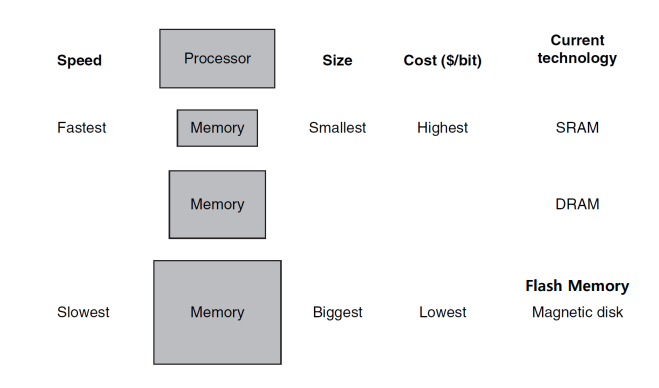
Memory Hierarchy
Main Concept of Memory Hierarchy
-
Caching: temporal locality, spatial locality에 의거해 중요도가 높은 데이터일수록 Processor와 가까운 memory에 데이터를 위치시킨다.
Conclusion

- Q1 : one place, a few places, any place
- Q2 : indexing, limited search (set indexing) , full search and a separate lookup table (0 comparison)
- Q3 : LRU,Random,Round Robin
- Q4: write-through,write-back
Q1 : Where can a block be placed
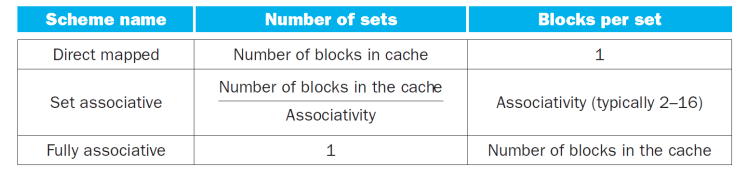
Q2 : How is block found (비교기 그림 질문)
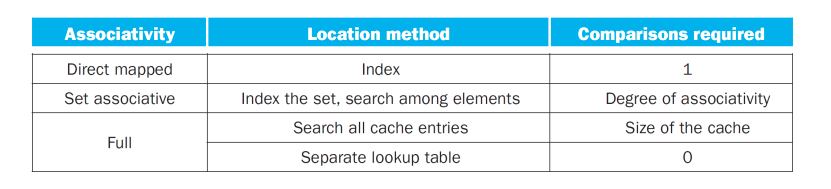
Q3 : Which block should be replaced on a cache miss
- LRU (reference bit가 0인)
- random : 아무거나
- virtual memory: LRU를 많이 쓴다
- round robin 방식도 있음Q4 : What happens on a write
- write-through : cache 내용바뀌면 바로 main memory에도 반영 하지만 접근 시간이 많이 걸림
- write-back : cache가 변하면 바로 main memory에 반영하는 것이 아니라 write 된 cache의 데이터가 또다른 값으로 write될 때 그때 main memory로 가 변화된 값을 반영한다. 이때 write buffer 안에 든 모든 데이터의 dirty bit는 1이다.
- write-buffer : memory에 아직 written 되지 않는 것들으 버퍼에 보관하고 written 될때 삭제한다 만약 buffer가 차면 빈 공간이 생길때까지 CPU를 stall한다.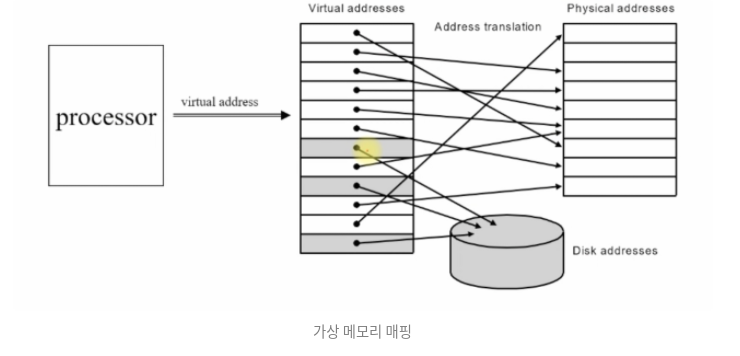
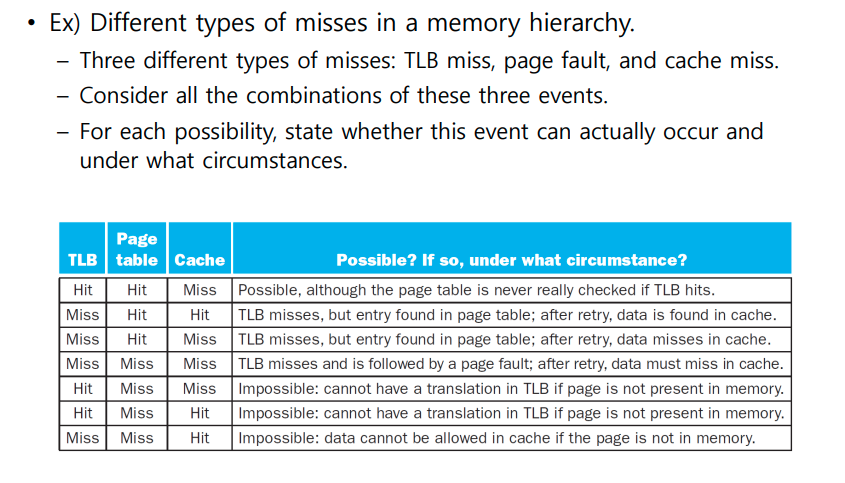
Sources of Misses
- Compulsory misses : 처음 시작할 때 다 비어있으므로 cache miss가 발생한다. (cold start misses) (first access to a missed block)
- capacity misses: cache 사이즈가 너무 작아 충분한 데이터가 없으므로 cache miss가 발생
- conflict misses: replace과정에서 지워짐으로 인해 발생하는 miss (지워진 값에 다시 접근할 때 cache miss가 발생하므로)
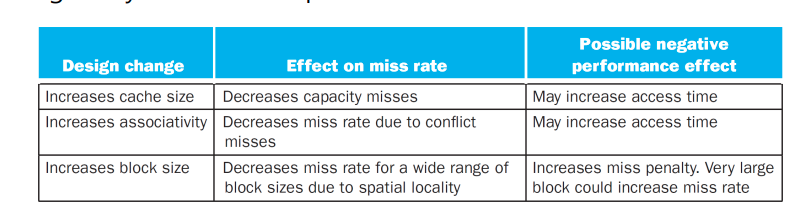
Cache Design trade offs
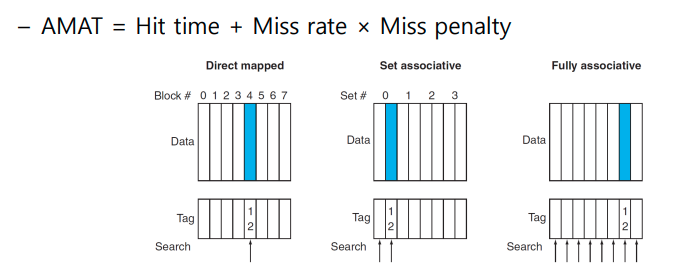
- 핵심 : AMAT (Average Memory Access Time) 을 줄여야 한다. = Hit-Time + Miss rate X Miss Penalty
Cache Control
- block offset:2
Cache Coherence (질문하기 이동 복사)
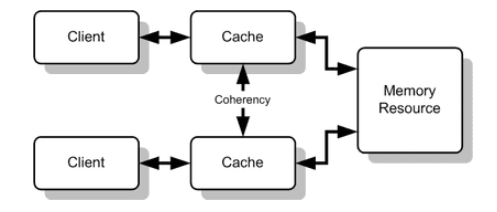
Cache coherence protocols in multi-processors
-
BUS Snooping : 메모리 access를 감지항 캐시의 라인 상태를 조절하는 방법 , Each cache monitors bus reads/writes
