SIFT (Scale-Invariant-Feature Transform)
이미지의 scale(크기), Rotation(회전)에 불변하는 특징점을 추출하는 알고리즘이다. 이런 것들에 불변하는 특징을 추출하는 것은 이후 두 이미지에 대한 [R|T] Matrix를 구하는데 활용될 수 있다.
SIFT 알고리즘은 크게 아래 4가지 과정으로 요약할 수 있다.
(1) Scale-space extrema detection (이미지의 크기를 변화시켜 극대점, 극소점 detection -> keypoint candidates 찾음)
(2) Keypoint localization (feature matching 시 불안정할 keypoint 제거 및 keypoint를 정확하게 위치시킴)
(3) Orientation assignment (각 keypoint들의 direction, magnitude등의 orientation 결정)
(4) Keypoint descriptor (keypoint를 표현하기 위한 descriptor 생성)
(1)로 인해 scale-invariance(이미지 크기변화에 무관하게 같은 keypoint 추출)한 성질을 가지게 되고, (3)로부터 계산한 keypoint의 orientation을 (4)에서 구한 keypoint descriptor에서 빼주면 rotation-invariance(이미지 회전에 무관하게 같은 keypoint 추출) 성질을 갖게된다.
Scale-space extrema detection
우리는 이 과정을 통해 Sclae-Invariant한 Feature을 추출할 수 있다.
scale-space 만들기
Scale invariant하다는 것을 직관적으로 이해해보자. 아파트를 100m 200m 300m 400m 500m 거리에서 관찰한다고 가정하자. 그러면 여기서 아파트의 모서리는 거리에 상관없이 모서리일 것이다. 이때 (100~500m 거리에 한해서) 모서리는 scale(거리와 scale은 비례하다.) invariant하다. 모서리라는 성질이 scale에 따라 변화지 않기 때문이다.
이처럼 scale invariant한 Feature은 다양한 scale에서도 scale invariant해야 한다. 그래서 Scale-Space를 통해 Scale-Invariant한 특징을 추출한다.
scale-space는 original 이미지의 scale을 변화시켜 여러 scale의 이미지를 모아놓는 집합체이다. 그러면 하나의 이미지를 가지고 어떻게 다양한 scale의 이미지들을 만들까? (현재 우리는 original 사진 딱 1장만 있다!!)
아까의 예시로 돌아가보자 만약 100m 거리에서 한 아파트를 본다면 그 아파트의 detail까지 볼 수 있을 것이다. 하지만 500m 이상부터는 detail이 많이 사라진다. scale이 높아질수록 detail이 blur 된다.

신호처리 관점에서는 Image에 Gaussian filter를 convolution한 것과 scale을 키우는 것은 완전히 동일한 과정이다.
즉 한 이미지에서 여러 scale의 이미지를 얻고 싶다면 다양한 scale(sigma)의 Gaussian Filter를 Convolution하면 해결된다!!

점차적으로 블러된 이미지를 얻기 위해 에 상수 k를 계속 곱해서 Convolution한다. 이때 가 2배가 될때까지 만들어진 사진들은 한 Octave로 묻고 그 다음 이미지를 1/2로 Downsampling한 다음 다시 에 상수 k를 계속 곱해서 Convolution한다. 가 2배가 되었을 때 Downsampling하는 이유는 무엇일까? 연산량을 줄이기 위함이다. 가 2배가 되었다는 것의 의미는 우리가 이미지를 2배 먼 거리에서 본 것과 동치이다. 그러므로 이미지 크기를 1/2로 줄여도 상관없으며 동시에 연산량이 줄어드는 이점을 얻는다.
Dog(Difference of Gaussian)
지금까지 다양한 scale값으로 Gaussian 연산처리된 4 그룹의 옥타브, 총 20장의 이미지를 얻었다. 이제 Laplacian of Gaussian(LoG)를 사용하면 이미지 내에서 흥미로운 점들 즉 Keypoint들을 추출할 수 있다. (Edge,Corner)
하지만 LoG는 많은 연산을 요구하기 때문에, 비교적 간단하면서도 비슷한 성능을 낼 수 있는 Difference of Gaussian (DoG)를 사용한다. LoG, DoG 모두 이미지에서 엣지 정보, 코너 정보를 도출할 때 널리 사용되는 방법이다. DoG는 전 단계에서 얻은 같은 옥타브 내에서 인접한 두 개의 블러 이미지들끼리 빼주면 된다.
