1. 다양한 형태의 인구구조 차트 그리기
오늘도 지난 수업에 이어 인구구조를 차트로 그리기를 배웠다😁
지난 시간에는 연도별 인구구조를 plot 차트로 비교했다면, 이번 시간에는 연령별 성비를 barh차트를 활용한 항아리 차트와 pie차트로 구현했다. 또한 남녀 인구 수를 비교할 때, 어떤 성별이 얼마나 더 많은지 직관적으로 표현하는 bar 차트를 그렸다.
<항아리 차트 그리기>
남성과 여성이 구분된 데이터를 활용을 위해 남성과 여성의 자료를 각각 담을 리스트를 먼저 선언하고 2개의 방식으로 리스트에 데이터를 담았다.
방식1) 남성과 여성 동일하게 0세에서 100세까지 101개의 값을 가진다는 것을 활용해 1개의 for문을 활용하여 데이터 요소를 추가하는 방법
방식2) 2개의 for문을 활용하여 범위를 각각 설정해서 데이터 요소를 추출하는 방법
항아리 차트는 barh차트를 활용하는데 남성과 여성의 그래프가 겹쳐지는 것을 방지하기 위해 한 성별의 데이터를 음수로 바꿔 x축의 음수 부분에 데이터를 그린다.
종전까지는 읍면동을 기준으로 그래프를 그렸는데 보다 넓은 단위로 성비를 보기 위해서는 break텍스트 함수를 사용한다. 데이터 원시자료를 보면, 읍면동 세부자료보다 그 읍면동을 포함하는 넓은 지여긔 소계자료가 위쪽에 작성되어 있기 때문에 for문의 반복을 멈추면 넓은 지역의 자료를 추출할 수 있다.
<파이 차트 그리기>
