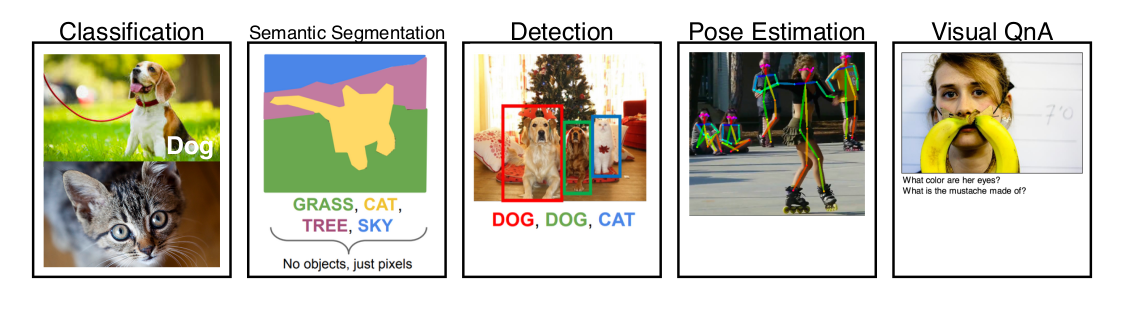
딥러닝이란?
인공지능의 정의에 대해 생각해보겠습니다
사람마다 다르겠지만
가장 기본적인 정의는 사람의 지능을 모방하는 것입니다
이처럼 인간의 지능을 모방하는 인공지능 안에
머신러닝이라는 불리는 분야가 존재합니다
이 분야는 일반적으로 data-driven approach
즉, 무엇을 학습하고자 할 때 데이터를 통해 학습을 하는 것을 의미합니다
이 안에 딥러닝이라는게 들어가는 것이 통상적인 분류입니다
인간의 지능을 모방하면서
데이터를 통해서 무언가를 학습하는 머신러닝 안에
우리가 사용하는 모델이 neural nextwork를 사용하는
세부적인 분야가 딥러닝에 해당하게 됩니다
딥러닝의 Key Components
일반적으로 4가지를 말합니다
datamodellossalgorithm
이 4가지를 강조하는 이유는
새로운 논문 or 연구를 봤을 때
이 4가지 항목에 비추어서 논문 or 연구를 바라볼 때
기존에 비해 어떤 장점이 있고 의의가 있는지를 이해하기 쉽기 때문입니다
Data
데이터는 우리가 풀고자 하는 문제에 dependent
Model
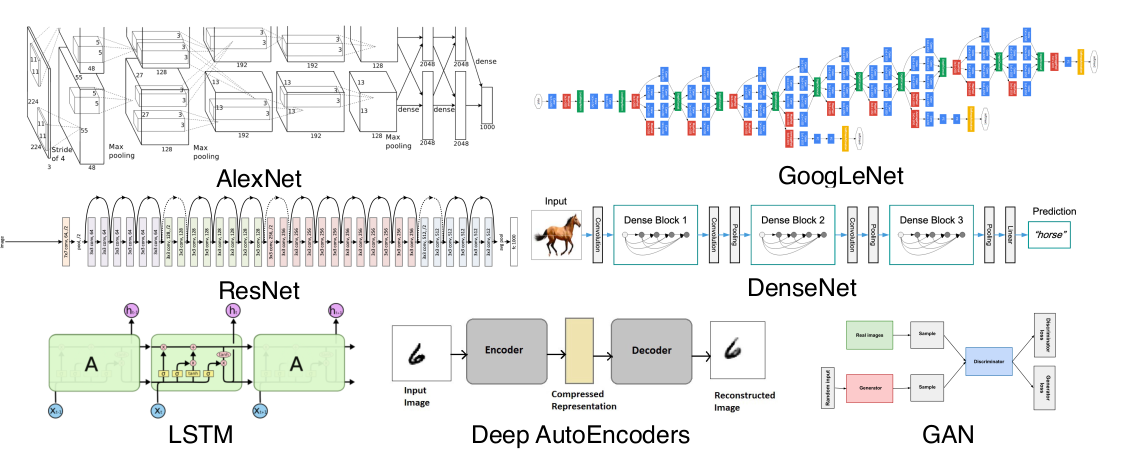
같은 데이터라도 모델의 성질에 따라 결과가 달라집니다
Loss
Loss function이란 것은
모델과 데이터가 정해졌을 때 모델을 어떻게 학습할지?