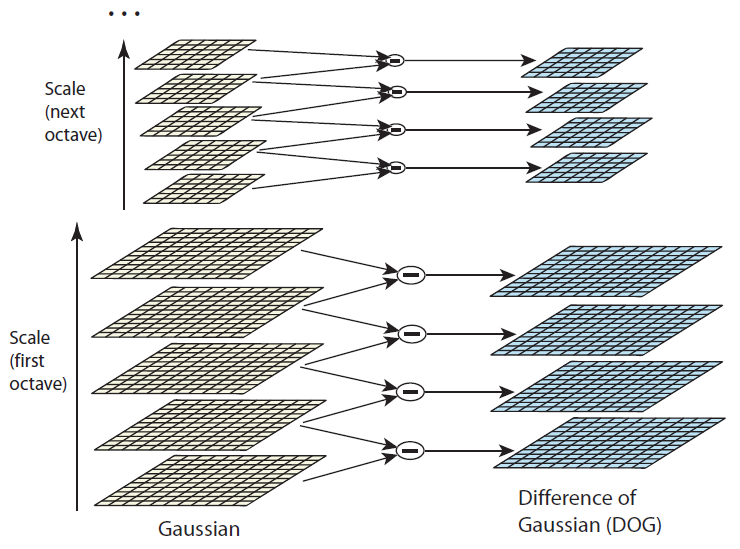
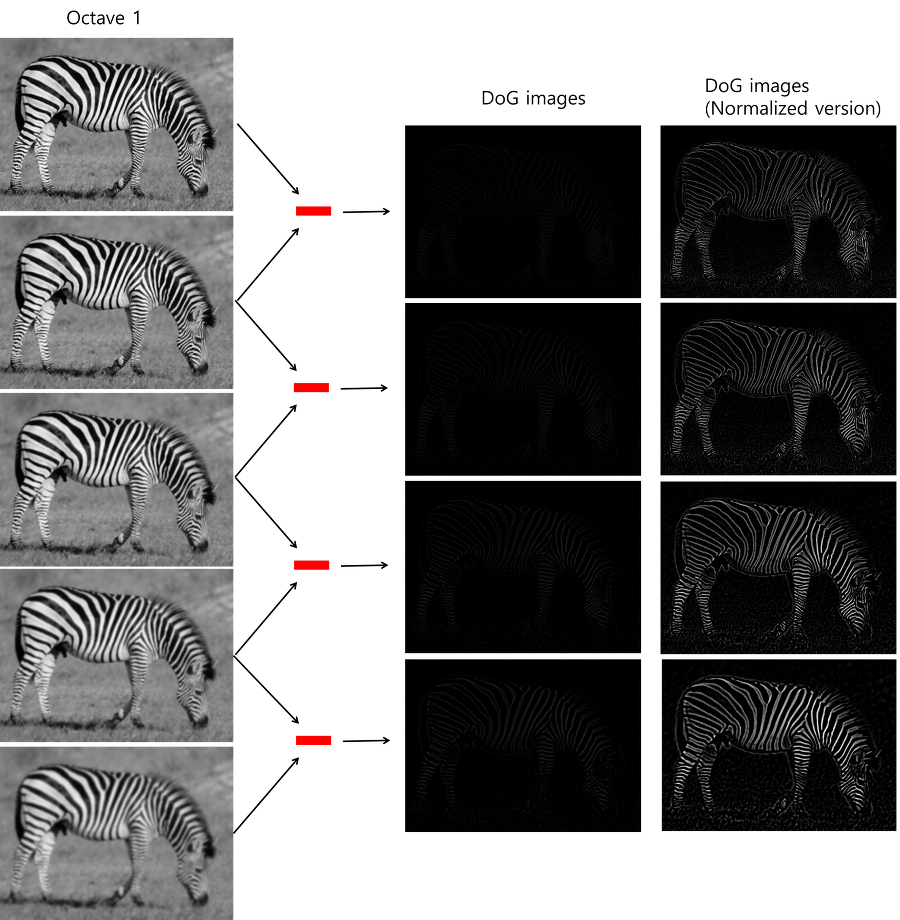
결과적으로 16장의 DoG이미지를 얻게 된다.