파이차트가 plot이나 bar차트와 다른 점은 데이터의 합계 자료가 필요하다는 것이다. 합계자료는 두가지 방식으로 구할 수 있었다.
방식1) 한 행에 존재하는 각 성별의 연령별 인구수 값을 모두 더하는 것이다. 교수님께서는 자신의 값을 계속 더하는 것이라고 말씀해주셨다.
방식2) 원시데이터가 가지고 있는 값을 추출하여 활용한다.
cf. 데이터가 어떻게 구성되어 있는지 잘 파악한다면 방식1)처럼 복잡한 코드를 활용하지 않아도 문제를 해결할 수 있다.
파이차트를 그릴 때, startangle값을 90으로 지정해주면 시계 12시 방향에서부터 차트를 그린다. 또한, explode 값을 지정해주면 강조하고자 하는 값을 파이 중심에서 간격을 두어 표현할 수 있다. 강조하고자 하는 값은 범례의 순서를 참고하여 0.1로 값을 넣어준다.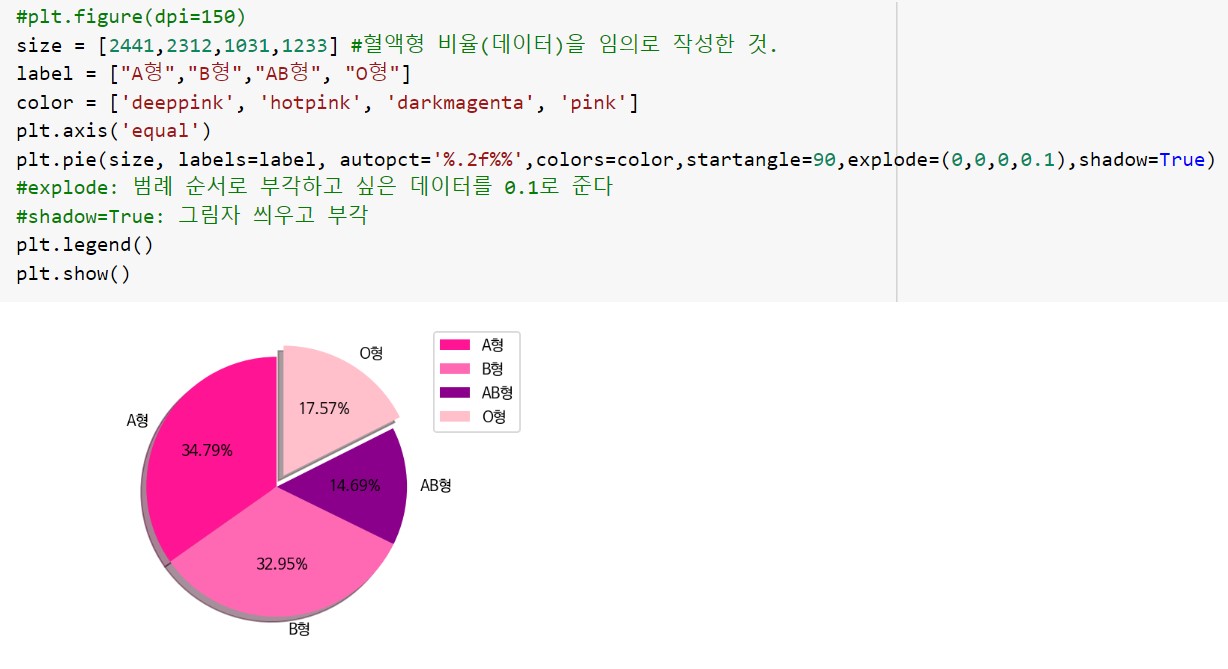
<차이값을 bar차트로 그리기>
항아리 차트와 파이 차트는 두 성별이 얼마나 차이가 나는지 직관적으로 알아보기 어려웠다. 그 차이를 가시적으로 명확히 보여주기 위해서 연령별 차이를 bar차트로 그린다.

2.유사한 인구구조를 가진 지역 차트 그리기 w.Pandas Library
오늘 처음으로 판다스 라이브러리를 활용해 코드를 작성하고 차트를 그렸다. 판다스 라이브러리 모듈을 활용하기 전에는 파일을 읽는 절차가 1) csv 모듈을 불러오고 2) open함수를 활용해 파일을 연 후 3) 파일을 reader함수에 넣어 data라는 객체를 생성하는 과정을 거쳤다. 하지만 판다스 라이브러리를 활용하면 그 단계가 아래와 같이 간소화된다.