신경망에서 가중치를 어떤 식으로 업데이트 해줄 것인지
그때 기준이 되는 loss function을 정하게 됩니다
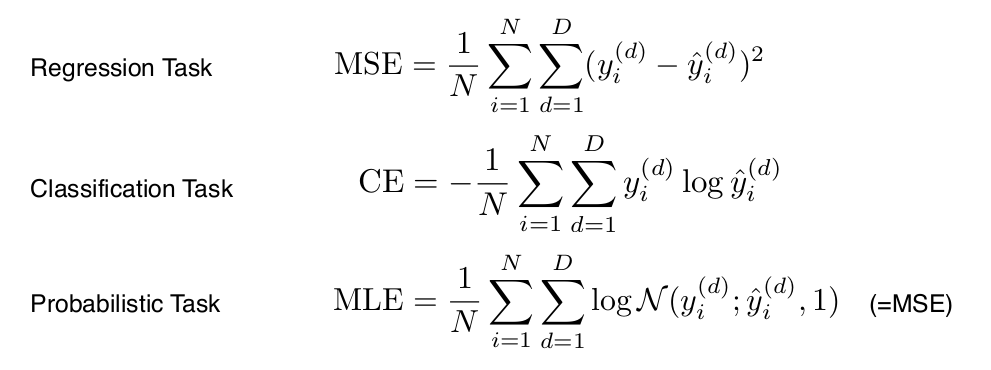
여기서 중요한 점은
loss function이라는 것은
우리가 이루고자 하는 것의 근사치(proxy)에 불과하다는 것
loss function의 값이 줄어든다고 해서
항상 우리가 원하는 값을 불러온다고 보장할 수 없습니다
Algorithm
최적화 방법은 data, model, loss function이 모두 정해져있을 때
network를 어떻게 줄일지에 대한 이야기입니다
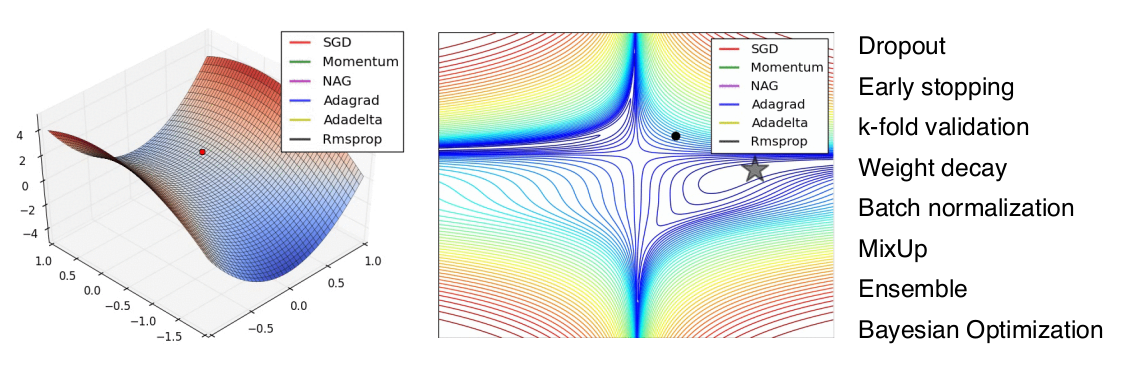
Historical Review
딥러닝이라고 불리는 것이 8, 90년도부터 발전해왔지만
다른 머신러닝 방법들에 비해서 부각을 나타내기 시작한 2012, 13년도를 지나
현재까지 이르도록 어떤 방법론들이 큰 임팩트가 있었는지 살펴보겠습니다

위의 논문을 참고한 내용들입니다 (Denny Britz 블로그)
2012 - AlexNet
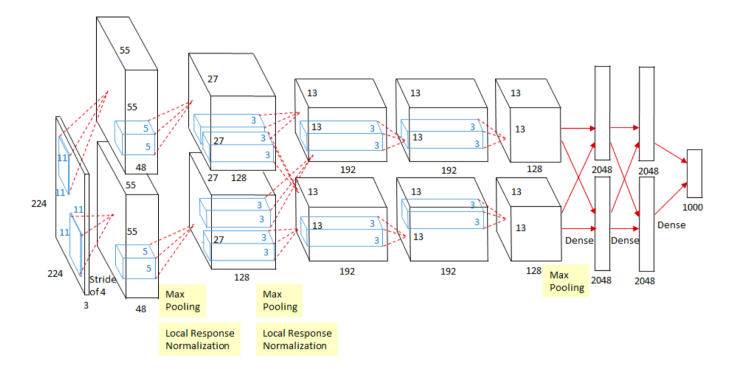
- CNN에 해당
- 224 x 224 이미지를 분류하는 것이 목적
- ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 2012년 1등을 차지
ILSVRC에서 AlexNet 이전에는 딥러닝을 사용하지 않고
SVM과 같은 고전적인 머신러닝 방법들을 조합하여 이용했습니다
2013 - DQN

알파고로 유명한 딥마인드에서
흔히 아는 벽돌깨기라는 게임에 강화학습을 적용한 케이스입니다
2014 - Encoder / Decoder
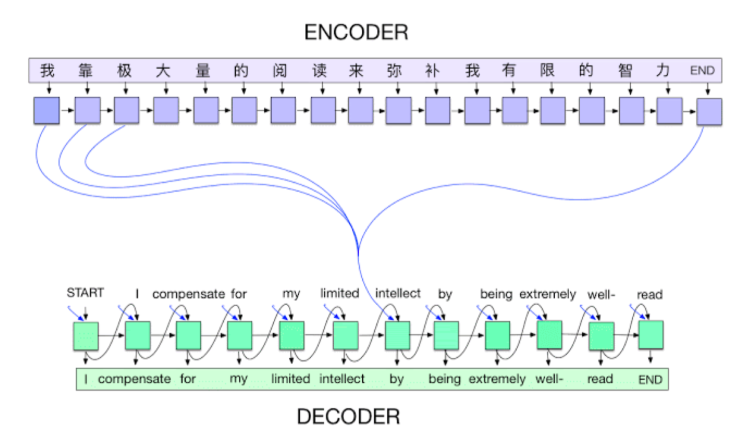