-
Snoop Controlooer: 버스를 항상 감지하며 다른 CPU가 memory access하는지를 검사하여 그 결과에 따라 자신의 캐시 블록 상태를 조절
-
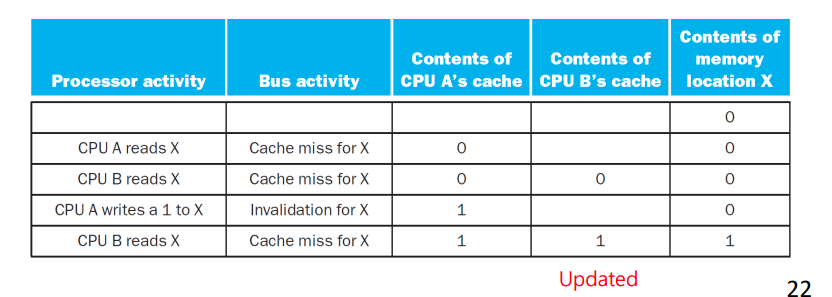
write-through coherence protocol: write-through 쓰기 방식에서 캐시 일관성 유지를 위해 사용하는 프로토콜
- 스누프 제어기 동작: 각 프로세서의 스누프 제어기는 main memory에 write를 시도하는 것을 감지하고, 자신의 캐시가 새롭게 갱신되는 기억장치 블록을 저장하고 있다면 해당 라인을 무효화 시킨다.
- 프로세스가 무효화된 블록을 엑세스하는 경우는 cache miss 처리
Memory Consistency
- Cache 내용과 memory의 내용이 다르지 아니된다. 그러므로 write 과정은 다른 multi processor도 바뀐 걸 확인해야 끝난다. 아니면 Consistency 유지 불가능
Miss Rate and Miss Penalty
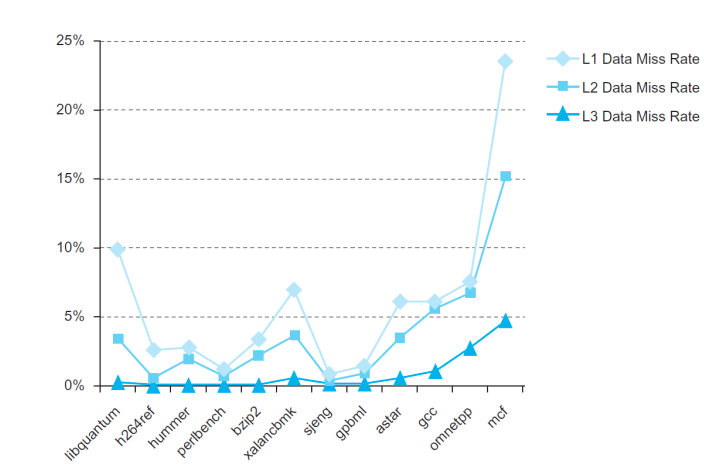
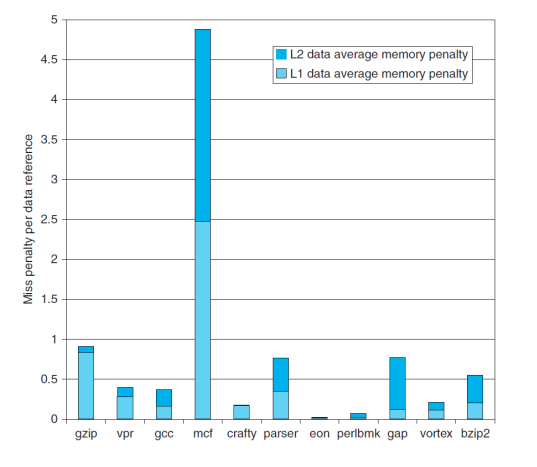
Fallacies and Pitfalls
-
Pitfall 1 : Ignoring memory system behavior when writing programs or when generating code in a compier
-
Pitfall 2 : Forgetting to accout for byte addressing or the cache block size in simulating a cache -> offset index이 제외한 나머지가 block이다.
-
EX2) A cache with 256 bytes and a block size of 32 bytes
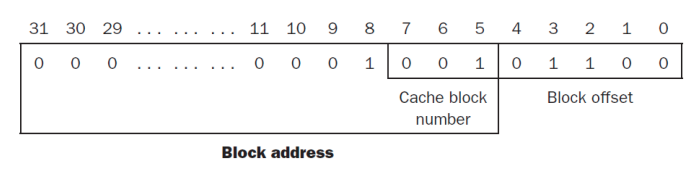
- which block does the bytes address 300 fall?
- block address [300/32]=9
- 9 modulo 8(the number of blocks)=1
-
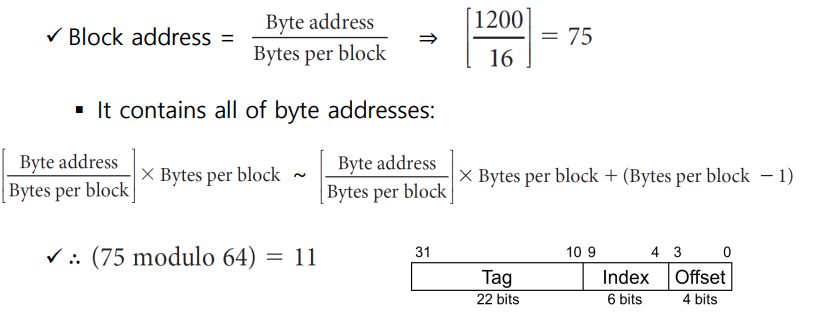
Consider a cache with 64 blocks and a block size of 16 bytes. To what block number does byte address 1200 map
- (Block address) modulo (Number of bloks in the cache)
-
-
Pitfall 3 : Having less set associativity for a shared cache than the
number of cores or threads sharing that cache- core 갯수보다 적어도 Associativity가 많아야 한다. 그렇지 않으면 conflict miss가 자주 발생하여 Miss rate가 상승한다.
- more cores -> need to increase associativity
-
Pitfall 4 : AMAT to evaluate the performance of memory hierarchy in an out-of-order processor
- ignore effect of non-blocked accesses
- instead, evaluate performance by simulation
-
Fallacy 1 : Disk failure rates in the field match their specifications -> Disk AFR(서버 고장은 사실 잦다. )
Conclusion