파일이 정상적으로 불러왔는지 확인하기 위해 df.head를 활용한다. 1)df.head를 작성하면 모든 값을 불러오고 2)df.head()를 작성하면 기본값으로 5개의 row를 불러오며, 3)괄호 안에 특정 숫자를 넣으면 그 갯수만큼 값을 불러오며, 4)df.tail()를 작성하면 마지막 5개 row의 값을 확인할 수 있다.
참고. 판다스 라이브러리는 데이터프레임(df)을 기준으로 데이터분석을 진행한다.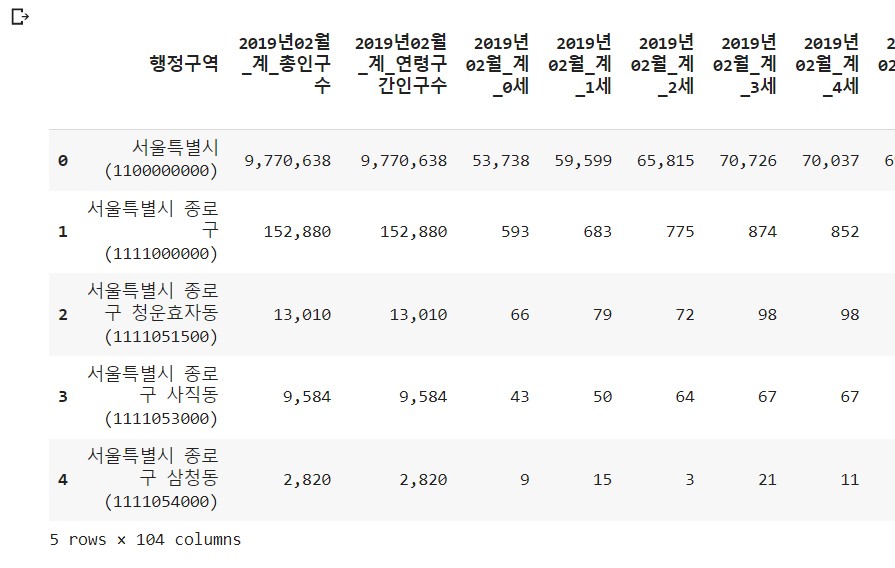
읽어온 자료의 정보를 파악하기 위해서는 df.info() 함수로 값을 확인할 수 있다. 판다스 라이브러리에서 다루는 자료의 형태는 str이나 int보다 상위 개념인 object를 활용한다. 아래 정보에 따르면, 이 df는 숫자형 자료를 1개(첫번째 열 index값을 말한다), object자료를 103개 가지고 있다.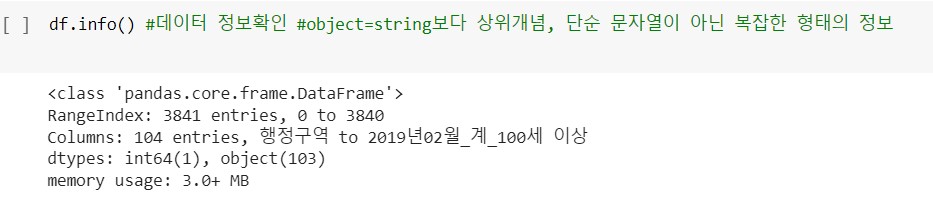
데이터 전처리를 하는 과정은 다음과 같다. 1)행정구역의 숫자로 이루어진 행정코드를 삭제, 2)공통적으로 작성된 컬럼명을 간소화, 3)자료 내 문자열을 제외한 모든 기호를 삭제, 4)데이터 내 자료형태를 통일하여 분석처리하기 위해 행정구역을 인덱스로 변경, 5)비율 계산을 위해 df 전체를 숫자형으로 바꾼다.
