강화학습 시리즈는 패스트캠퍼스 박준영 강사님의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.
Preview
우리는 이전 시간에 상태 천이 확률 함수 없이도 가치를 추정하는 방법에 대해서 알아 보았다.
환경에 대한 지식을 알 때 Policy Evaluation
환경에 대한 지식을 모를 때 Policy Evaluation
- Monte Carlo (Incremental)
- TD Difference (Incremental)
Monte Carlo 방식은 다양한 길이의 EPisode를 통해 계산한 Episodic Reward 를 가지고 를 추정하기 때문에 편향이 거의 없다. 하지만 Episode 길이에 차이가 있어 분산이 커 정확한 에 수렴하기 위해서는 많은 시뮬레이션을 돌려야 한다.
TD 방식은 Episode가 끝나지 않더라도 Transition을 가지고 가치를 지속적으로 갱신 최적 가치 함수를 추정할 수 있으나 사용하는 Episode 길이가 너무 짧아 Bias가 존재해 Local Optima에 빠질 우려가 있다. 하지만 분산은 Monte Carlo보다 상대적으로 작으며 Local Optima에 빠질 가능성은 있지만 빠르게 괜찮은 가치 함수를 얻을 수 있다.
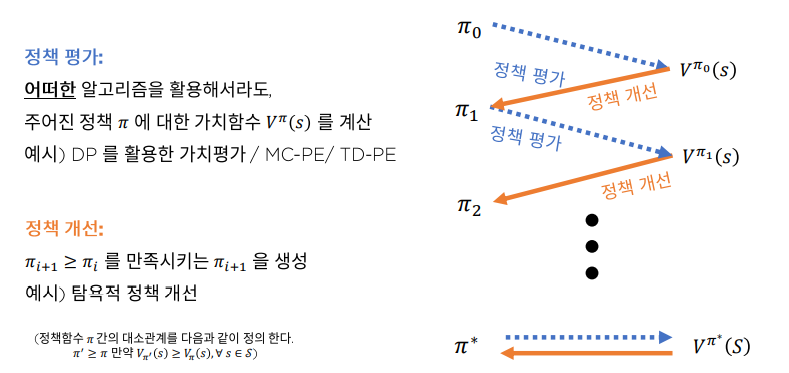
Generalized Policy Iteration
Dynamic Programming의 Policy Iteration에서는 정책 평가 와 정책 개선 을 이용하여 최적 가치함수와 최적 정책을 추정해 나갔다.
Generalized Policy Iteration에서는
정책 평가를 MC,TD를 이용하였다.
이제 정책 개선을 어떻게 하는지에 대해서 알아보자.
Greedy Policy Improvements
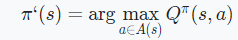
Epsilon Greedy
Background
강화학습은 전통적인 Greedy-Algorithm의 문제점을 해소하기 위해서 만들어 졌다. Greedy-Algorithm은 쉽게 말해 지금 상태에서 최선의 선택을 하는 것을 말하는데 강화학습에서는 이것을 Exploitation이라고 한다.
하지만 정책 평가 부분에서 우리가 배웠듯이 최적 가치 함수로 수렴하기 위해서는 편향없는 다양한 Data가 필요하다. (Data-Diversity가 중요) 그런데 지금 Agent의 정책에서 가장 최선의 선택만을 한다면 Data에 편향이 생겨 Local-Optima에 빠질 가능성이 있다.
이것을 해결하기 위해 Agent에게 지금 정책으로 최선이 아닌 선택을 강요하는데 이것을 Exploration이라고 하며 지금까지 강화학습에서 활발하게 연구되고 있는 주제이다.
이 시간에는 Exploration을 주기위해 전통적으로 그리고 지금도 많이 사용되고 있는 epsilon greedy에 대해서 알아보자
정의
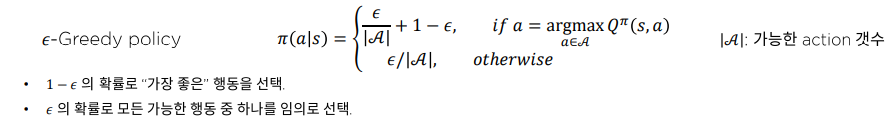
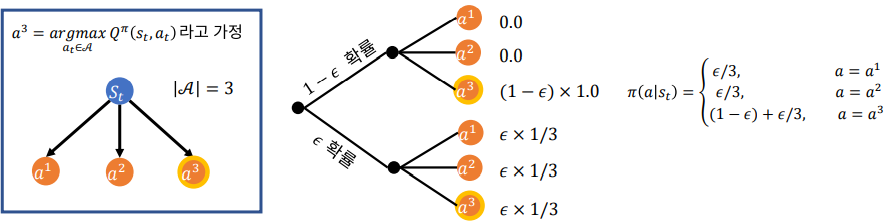
개발자가 값을 정해주고 Agent가 행동을 선택하기 전에 임의의 난수를 만들도록 한다. 만약 만들어진 난수가 보다 작다면 Exploration을 하도록 명령하는데 지금 정책에서 만들어진 (s,a)의 Q값중에 제일 큰 값을 고르는 게 아니라 임의로 선택하게 하는 것이다. 반면 보다 큰 값이 나오면 기존에 Greedy-Algorithm 처럼 Exploitation을 하도록 명령한다.