Review Again
-
Memory Hierarchy uses locality ; 최근 access하거나 그 주위에 있는 데이터를 processor랑 최대한 가까운 곳에 위치시킨다.
-
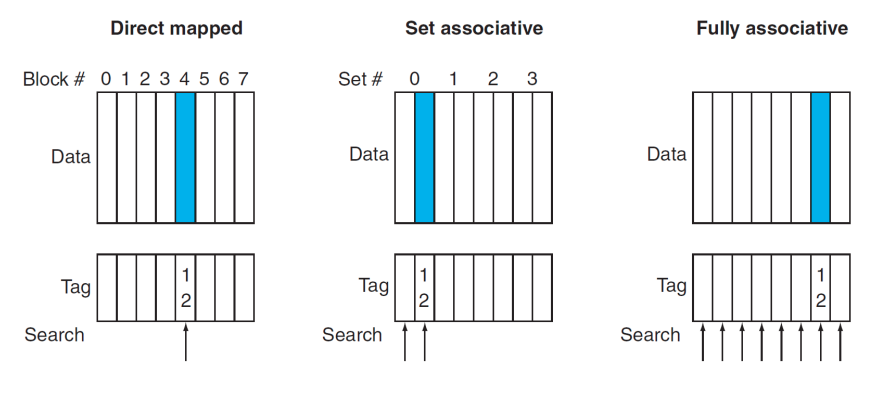
Types of cache
-
Direct mapped cache
- 각 메모리 주소는 cache 안에 지 주소가 배정되어 있다.
- mapping method: (block address) modulo (Number of sets )
- direct mapped 에서 number of sets==number of blocks
-
set associative
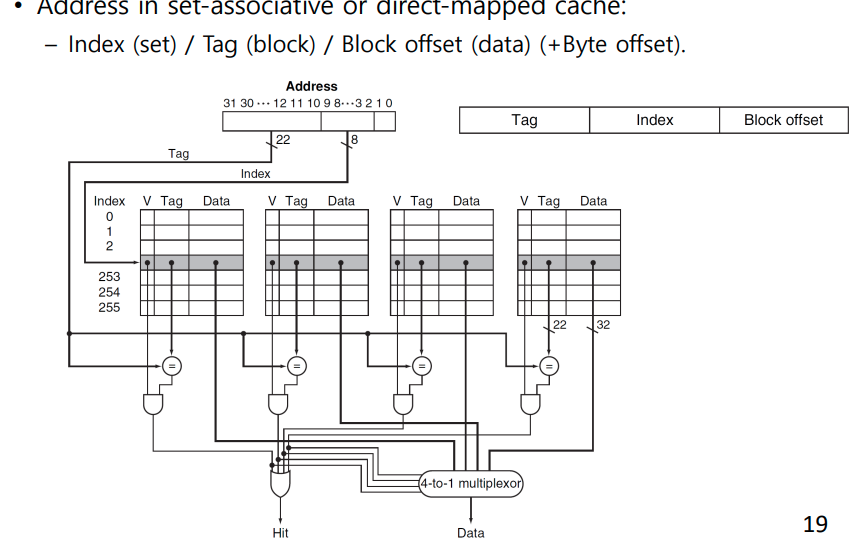
-
-
The TLB aces as a cache of the page table
- tag 있으면 cache에 있는 것이다.
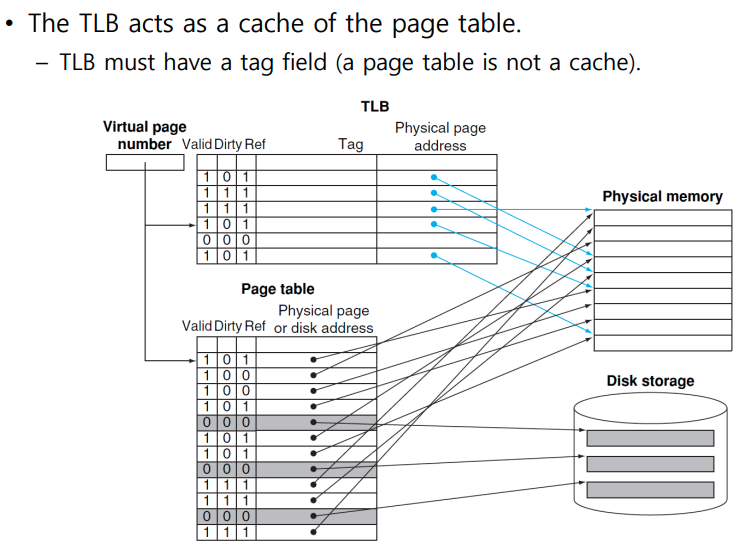
- TLB 에 없으면 Page table에 가고 Page table에도 없으면 Disk 의 swap space로 간다.
- tag 있으면 cache에 있는 것이다.
-
Cache tag is translated before cache lookup.
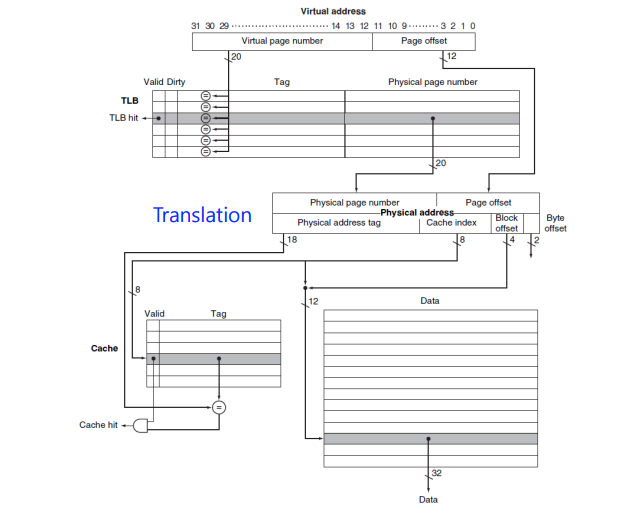
Cache Memory1
- Cache: the level of memory hierarchy closest to the CPU (CPU 에 가장 가까이 위치한 메모리)
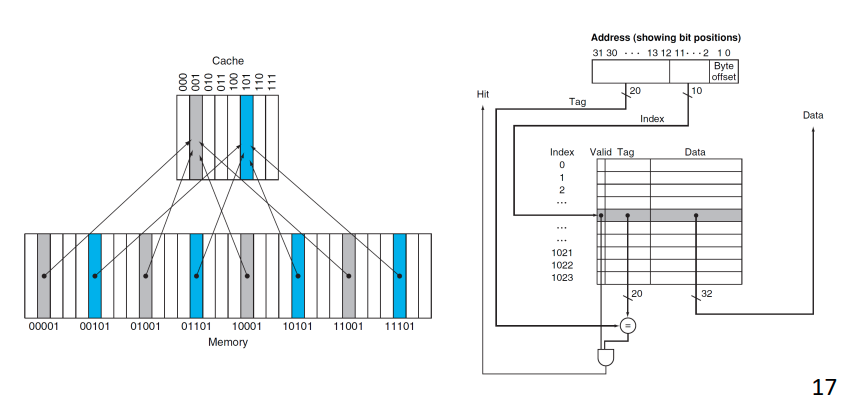
Direct mapped cache
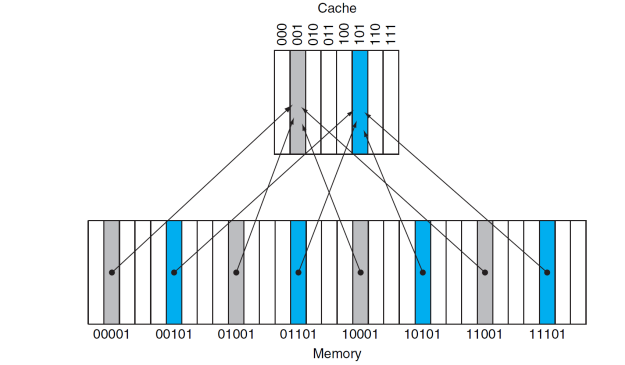
