Improved Soft Actor-Critic: Mixing Prioritized Off-Policy Samples with On-Policy Experience -논문 리뷰
강화학습 논문 리뷰
논문 출처: https://arxiv.org/abs/2109.11767
INTRODUCTION
https://velog.io/@everyman123/PRIORITIZED-EXPERIENCE-REPLAY-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
Model-free RL에서 중요한 과제 중에 하나는 Sample-Efficient를 올리는 것이다. Model-free는 환경 (상태 천이 함수)에 대해서 추정하지 않고 환경과 상호작용하며 얻게 되는 transition을 토대로 Policy를 갱신하며 가치함수를 추정한다.
Model-free RL의 방법중에 하나인 On-Policy 방법은 지금 정책의 좋고 나쁨을 평가할 수 있다. 하지만 그 정책에서 만들어진 transition으로만 학습을 진행하고 학습이 끝난 후 폐기하기 때문에 Sample Efficient가 매우 낮고 Correlation에 취약하다.(다음 정책은 이전 정책에 영향을 받기 때문에 Local Optima에 빠질 가능성이 매우 높다.)
반면에 Off-Policy 방법은 정책이 바뀌는 것과는 별개로 Agent가 계속 만들어낸 데이터를 Replay Buffer에 저장하고 Randomly sampling을 통해 구성한 Batch로 Network를 학습하기 때문에 Correlation이 낮으며 Data Diversity를 보장할 수 있어 Agent가 Local Optimal에 빠지는 것을 막아준다. 하지만 현재 정책을 평가하지 않는다. 또한 재활용이 가능하다는 점에서 Sample-Efficient를 높인 것이지 대부분의 데이터가 학습에 큰 도움을 주지 못하기 때문에 Random Sampling 만으로는 Sample-Efficient를 높이지 못한다.
그래서 데이터에 우선순위를 매겨 우선순위가 높은 데이터부터 학습 시키는 Prioritized Experience Replay 방법이 고안 되었다.
처음 소개된 방식은 TD-Error가 높은 데이터에 높은 우선순위를 매기는 방식이었으나 이후 Episodic Reward가 높은 데이터에 우선순위를 매기는 방식까지 추가 되었다.
이 연구는 Episodic Reward를 기반으로한 Prioritized Experience Replay 을 사용하면서 Prioritized Experience Replay에 의해 발생하는 Over-fitting을 해결하는 방법을 소개한다.
SAC
SAC 알고리즘은 Expected Reward를 최대화 하는 것을 목적으로 하는 기존의 Actor-Critic에서 발전해 Trade off between Expected Reward and Entropy를 최대화하는 것을 목표로 하는데 Entropy는 Agent가 Exploration을 하도록 강조한다.
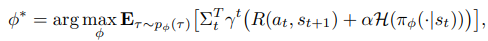
즉 Agent는 Expected Reward를 최대화 하거나 Exploration을 통해 Entropy를 최대화 해야 한다. Exploration을 얼마나 중요시하는 지는 가 결정한다. (Temperature이라고 한다)
SAC는 학습의 안정성을 위해 2개의 Q-function을 구성하고 2개의 Q-function의 Target Network까지 포함 총 4개의 신경망으로 학습한다.
Temperature 은 Static일 수 있지만 학습이 가능한 Parameter다.
- Psuedocode

Improved Soft Actor Critic: SAC + SDP + MO/O
Architecture
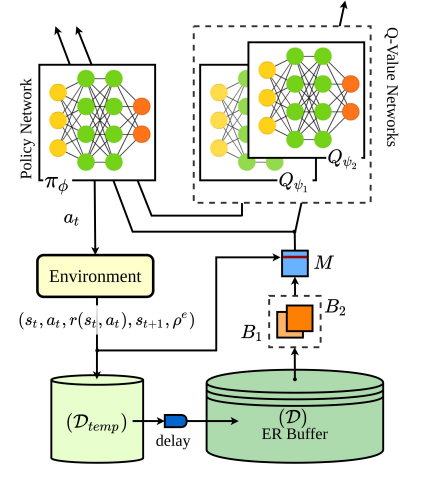
Sampled Data Prioritization (SDP)
기존 Prioritized Replay Experience 는 우선순위를 뒀기 때문에 Sample Bias에 빠져 Sample-Diversity를 감소시켜 Over-fitting을 발생시킬 가능성이 있다.
이 연구에서는 우선 기존의 transition format 을 확장하여 로 구성하였다 p는 에서 Episode의 Terminal까지의 Episodic-Reward 값이다.
우선, Uniformly Sampling으로 2개의 Batch를 구성한 후 Episodic-Reward 가 가장 큰 순서로 Batch를 다시 구성한다.