Monte-Carlo + GLIEEpsilon Greedy
이제 정책 평가으로 Monte Carlo 정책 개선으로 를 이용해 Generalized Policy Iteration을 할 수 있다.
그런데 값은 고정할 수도 있지만 보통 훈련 초기에 높은 값을 설정하고 훈련을 지속하면서 그 값을 점차 줄여나가 후반에는 거의 0으로 만든다. 이 방법을 GLIE(Greedy in the Limit of Infinite Exploration)-greedy 라고 한다.
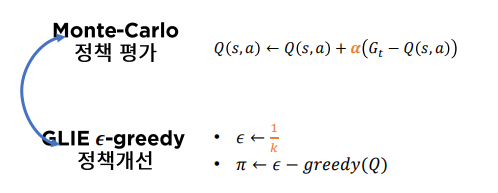
잘보면 값을 적절하게 정하는 것이 중요한 문제라는 것을 눈치 빠른 독자들은 알아챘을 거라고 생각한다. 이런 것들을 Hyper Parameter라고 하며 고도화된 강화학습일수록 사람이 정해줘야 하는 Hyper Parameter 수가 많아진다. 그래서 강화학습은 하이퍼 파라미터와의 싸움이라고도 부른다.
SARSA
SARSA 방식은 TD 방식을 통해 V가 아닌 Q를 갱신 추정해 나가는 Policy Evalutation 알고리즘이다.
Definition
- TD V
- SARSA
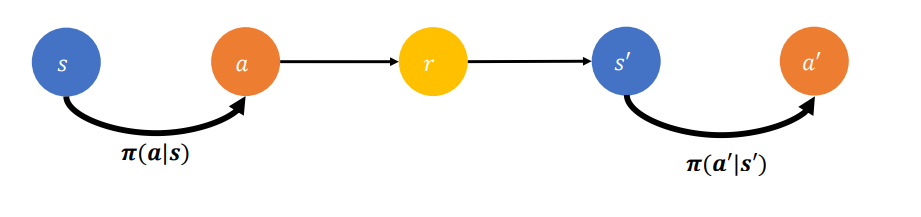
가치 함수 추정에 s,a,r,s,a가 필요하기 때문에 SARSA 알고리즘이라고 부른다.
Pseudocode

SARSA Control
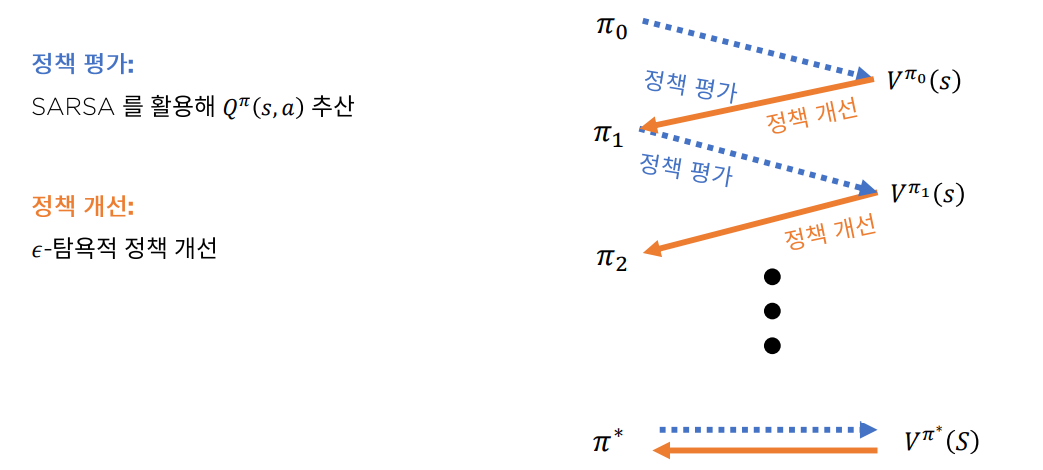
SARSA Control은 정책 평가로 SARSA 정책 개선으로 greedy를 사용한 Generalized Policy Iteration이다.
Conclusion
우리는 이전 시간과 오늘 시간까지해서 환경을 몰라 Dynamic Programming을 사용하여 가치 함수를 추정할 수 없는 상황에서 Generalized Policy Iteration을 어떻게 해야 하는지에 대하여 알아 보았다.
Generalized Policy Iteration을 정책 평가와 정책 개선으로 이루어져 있는데 정책 평가는 개선된 정책으로 정책 값을 수정 정책 개선은 개선된 가치 함수값으로 정책을 수정하는 과정이다.
정책 평가로 Monte-Carlo 방식과 TD 방식을 사용하고
정책 개선으로 greedy를 사용한다.
Generalized Policy Iteration은 크게
- Monte-Carlo 와 greedy을 조합하는 방법
- SARSA(TD) 와 greedy 을 조합하는 SARSA Control로 나뉜다.
Monte-Carlo와 SARSA의 가치 추정방식 모두 Stochastic Approximation 정리에 의해 적당히 작은 값을 설정하면 최적 가치 함수로 수렴하는 것이 보장 된다.