- 메모리에 각 주소는 자기 cache 자리가 정해져 있다. -> Direct Mapped Cache
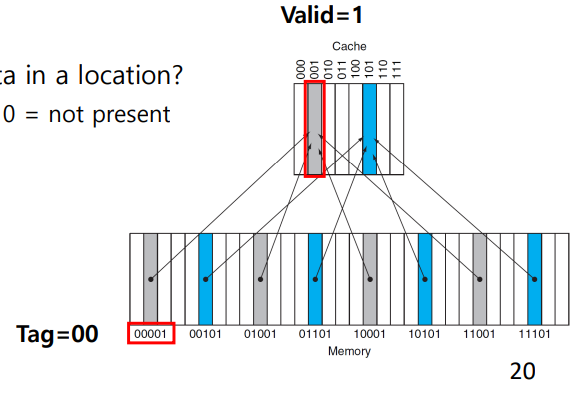
- tag bit
- Cache의 데이터가 Main Memory 어느 주소에서 왔는지 알 수 있게 해주는 정보
- memeory access할때 tag를 비교해서 지금 cache에 저장되어 있는 데이터가 내가 찾고있는 게 맞는지 확인할 수 잇다.
- 만약 tag가 갖지 않아면 miss라서 그 주소를 가지고 main memory에 가서 찾아와야 한다.
- valid bit
- Cache에 데이터가 있는지 없는지 나타내는 bit 없다면 Miss이므로 아래계층에서 찾아와야 한다.
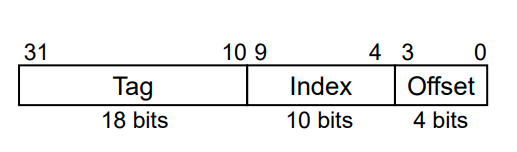
Cache in 32-bits address
- 잠깐 우리가 chapter 4에서 배웠던 memory에 접근하는 건 사실 cache 메모리이다. 그러니 32bit memory address는 cache에 접근하기 위해서였던 것!!
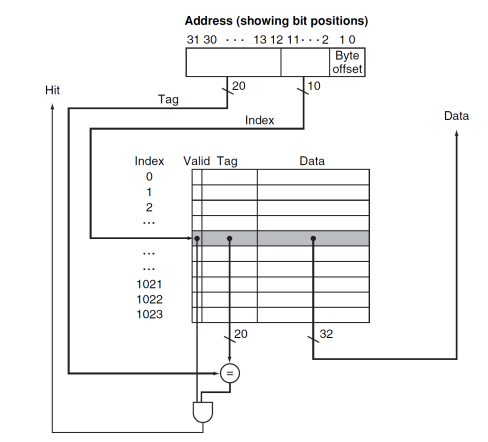
- 원리: Index에 접근한다 .valid가 있는지 1인지 확인한다. 0이라면 데이터가 아예 없는 것이기 때문에 해당 주소로 Main memory에서 가져온다. (Miss) 1이더라도 Tag가 다를 수 있다. Direct Mapped Cache에 한 block에는 unique한 main memory block이 오는 것이 아니기 때문에 만약 tag가 같지 않다면 (Miss) 다시 갔다 와야 한다. valid도 1이고 tag도 같아야 하기 때문에 두 signal이 통과한 AND Gate의 output이 1이어야 Hit이다
- Example