1)행정구역의 숫자로 이루어진 행정코드를 삭제: 판다스 라이브러리 내에서 split을 적용하기 위해서는 '행정구역'을 명시적 형변환하고 적용한다. (이 자료는 str이야, str으로 설정하고 split) 이후 '행정구역'열에 split한 첫 값을 불러온다.

2)공통적으로 작성된 컬럼명을 간소화: 컬럼명에 공통적으로 들어있는 '2019년02월계'는 불필요한 자료이므로 split한 후 딕셔너리 문법을 활용하여, 기존 이름에 새로운 이름을 1:1 매핑하여 값을 넣어준다. 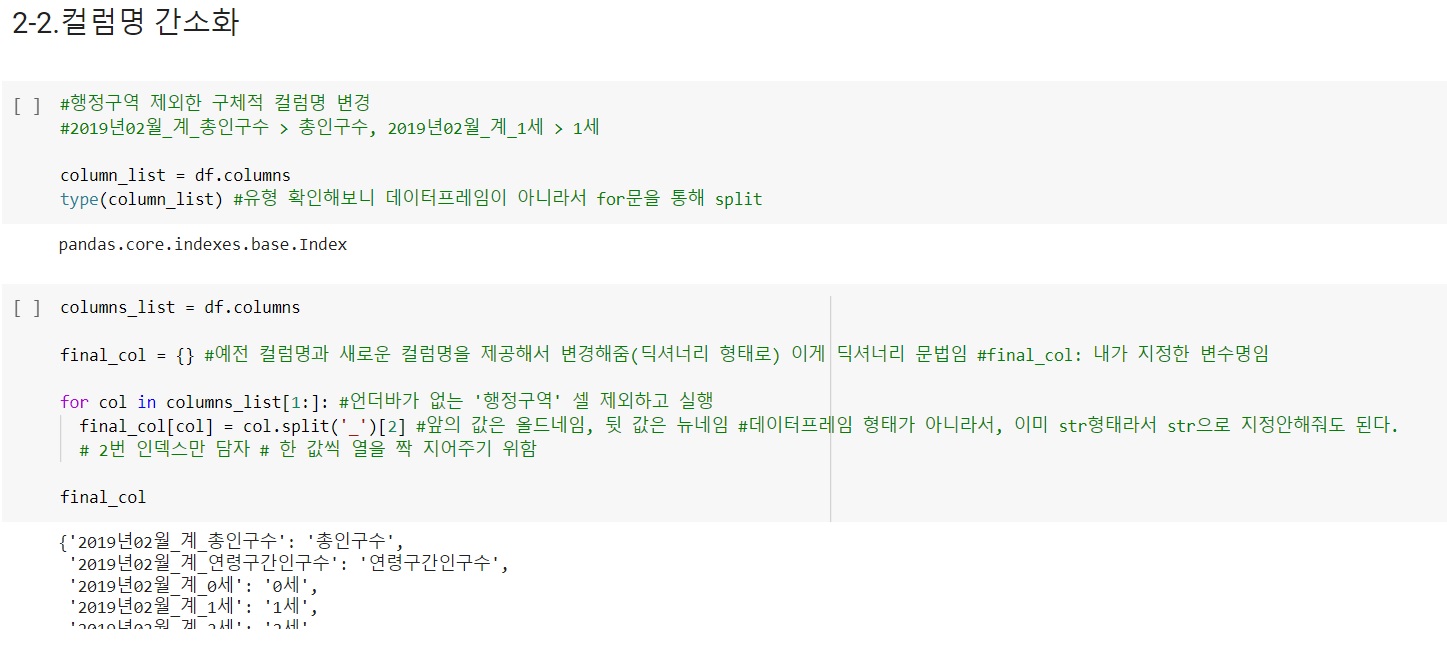
3)자료 내 문자열을 제외한 모든 기호를 삭제: 문자열이 아닌 특수기호를 공백으로 바꾸라는 치환 함수를 활용하고, 이 때 '문자열이 아닌'이라는 표현은 정규식을 활용하겠다는 구문을 추가로 작성한다. 참고. 'inplace = True'는 자료 변경을 지금 바로 반영하라는 구문.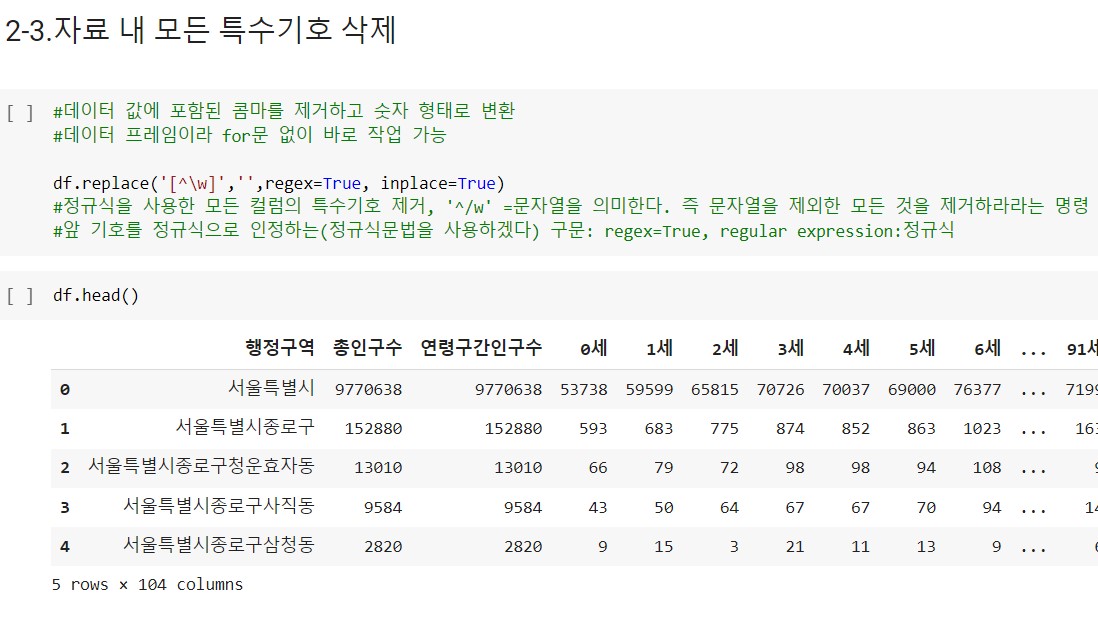
4)데이터 내 자료형태를 통일하여 분석처리하기 위해 행정구역을 인덱스로 변경: 유일하개 string값을 가진 '행정구역'을 index로 새로 설정. 새로이 설정할 column의 이름을 keys 값에 입력.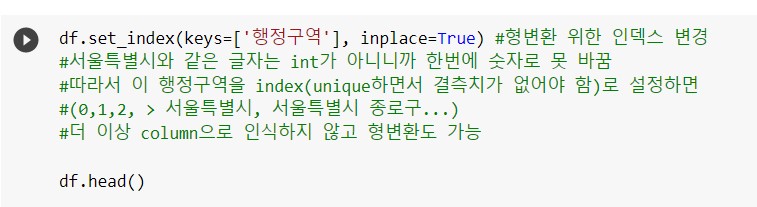