Keypoint Localization
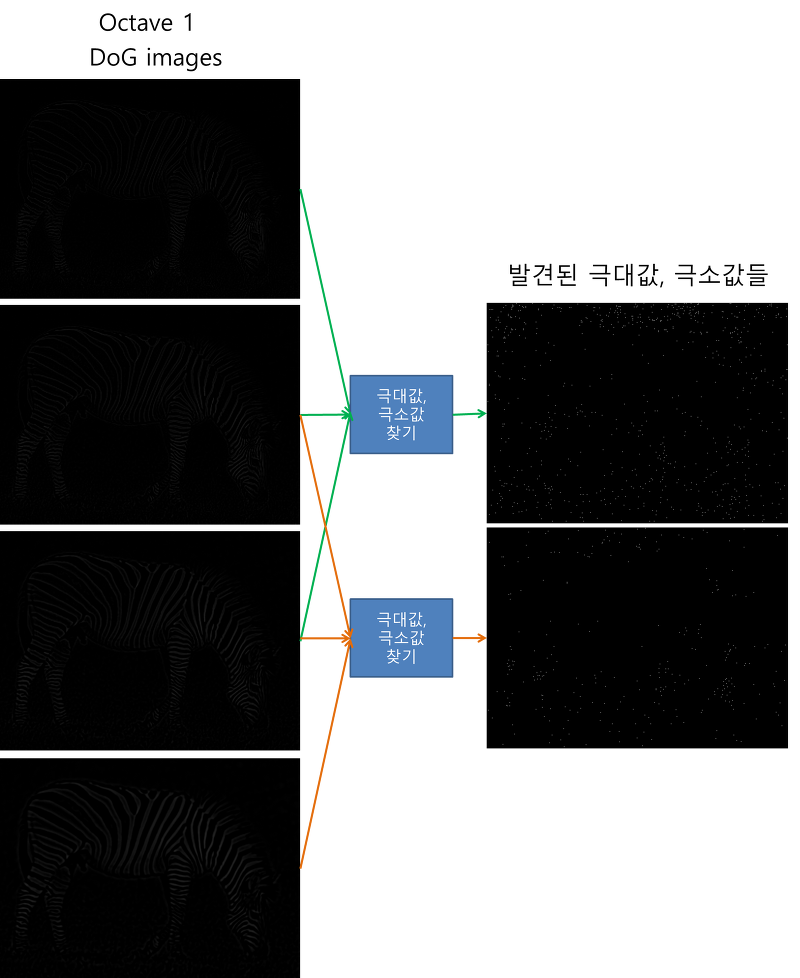
16장의 DoG이미지들에서 keypoint들을 찾아야 한다. 먼저 DoG이미지들 내에서 극대값,극소값들의 대략적인 위치를 찾는다. (Pixel이기 때문에 대략적이라고 표현한다.)
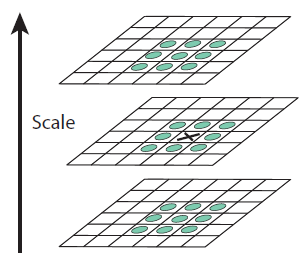
SIFT 알고리즘에서 극대값,극소값의 대략적인 위치를 찾는 아이디어는 내 주변 8개 내 위아래 9개 총 26개 픽셀보다 Value가 크거나 작으면 극값이다.
이 과정을 통해 Octave별로 2장씩 총 8장의 이미지가 만들어진다.
지금까지 찾은 것은 픽섹을 통해 대략적으로 찾은 극대,극소값이다. 아래의 수식은 DoG 이미지에 대한 테일러급수를 나타낸다. D는 DoG 이미지를 나타내고, X는 (x, y, standard deviation)을 의미한다. 아래의 식을 X에 대해 미분해서 0이 되는 지점이 극값이 된다.
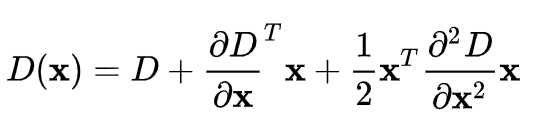
Bad Keypoint 제거
나쁜 keypoint를 제거하기 위해 keypoint 중에서 특정 threshold보다 낮은 keypoint를 제거하고 edge위에 위치한 noise keypoint들 또한 제거하여 코너에 위치한 keypoint들만 남겨놓는다.