- cache가 저장해야 할 word의 갯수 4x2^10
- 4 word이기 때문에 index 2^10개가 되어야 한다.
- 그럼 32bit address는
- offset=(2+2)(4 word를 구분하기 위해서는 2 bit면 충분하기 때문)
- index=10
- tag=18
로 구성된다
- total bits 구하기
- 2^10(index 갯수)(1(valid)+432(block size)+18(tag))
- 147 kib == 18.375 kiB
Cache Memory2
-

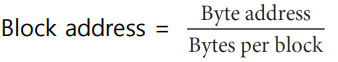
Cache Misses (질문)

Handling Writes (질문 write-back은 write-buffer의 진화 버전인가)
- 상황: we wrote the data into only the data cache (without changing main memory) -> inconsistent
- consistent하게 해야 해
- 방법 1 : write-through
- cache가 바뀌면 main memory도 바로 변화를 반영한다.
- 단점: write takes longer
3122d6d-5c8d-4fac-9ba6-4c2c5269f445/image.png)

- write-back
- 일단 cache 만 update하고 main memory에는 반영하지 않는다.
- 만약 update된 자리에 또 다른 데이터로 update되면 그때 main memory에 가서 update해준다.
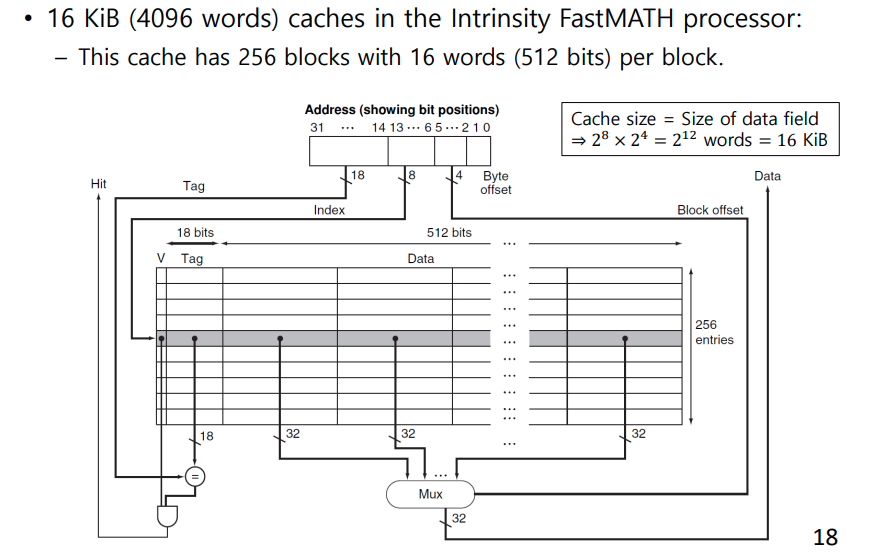
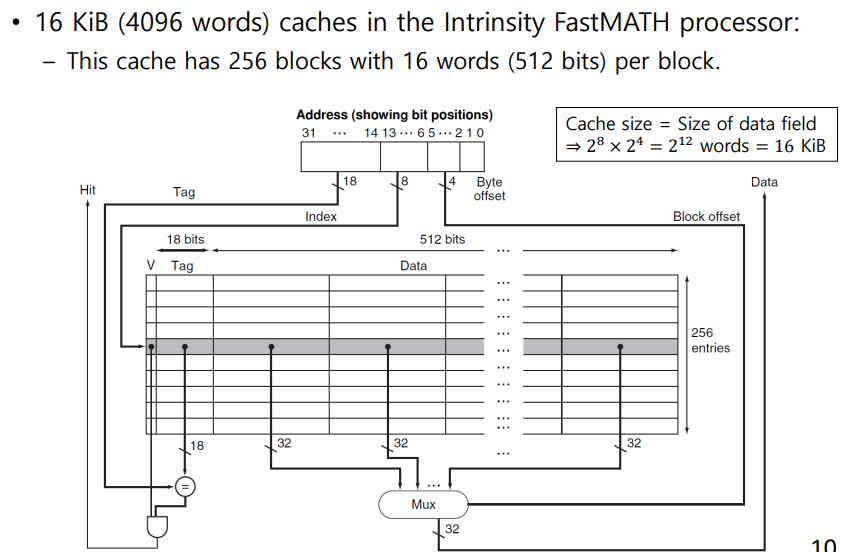
Example Cache: Intrinsity FastMATH
Measuring Cache Performance 질문: Instruction Miss도 결국 Read Miss로 봐도 되는가 Instruction Cache에 read를 실패했기 때문Performance를 계산하기 위해 stall을 따져야 하기 때문에 모든 시간은 일단 clock으로 바꾼다.
-
결국 Performance는 CPU time으로 결정한다.
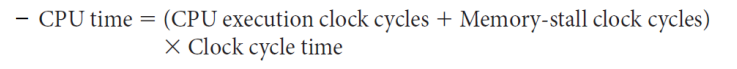
-
Memory-stall clock cycles
- Memory-stall은 2종류지 read할 때 그리고 write할 때 (Cache에 없어 miss한 경우 stall 할 수 밖에 없다)