5)비율 계산을 위해 df전체를 숫자형으로 바꾸고 df로 설정
참고. 빈 값이 있는지 확인 후 null인 값 삭제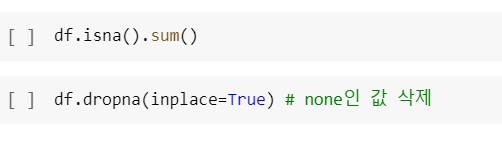
데이터 전처리가 끝나면 총 인구 수로 나누어 비율을 계산한다. 총 인구 수를 기준으로 각 연령의 비율을 확인해야 하므로 열을 기준(axis=0)으로 값을 계산한다.

df를 기준으로 계산되기 때문에 필요한 정보값 외에는 삭제한다.

분석 오류 시 대체할 파일을 미리 백업해놓기 위해 아래와 같은 작업을 실행한다. 
인구구조가 알고 싶은 지역을 사용자로부터 입력받고 그 값을 df에서 찾고 그 지역의 해당 열만 새로운 df를 찾는다. 그리고 해당 지역의 row값을 df2에 저장한다.
추출한 데이터의 구조는 차트를 그릴 경우, 행(index, 지역)=x축값, 열(나이)=legend(범례), 데이터(전체인구 대비 비율)=y축값이 된다. 그 결과 꺾은선 그래프는 101줄을 그리기 때문에 Transpose를 적용해 열과 행을 바꿔 나이에 따른 전체인구 대비 비율을 볼 수 있게 만들어야 한다. 자료 확인을 위해 아래와 같이 데이터 셋을 변경하여 확인한다.
df2.T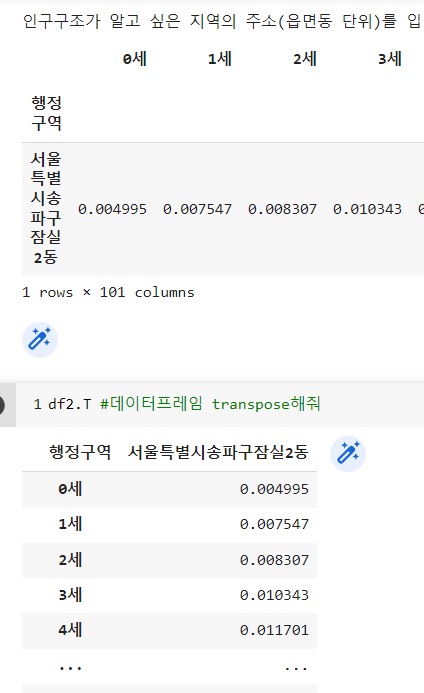
행과 열을 바꾸면 위와 같이 나이(행), 지역(열)이 바뀌고 한 줄의 꺾은선 그래프를 그릴 수 있는 자료형태가 되는 것을 확인한다.
