Spark 기본 특징
우선, 스파크는 빠르다! 데이터를 쪼개어 여러 노드의 메모리에서 동시처리하자는 개념에서 출발하였다. 주요 특징으로는,
1. Lazy Evaluation
- 태스크를 정의할땐 연산을 하지 않다가 결과가 필요할때 연산하는 방식
- 기다리면서 연산 최적화가 가능하다.
2. RDD (resilient distributed dataset)
RDD는 Spark의 근본이다!
- 여러 분산 노드에 걸쳐서 저장이 되고
- 변경이 불가능하며,
- 여러 개의 파티션으로 분할 관리가 된다.
3. 병렬처리와 분산처리
park는 분산된 환경에서 데이터 병렬 모델을 구현해 추상화 시켜줌. 따라서 노드 간 통신에 신경을 써야 하는 부분이 줄어들며 분산된 환경에서도 일반적인 병렬처리를 하듯 코드를 짜는게 가능함
- Data-Parallel
RDD.map(<task>) - Distribuited Data-Parallel?
1. 데이터를 여러 개로 쪼개서 여러 노드로 보낸다.
2. 여러 노드에서 각자 독립적으로 task 적용
3. 각자 만든 결과 값을 합치는 과정분산처리와 Latency
- 부분 실패 - 노드 몇 개가 프로그램과 상관 없는 이유로 인해 실패하는 경우
- 속도 - 많은 네트워크 통신을 필요로 하는 작업은 속도가 저하된다는 점
# 뭐가 더 성능이 좋을까? RDD.map(A).filter(B).reduceByKey(C).take(100) RDD.map(A).reduceByKey(C).filter(B).take(100)정답 : 첫번째!
이유 :reduceByKey여러 노드에서 데이터를 불러와서 통신이 필요한 함수.filter를 통해 사전에 양을 줄여주면 통신이 줄어들어 속도 최적화가 이루어짐
Hadoop?
- HDFS 파일시스템
- Map Reduce 연산 엔진
- Yarn 리소스 관리
Pandas VS Spark
확장성을 위해 설계된 pyspark 를 활용할 수 있다! Spark의 경우 기본적으로 분산처리를 채택하기 때문에 스몰 데이터의 경우 pandas가 더 빠를 수 있음
| Pandas | Pyspark |
|---|---|
| 1개의 노드 | 여러 개의 노드 |
| Eager Execution | Lazy Execution |
| 하드웨어 제한 | 수평 확장 가능 |
| Mutable Data | Immutable Data |
Spark 컴포넌트
스파크의 경우 기본적으로 Core가 존재하고 그 하위에 (1) Spark SQL (2) Spark Streaming (3) MLlib (4) GraphX 가 존재함
| 컴포넌트 | 내용 | 링크 |
|---|---|---|
| Spark Core | - SparkContext에서 작동함 - RDD를 제공하며 Spark의 기본임 | https://velog.io/@eun95828/Spark-RDD |
| Spark SQL | - SparkSession에서 작동함 - Dataframe을 제공하며 RDD에 스키마가 적용된 것 | https://velog.io/@eun95828/Spark-Dataframe |
| Spark Streaming | - SQL 엔진 위에서 만들어진 분산 스트림 처리 프로세싱 | https://velog.io/@eun95828/Apache-Spark-Streaming |
| Spark MLlib | - 머신러닝 파이프라인 개발을 쉽고 확장성 있게 적용하기 위해 만들어진 Spark 컴포넌트 | https://velog.io/@eun95828/Spark-MLlib |
Spark Cluster
Spark의 경우 Master Worker Topology로 구성되어 있음
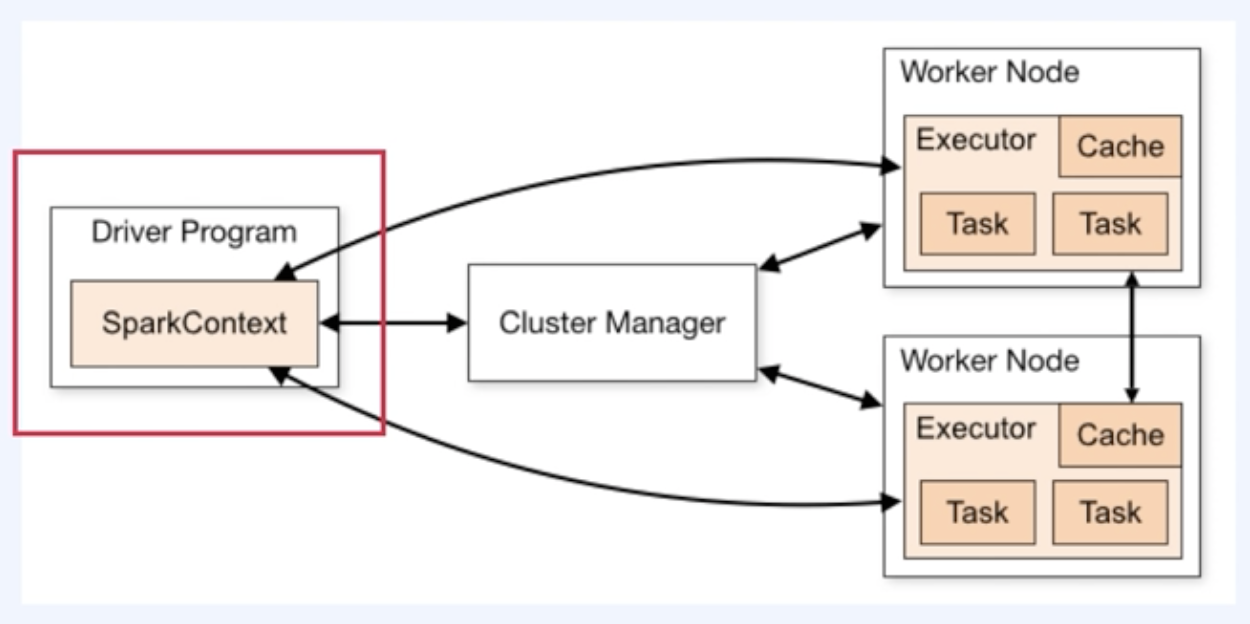
| Driver Program | Cluster Manager | Worker Node |
|---|---|---|
- 메인 프로세스를 실행하며 SparkContext를 생성함 (Spark application을 생성) -실제로 태스크가 수행되진 않지만 사용자와 상호작용하기 위해 존재함 - | -Cluster Manager가 Driver Program과 Worker 노드 사이를 연결해주는 역할을 수행한다. - 또한 실행에 필요한 자원을 할당해줌 | -내부의 executor가 실제 연산을 수행하고 데이터를 저장함 |
따라서 스파크는 아래와 같은 점을 항상 유념하고 있어야 한다.
- 항상 데이터가 여러 곳에 분산되어 있다는 것
- 같은 연산이어도 여러 노드에 걸쳐 실행된다는 점.
예시 1
RDD.foreach(lambda x: print(x))
- 위 코드는 driver program에서 아무것도 출력이 되지 않음
foreach()가 driver program이 아닌 executor에서 바로 실행되는 함수이므로print()의 행위가 executor에서 일어나 driver program으로 전달을 해주지 못하기 때문
예시 2
foods = sc.parallelize(["복숭아", "수박", ...])
three = foods.take(3)- three라는 결과값은 driver program에 존재하게 됨
- executor에게
take()를 수행하라고 전달하게 되므로 driver program에서 출력값을 확인할 수 있음
출처
실시간 빅데이터 처리를 위한 Spark & Flink (패캠)

1차전직 DA 2차전직 DE