- Memory-stall은 2종류지 read할 때 그리고 write할 때 (Cache에 없어 miss한 경우 stall 할 수 밖에 없다)
-
Example

- Perfect: 2 default
- 현실: 2default + 0.02100 + 0.040.36*100=5.44
- 2.72 times faster
Average Memory Access Time
- Cache에 가는 시간(Hit time) default + Miss-rate*Miss_Penalty

Associative Caches
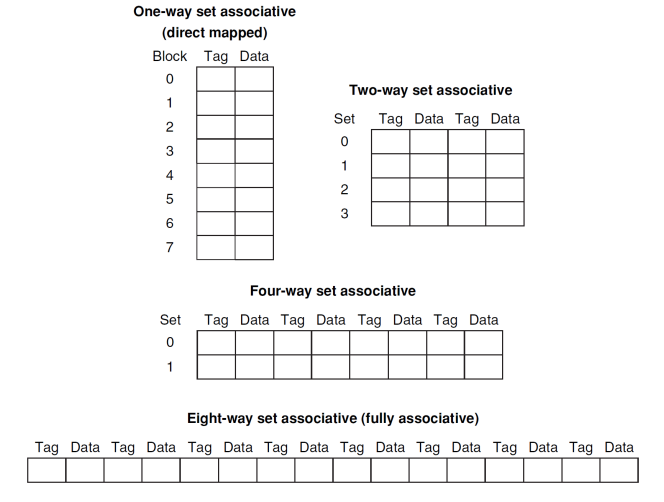
- Fully associative cache
- allow a given block to go in any cache entry
- requires all entries to be searched at once
- comparator per entry (expensive)
- n-way set associative cache:
- each set contains n entries
- block number determines which set
- (block number) modulo (number of sets in the cache)
- search all entries in a given set at once
- n comparators (less expensive)
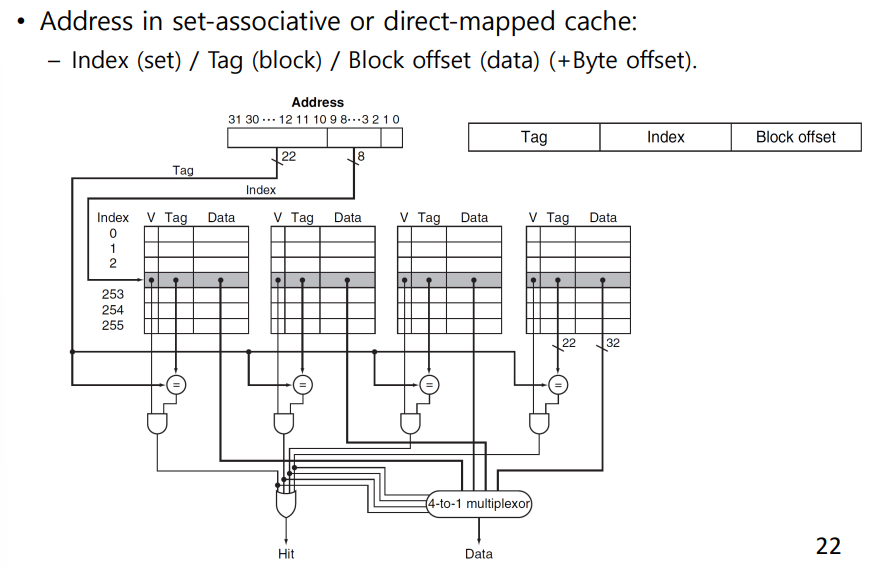
Locating a Block in the Cache
Choosing Which Block to Replace
- Direct mapped: 이미 정해져서 따로 할 초이스가 없다
- Set associative: set은 정해지지만 나머지는 빈 곳에 넣으면 된다. 만약에 빈 곳이 없다면 Random이나 LRU
- LRU: 가장 오랜된 걸로 바꾼다. (Ref비트 참고)
- Random : 아무거나
- Round Robin
Size of Tags vs Set Associativity
-> direct mapped은 모든 block이 set
-> n-way은 한 set당 들어갈 수 있는 entri 즉 n개의 cache를 두고 n개의 comparator을 둔다
-> n-way에서 index는 set index
-> associativity가 커질수록 index는 작아지는 대신에 tag field 크기는 커진다.
- Increasing associativity requires more comparators and more tag bits per cache block