파이썬에서 기본적으로 제공하는 matplot 라이브러리를 활용해 차트를 그린다. 이때 데이터 셋을 Transpose하여 그린다.
import matplotlib.pyplot as plt
plt.style.use('ggplot')
df2.T.plot()
plt.show()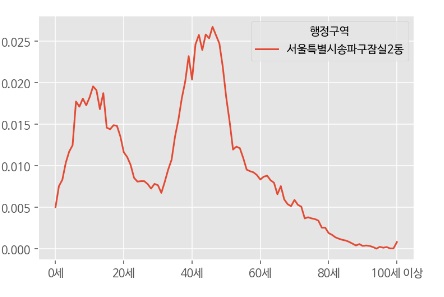
이제 잠실2동과 유사한 인구구조를 가진 지역을 찾아야한다. df의 모든 행에서 df2(잠실2동)의 나이별 비율값을 빼서 차이 값을 모두 구할 수 있다.(home-away)
df.sub(df2.iloc[0],axis=1)
# axis=1 행 기준으로 값을 빼라(0은 열 기준)
# df2.iloc[0]: 'df2'라는 데이터프레임의 인덱스 중 1번째 행을 의미(숫자형태로 location디텍션)
# df2.loc['서울특별시 송파구 잠실2동']: 'df2'라는 데이터프레임의 인덱스 중
'서울특별시 송파구 잠실2동' 인덱스를 가진 행을 의미(문자열로 location디텍션)
위의 결과는 지역별 차이를 한 눈에 파악하기 어렵다. 따라서 나이별 차이를 모두 더해서 총 차이값을 구한다.(참고1) 기준값인 잠실2동보다 전체인구 대비 차지하는 비율이 작은 지역은 sub의 결과가 음수로 나온다.

음수는 기준 값과 동일함을 넘어 더 작은 차이를 갖기 때문에 기준인 잠실2동의 인구구조와 매우 다른 구조를 갖더라도 가장 유사한 인구구조를 가졌다고 잘못된 결과를 산출한다. 따라서 모든 값을 제곱하여 동일하게 양수로 만든다.
이를 위해 파이썬에서 기본적으로 제공하는 수치해석용 모듈인 numpy(넘파이)를 활용한다.
import numpy as np
np.power(df.sub(df2.iloc[],axis=1),2).sum(axis=1).sort_values()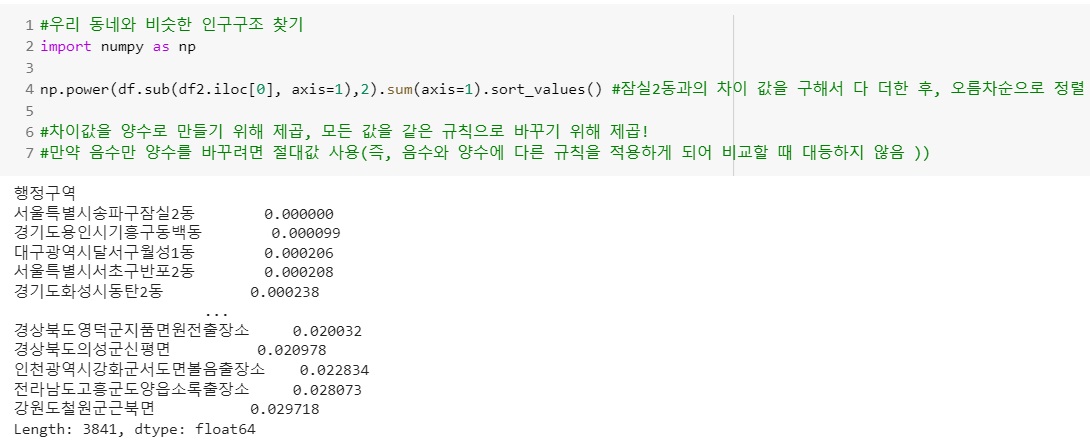
결과값을 보면 가장 작은 값부터 오름차순으로 정렬되어있다. 당연히 자기자신과 비교한 값은 0이다. 그리고자 하는 차트는 잠실2동과 비슷한 상위 5개 지역이므로 자기자신을 빼고 차트를 그린다.
df.loc[np.power(df.sub(df2.iloc[0], axis=1),2).sum(axis=1).sort_values().
index[1:6]].T.plot()
#index[0]은 잠실2동 값이라서 [1:6]으로 추출해 5개 지역을 그린다.