의문점1
"잠깐 corner만 남으면 corner detection를 그냥 바로 쓰면 되지 않음?" 아 그럴 수 있다. 하지만 거리에 따라 corner로 보일수도 아닐 수도 있는 점들이 있다. 만약 다른 거리 다른 시점에 찍은 사진 2개를 Feature Matching한다고 가정하자. 우리는 2개의 사진이 찍힌 거리를 모르기 때문에 Scale Invariant한 특징을 뽑아야하는데 그러기 위해서는 Scale Space을 만들고 거기서 특징점을 추출해야 한다. 거기서 뽑혀진 특징은 Scale Invariant하여 신뢰할 수 있다.
이 과정을 통해 우리는 Sclae Invariant한 특징을 추출하였고 여기에 Rotation Invariant한 성질까지 만족하여야 우리가 원하는 특징점을 추출할 수 있다.
의문점2
Down Sampling해서 뽑은 극값들의 좌표는 original하고는 좀 안 맞지 않을까?
맞다 그래서 비례하게 키우면 된다. (간단하쥬?)
Rotation Invariant
Rotation Invariant하다는 것은 무슨 의미일까? 이미지를 예를 들면, 사진을 어떻게 뒤집든 그 점이 여기에 있다는 것을 특징할 수 있어야 한다. 좀더 수학적으로 설명하면 Rotation에도 불변한 정보를 가지고 있으면 된다.
이 정보를 만들기 위해 먼저 keypoint의 Gradient를 구하고(Orientation Assignment) 그 다음 Keypoint 주변 픽셀들의 Gradient를 구한다음 주변 픽셀들의 Gradient에서 Keypoint Gradient를 빼준다. 이렇게 만들어진 정보를 나열한 Vector을 Keypoint Descriptor라고 한다.
Keypoint의 Gradient와 주변 Pixel의 Gradient는 이미지의 Rotation에 따라 값이 변한다. 다만 변하지 않는 것은 주변 Pixel과 Keypoint의 상대적인 방향이다. 우리는 상대적인 Gradient값으로 Descriptor을 만들 수 있고 이 Descriptor는 Rotation에 대해 Invariant하다. (우리가 찾는 Rotation Invariant한 정보!!)
Orientation Assignment
Keypoint의 방향을 할당해주는 과정이다. Keypoint 주변으로 아래의 두 식을 이용해 Keypoint 주변 gradient의 크기 및 방향을 알아낸다.
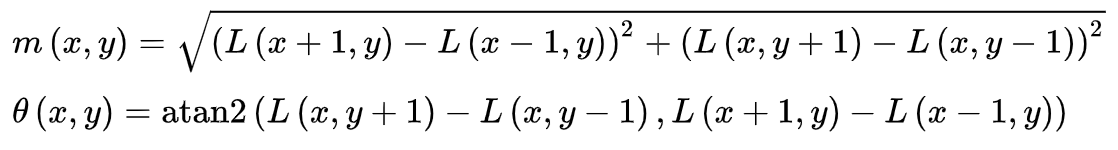

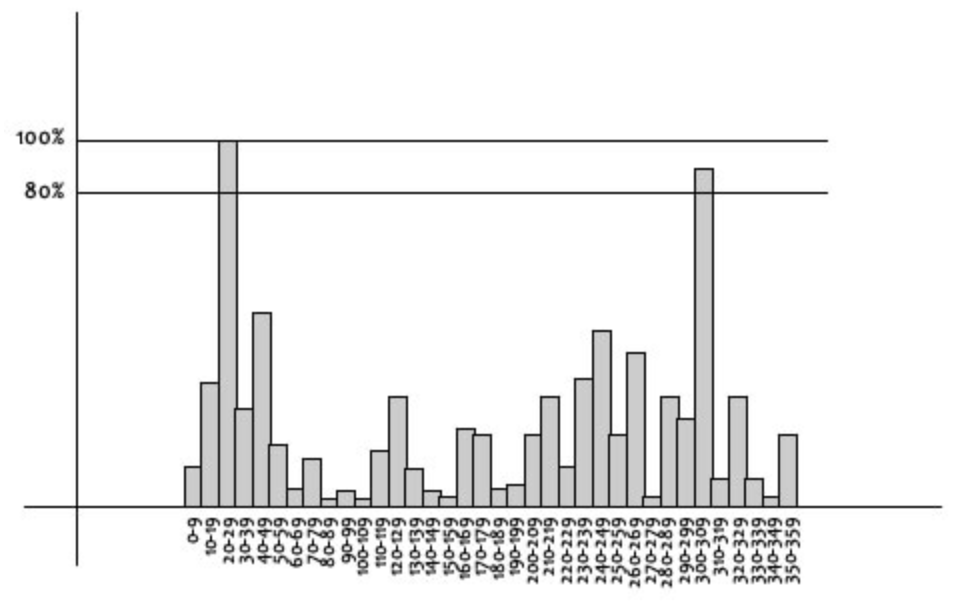
Gradient의 크기와 방향을 구하고 아래와 같이 가로축이 방향, 세로축이 크기인 Histogram을 그린다. 아래의 Histogram에서 가장 큰 값을 가지는 방향(각도)을 keypoint의 방향으로 설정한다. 만약 가장 큰 keypoint 방향의 80%보다 큰 각도가 존재한다면, 그 각도도 keypoint의 orientation으로 설정한다.