Cache Memory 3
Multilevel Caches
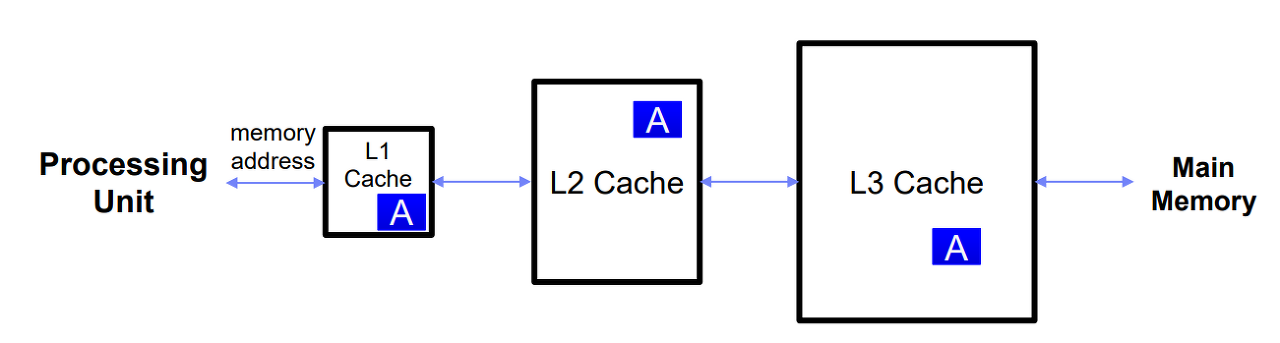
- Primary cache: smaller but faster
- Secondary Cache: larger,slower but still faster than main memory
Performance of Multilevel Caches >> Performance를 계산하기 위해 stall을 따져야 하기 때문에 모든 시간은 일단 clock으로 바꾼다.

- Only one cache
- main memory 접근 시간은 100ns 1초에 4G clocks이니 400clocks
- cache miss가 발생하면 400 clocks 또한 stall 해야 함
- 1+400*0.02=9clocks (CPI)
- two cache
- 1+(secondary에서 끝)+ (main memory까지 가야함)
- secondary=20cloks*0.02
- mainmemory=400clocks*0.005=2
- 3.4 CPI
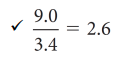
Interactions with Software
- Quicksort has many fewer misses per item to be sorted
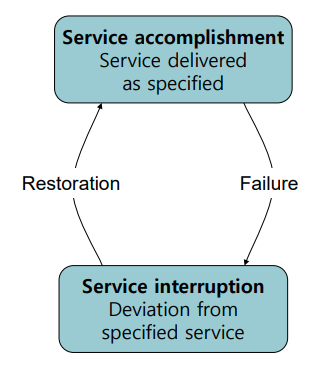
Dependability
- Reliability : mean time to failur(MTTF) -> 고장나는데 걸리는 시간 (보통 제품 수명이 최댓값으로 설정 가능)
- Annual Failure Rate: a failure rate in a year for a given MTTF
- Mean time to repair (MTTR) -> 짧을수록 좋지
- Mean time between failures(MTBF):
- MTBF=MTTF+MTTR
- availability=MTTF/(MTTF+MTTR)

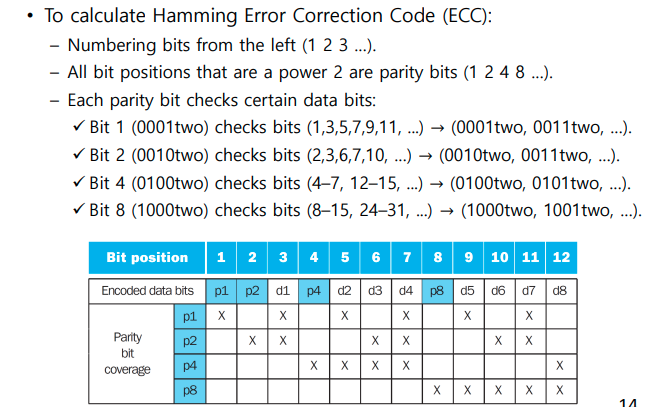
The Hamming SEC

Virtual Memory
https://jesus-never-fail.tistory.com/30
Definition
- 가상 메모리는 메모리가 실제 메모리보다 많아 보이게 하는 기술로, 어떤 프로세스가 실행될 때 메모리에 해당 프로세스 전체가 올라가지 않더라도 실행이 가능하다는 점에 착안하여 고안되었음.
- A technique that uses main memory as a "cache" for secondary storage
- remove the programming burdens of limited amount of main memory
Terminology
- CPUand OS translate virtual addresses to physical address
- Cache "block" <> VM "page"
- Cache "miss" <> VM "Page fault"
Virtual Memory Mapping
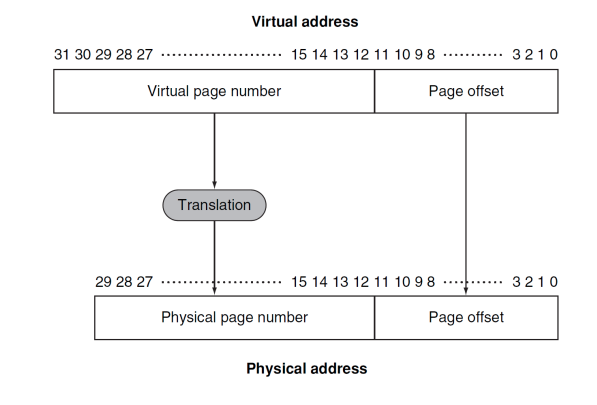
- 가상 주소 테이블에서 물리적 주소 테이블로 매핑한다.
- 가상 주소 테이블이 더 크기 때문에 매핑되지 못하는 주소가 있고, 이는 하드디스크로 들어간다. (하드디스크 크기가 굉장히 크기 때문, 이를 통해 굉장히 큰 크기의 메모리를 사용하는 것처럼 보임)
- processor의 가상 주소 중, 물리적 주소에 매핑되지 못한 주소를 가리 키는 것 -> Page fault
Mapping from a virtual to a physical address