#만약 기준값인 잠실2동과 비교하는 것이 목적이라면 [0:6] 그리면 된다.
plt.show() 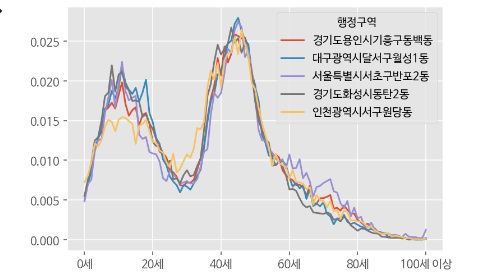
<참고1. sub(axis=1)와 sum(axis=1)를 다시 헷갈려할 미래의 나를 위한 메모>
sum(axis=1)에 대해 직관적인 이해가 필요하면 "Numpy의 axis에 따른 연산" 을 참조하자.
sub를 할 때는 axis=1이 기준이라서 각각의 row를 잠실2동 row로 아래와 같이 나눴다. '수치계산 할 때 행끼리 움직여~'
(즉, A지역의 행 - 잠실2동 행)
| 0세 차이 값 | 1세 차이 값 | 2세 차이 값 | ... | 100세 차이 값 |
|---|---|---|---|---|
| A지역 0세 비율 - 잠실2동 0세 비율 |
A지역 1세 비율 - 잠실2동 1세 비율 |
A지역 2세 비율 - 잠실2동 2세 비율 |
A지역 100세 비율 - 잠실2동 100세 비율 |
|
| B지역 0세 비율 - 잠실2동 0세 비율 |
B지역 1세 비율 - 잠실2동 1세 비율 |
B지역 2세 비율 - 잠실2동 2세 비율 |
B지역 100세 비율 - 잠실2동 100세 비율 |
|
| c지역 0세 비율 - 잠실2동 0세 비율 |
C지역 1세 비율 - 잠실2동 1세 비율 |
C지역 2세 비율 - 잠실2동 2세 비율 |
C지역 100세 비율 - 잠실2동 100세 비율 |
|
| D지역 0세 비율 - 잠실2동 0세 비율 |
D지역 1세 비율 - 잠실2동 1세 비율 |
D지역 2세 비율 - 잠실2동 2세 비율 |
C지역 100세 비율 - 잠실2동 100세 비율 |
sum(axis=1)에 대한 해석: 모든 지역의 잠실2동과의 나이별 차이값을 더할 때는 A는 A지역끼리, B는 B지역끼리, C는 C지역끼리 더해야한다. '값을 더할 때 행 안에서만 더해'
(즉, A지역의 행 - 잠실2동행 값의 합계)
| 나이별 차이 값 합계 |
|---|
| 0세~100세의 A지역 - 잠실2동 결과값 합계 |
| 0세~100세의 B지역 - 잠실2동 결과값 합계 |
| 0세~100세의 C지역 - 잠실2동 결과값 합계 |
| ... |
| 0세~100세의 Z지역 - 잠실2동 결과값 합계 |
만약 sum(axis=0)를 계산해야 했다면 아래와 같은 결과가 나왔을 것이다.
(즉, A~Z지역 0세의 잠실2동 0세와의 모든 차이값의 합계...)
| 0세 차이 값 합계 | 1세 차이 값 합계 | 2세 차이 값 합계 | ... | 100세 차이 값 합계 |
|---|---|---|---|---|
| (A지역 0세-잠실2동 0세)+ (B지역 0세-잠실2동 0세)+ (C지역 0세-잠실2동 0세)+ +... +(Z지역 0세-잠실2동 0세) |
(A지역 1세-잠실2동 1세)+ (B지역 1세-잠실2동 1세)+ (C지역 1세-잠실2동 1세)+ +... +(Z지역 1세-잠실2동 1세) |
(A지역 2세-잠실2동 2세)+ (B지역 2세-잠실2동 2세)+ (C지역 2세-잠실2동 2세)+ +... +(Z지역 2세-잠실2동 2세) |
(A지역 100세-잠실2동 100세)+ (B지역 100세-잠실2동 100세)+ (C지역 100세-잠실2동 100세)+ +... +(Z지역 100세-잠실2동 100세) |

{kind=link}