엄밀하게 정의하면
k sized의 미니 배치를 2개 를 구성한다고 가정하자.
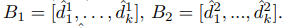
2개의 미니 배치에서 새롭게 구성한 배치를
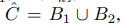 라고 가정하자
라고 가정하자

하지만 Buffer의 사이즈가 작다면(초기에) 두 Batch가 유사한 데이터일 가능성이 높다. 또한 시간이 지나며 유사한 데이터가 많이 생산되는데 이런 경우는 섞어서 뽑는 것 보다는 아무거나 하나 선택하는 것이 계산 효율적이다. 그래서 특정 값을 넘기는 유사도에서는 섞는 것이 아니라 두 Batch 중 하나를 선택한다. 실험에서는 특정 값을 0.5로 설정했을 때 가장 좋은 결과가 나온다는 것을 보여준다.
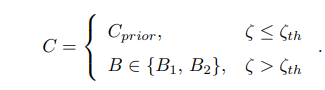
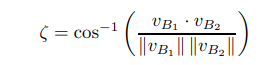
유사도는 Cosine Similarity로 계산되고 각 Vector들은 Batch를 구성하는 Transition 들의 Priority Score이다.
핵심: 처음 Sampling을 Uniformly하게 진행했기 때문에 Episodic-Reward를 기반으로한 Prioritized Sampling임에도 Data-Diversity를 유지했고 그로부터 Over-fitting이 발생할 가능성을 낮출 수 있다.
Mixing on/off policy Experiences (MO/O)
On-policy의 방법을 사용하기 위해 Prioritized 로 재구성된 Batch에 가장 최근에 만들어진 Transition을 첨가한다.

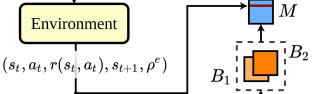
Delayed Infusion of Recent Experiences
Mixing on/off policy Experiences에서 첨가되는 Data는 Replay Buffer에 들어가지 않은 데이터다 이유는 Uniformly Sampling을 하여 Batch를 구성하는 과정에서 똑같은 데이터가 들어갈 수 있기 때문에 Sample-Efficient를 위해 Parameter Updating이 한번 이루어진 후에 ER Buffer에 들어간다.
Experiment and Result
- Best SDP Threshold
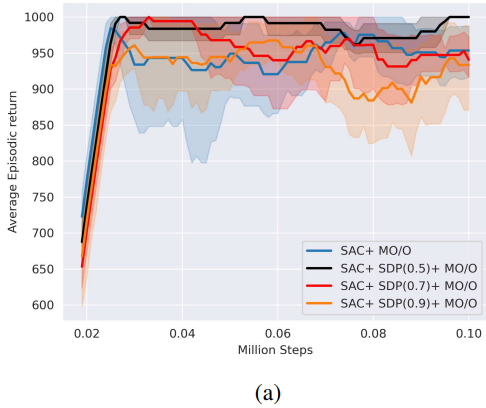
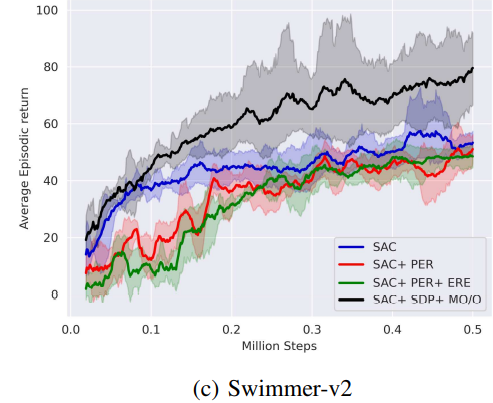
- Comparison with other Algorithms
Conclusion
정리하자면 기존 Prioritized Experience Replay가 가진 Overfitting 문제를 해결하고 On-Policy 기법까지 이용하기 위해
- Uniformly sampling으로 2개의 Batch를 구성
- Episodic Reward를 기반으로 Prioritized Batch를 구성(Sampled data prioritization)
- Prioritized Batch 안에 Latest Data를 삽입 (Mixing on/off policy experiences)
- 최근 데이터는 학습후 리플레이 버퍼에 보관 ( Delayed infusion of recent experiences)
을 사용하였고 이를 통해 Sample-Efficient를 높이는 연구였다.