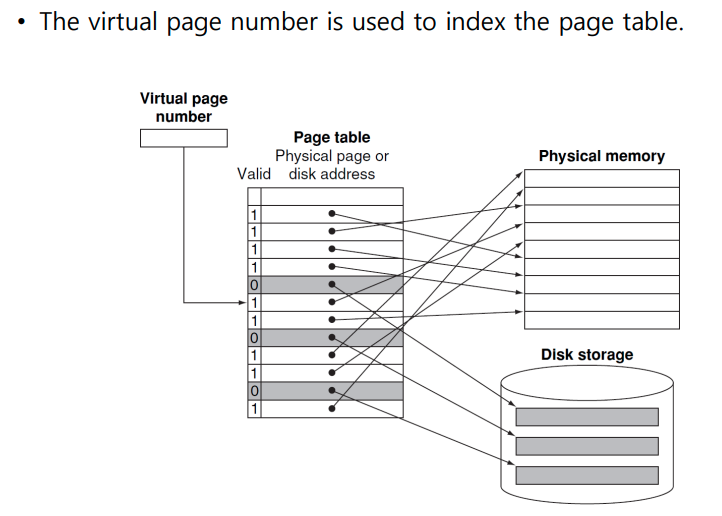
Page Table
- Page Table: the table containing virtual to physical address translations
- Indexed by virtual page number
- If page is present in memory
- 해당 virtual page number index에 physical page number가 들어가 있다.
- 3개의 bit (valid,reference,dirty)
- reference : 최근 것인지 LRU 알고리즘을 사용할 때 참조하느 ㄴ비트
- dirty -> 갱신되었는데 그 갱신된 것이 메모리에 적용이 되었는지 -> write-back write-through 방식으로 갱신이 메모리에 적용이 되었다면 0이 된다.
- If Page is not present in memory
- disk의 swap 공간을 참조한다.
- swap space: the space on the disk reserved for the full virtual memory space of a process
- page fault: 가상 메모리 miss
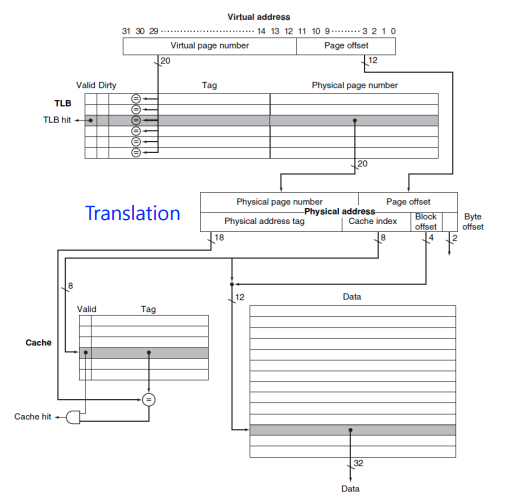
Fast Translation Using a TLB

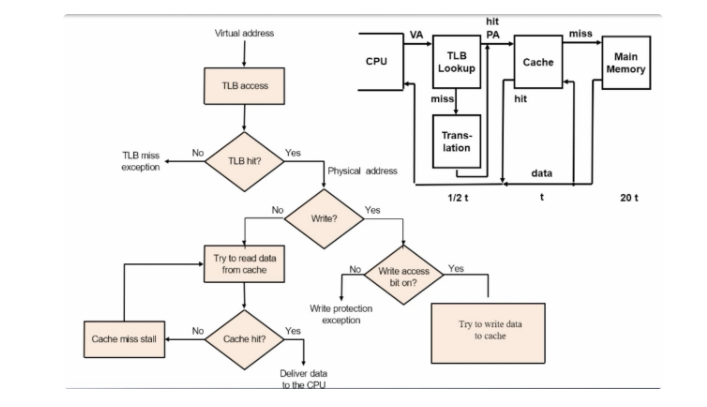
- 위 방식의 문제는 무엇인가
- one to access the page table
- next to access the actual memory
- VA는 Main memory에서 PA로 번역된후 cache에 접근한다.
- TLB: 주소 번역을 위한 특별한 캐시
- Page Table의 Cache (Tag가 있기 때문)
- a fast cache of page table within the CPU
- Cache이기 때문에 반드시 tag field가 필요하다.
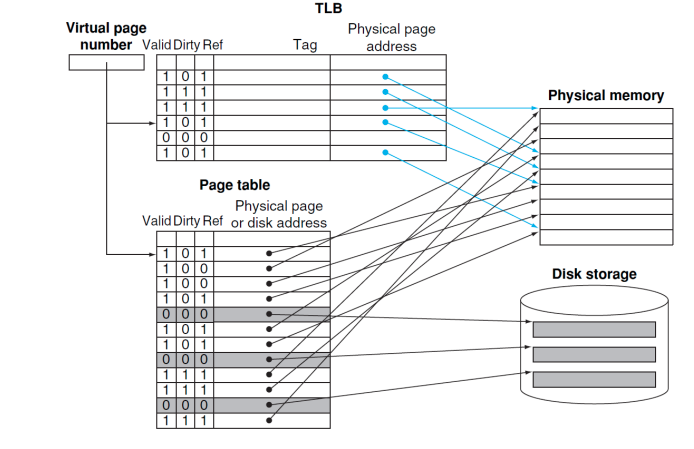
- TLB Mapping 과정
- VA를 TLB로 보낸다.
- TLB에서 hit가 나면 물리적주소로 매핑한다.
- miss가나면 page table로 이동해 해당 주소의 값을 TLB로 가져온다.
- 만약 page fault가 나면 디스크의 swap space를 참조해서 데이터를 물리적 메모리로 가져와 저장하고 page table이 이 주소를 가르키도록 수정한다. 만약 빈 공간이 없다면 LRU로
- page update -> TLB update
- page fault가 아닌경우 TLB만 업데이트
- Handling Page Fault
- virtual address로 disk의 swap space에 가서 page를 가져온다
- page를 물리적 메모리 주소 중 빈곳에 넣는다.
- 물리적 메모리 주소 중 빈칸이 없다면, replacement 정책을 사용한다. (LRU)
- virtual mapping table을 updating한다. 이후 TLB도 updating한다. (Page table, TLB table)
Try to minimize page fault rate: fully associative placement, write-back system, smart replacement algorithms(LRU,Round Robin,Random)