NMT(Neural Machine Translation) 문제를 풀기 위한 아키텍처입니다
구글 번역에도 사용되는 방법론인데
다른 언어로 된 문장(=단어의 연속)이 주어졌을 때
우리가 원하는 다른 언어의 단어의 연속으로 뱉어주는 것이 목적입니다
2014 - Adam Optimizer
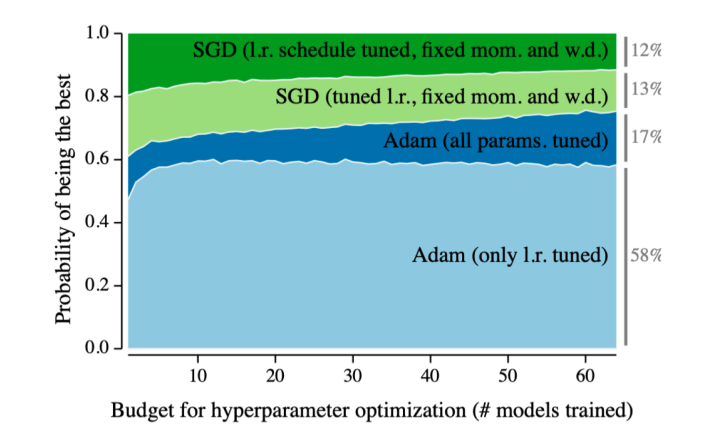
우리가 모델을 학습시키려고 할 때
optimizer는 여러가지가 있는데
Adam을 그냥 사용하는 경우가 많습니다
결과가 잘 나오기 때문에 👍
딥러닝 모델에 대해서 다양한 하이퍼파라미터 search를 하게 되는데
computing resource가 필요합니다
근데 돈이 많이 들겠죠? (GPU 가격...)
여기서 Adam이라는 방법론은 왠만하면 잘된다 라는 의미를 가집니다
2015 - Generative Adversarial Network (GAN)

생성형 모델에 대한 이야기인데
간단하게 말하자면 generator와 discriminator라는 2가지 만들어서 학습을 시키는
generator는 생성하고
discriminator는 판별을 하면서
이 두 네트워크를 적대적으로 학습시키며
실제와 가까운 데이터를 생성한다는 목적을 달성합니다
간단하다고 하는데 간단하지 않은...
2015 - Residual Networks (ResNet)
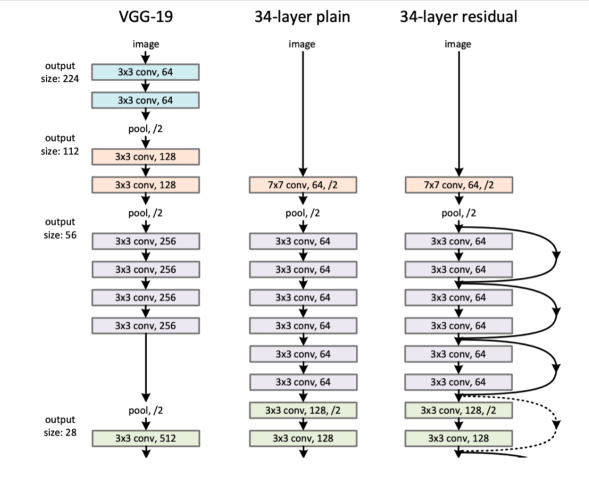
딥러닝이 딥러닝이라고 불리는 이유는
네트워크를 깊게 쌓아서 만들기 때문에 라는 이야기가 있습니다
물론 깊게 쌓지 않는 경우도 있기 때문에 정확하진 않습니다
동시에
네트워크를 너무 깊게 쌓으면 학습이 잘 안된다는 이야기가 알려져있었습니다
훈련은 되지만테스트를 했을 때 성능이 별로라는 의미입니다
그래서 어느정도 레이어를 쌓으면 그 이후로는 늘리지 못했습니다