Keypoint Descriptor
이제 Keypoint들을 식별할 수 있는 fingerprint(지문)과 같은 Descriptor을 만들면 된다.
아래의 그림처럼 keypoint를 중심으로 16x16 크기의 윈도우를 세팅하고, 이 윈도우를 4x4의 크기를 가진 16개의 작은 윈도우로 구성한다.
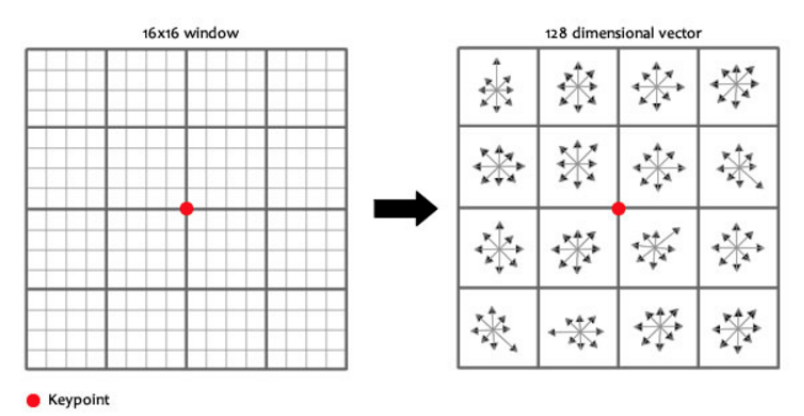
16개의 작은 윈도우에 속한 pixel들의 gradient의 크기와 방향을 계산한다. 그리고 8개의 bin을 가진 Histogram을 그린다. 이전과 마찬가지의 방법을 사용하였지만 bin의 수만 8개로 세팅을 하였다. 결국 16개의 윈도우에 8개의 방향으로 세팅이 되었기 때문에 16x8=128 개의 숫자(feature vector)를 가진 descriptor를 만들 수 있다.
이미지가 회전하면 모든 gradient의 방향이 바뀌기 때문에 feature vector도 변하게 됩니다. 즉, 회전한 이미지에서 같은 keypoint에 대한 feature vector를 보더라도 회전된 만큼 feature vector가 변했기 때문에, 회전된 이미지에서는 feature vector만 보고서 같은 keypoint 인지 알 수 없다. 따라서 회전된 이미지에서도 feature vector가 변하지 않도록 하기 위해 16개 각각의 4x4윈도우에서 keypoint의 방향을 빼준다. 그러면 각 16개의 윈도우의 방향은 keypoint의 상대적인 방향이 되므로 원래의 이미지에서의 keypoint와 회전된 이미지에서의 keypoint는 같게 된다.
정리
SIFT 알고리즘을 쓰는 이유에 대해서 명확하게 하자 Scaling과 Rotation에 불변한 특징점을 추출하기 위함이다.
먼저 Scale-Invariant한 특징점을 뽑기 위해 다양한 Scale의 짒합체인 Scale-Space을 만들었고 거기서 일련의 과정을 거쳐 극값을 추출하였다. 여기서 추출한 특징점들은 Scale-Invariant하다.
그 다음 이 특징점에 Rotation-Invariant한 정보를 줘야한다. Rotation-Invariant하다는 것은 사진을 어떻게 뒤집든 이 점이 어디에 있는지 특징할 수 있어야 한다는 것이다. 이를 위해 Keypoint의 Gradient를 구하고 주변 16개의 작은 윈도우에 대해 Histogram을 만들었다. Histogram에서 Keypoint의 gradient를 빼서 16X8 크기의 Rotation Invariant한 Keypoint Descriptor를 만든다.
이 두 과정을 거치면 우리는 Scale과 Rotation에 Invariant한 특징점을 추출할 수 있다.
