데 전혀 사용되지 않는 검증 데이터에 대한 모델 성능이 어땠지를 나타냅니다.)