하지만 ResNet이 나온 이후에는 트렌드가 바뀌었습니다
여전히 네트워크를 1000개 쌓으면 잘 안되지만
20개를 쌓고 그 이후에 성능이 줄어드는 것을
100개를 쌓아도 테스트 데이터에서 성능이 좋게 나올 수 있게 만들어주었습니다
2017 - Transformer

그당시에 Attention 또는 Transformer라는 구조가
모든 것을 대체할 거라고 예상하진 못했습니다
그만큼 기존의 방법론에 비해서 어떤 장점이 있고
왜 좋은 성능을 낼 수 있는지 알아보는게 중요할 것 같네요
2018 - BERT (fine-tuned NLP models)
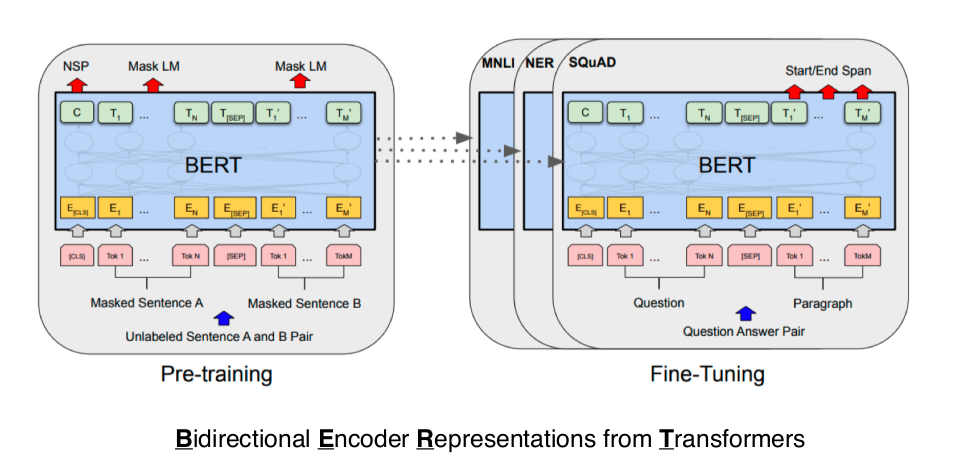
내가 풀고자 하는 문제가 예를 들면
좋은 뉴스 기사를 작성하는 네트워크를 만들고 싶다라면
그런 특정 목적을 위한 데이터는 부족합니다
그래서 일반적이고 굉장히 다양한 단어, 문장으로 pre-training을 한 후
내가 진짜 풀고자 하는 문제에 대한 소수의 데이터에 fine-tuning을 하는 방법론입니다
2019 - BIG Language Models

fine-tuned NLP model의 끝판왕같은 느낌으로 다 아시는 모델입니다
1750억개의 파라미터로 되어 있어서 아무나 학습시킬 수 없습니다
2020 - Self Supervised Learning
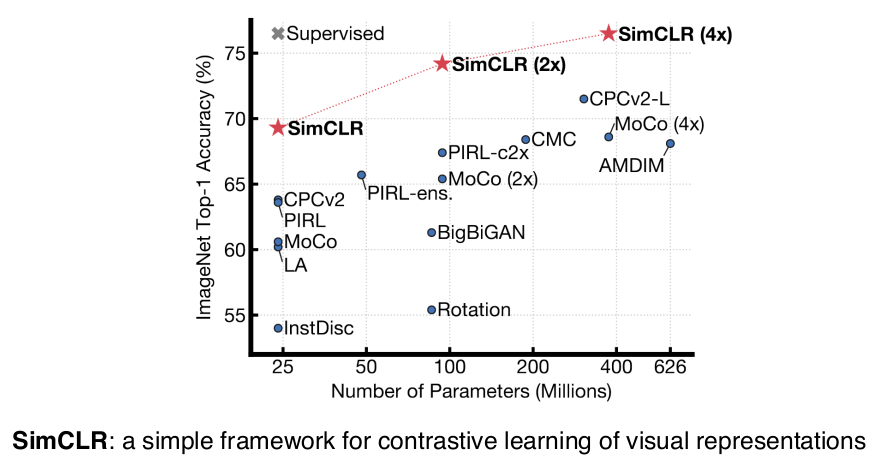
이미지 분류와 같은 분류 문제를 풀고 싶은데
한정된 학습 데이터로
모델, loss function 등에 여러가지 변형을 주면서 좋은 결과를 내는게 일반적이라면
이 방법론은
학습 데이터 외 라벨을 모르는 unsupervised data를 사용하겠다는 것입니다
이외에 dataset을 추가로 만들어내
학습 데이터를 뻥튀기(?)시켜 더 좋은 모델을 학습시키겠다는 트렌드도 존재합니다
