강화학습 논문 리뷰
1.Hierarchical Object Detection with Deep Reinforcement Learning
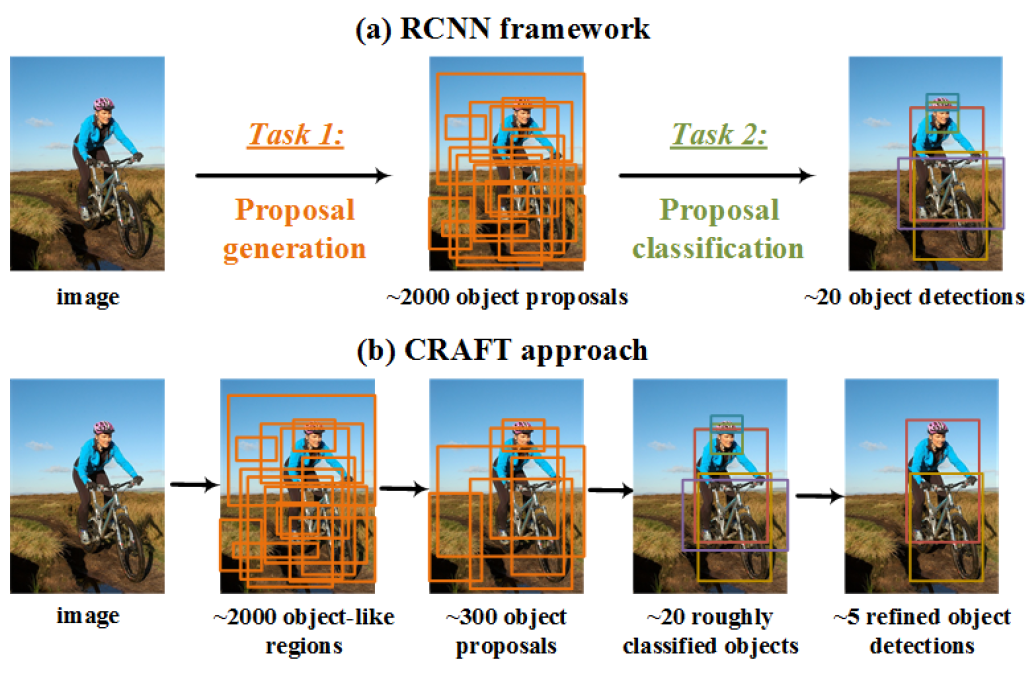
논문 출처: https://arxiv.org/abs/1611.03718Object Detection 의 R-CNN 계열의 알고리즘은 바로 물체를 찾는 것이 아니라 Region Proposal 과정이 선행된다.하지만 이 과정에서 Computational Cost
2.Active Object Detection Using Double DQN and Prioritized Experience Replay - 논문 리뷰
논문 출처: https://ieeexplore.ieee.org/document/8489296이 논문은 Deep Reinforcement Learning을 통해 효율적인 Active Object Detection을 할 수 있는 알고리즘을 제시한다.What is
3.PRIORITIZED EXPERIENCE REPLAY - 논문 리뷰

논문 출처: https://arxiv.org/abs/1511.05952DQN의 목표는 신경망이 최적 Q함수에 근사하는 것이다. 하지만 최적 Q함수 $Q^\*$ 을 표현하는 방법이 없기 때문에 벨만 방정식을 이용해 Target-Q(최적 Q함수)를 표현하고 Q-n
4.Asynchronous Episodic Deep Deterministic Policy Gradient: Towards Continuous control in Computationally Complex Environments -논문 리뷰
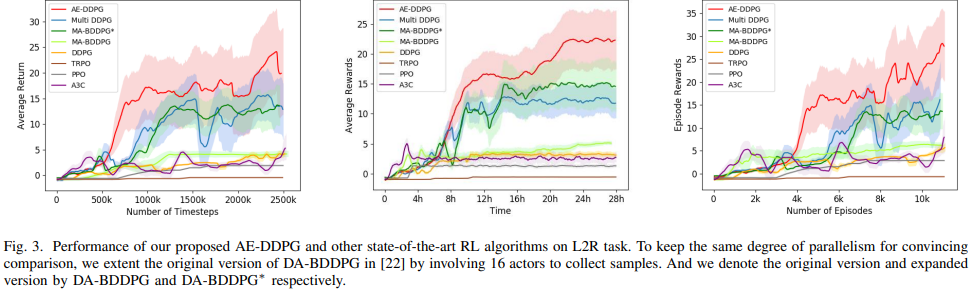
논문 출처: https://arxiv.org/abs/1903.00827오늘은 이전에 소개한 Prioritized-Experience-Replay 처럼 Sample에 우선순위를 두어 Data-Efficient 를 높인 논문을 소개하겠다.Prioritized-Ex
5.Improved Soft Actor-Critic: Mixing Prioritized Off-Policy Samples with On-Policy Experience -논문 리뷰
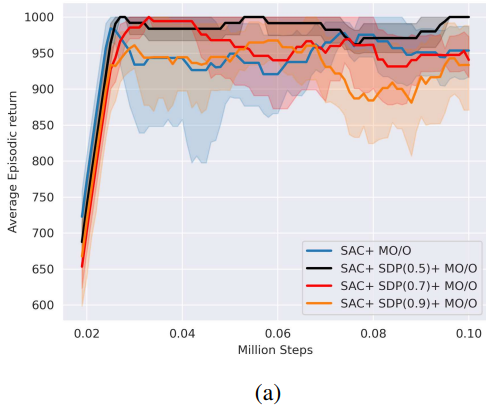
논문 출처: https://arxiv.org/abs/2109.11767https://velog.io/@everyman123/PRIORITIZED-EXPERIENCE-REPLAY-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0http
6.Maximum Entropy Reinforced Single Object Visual Tracking

기존 강화학습을 이용한 Visual Tracking 알고리즘들은 Exploration 전략이 부족해 Local Optimal(non-target detection)에 빠지는 경우가 많았고 이것을 극복하지 못했다. 이 연구에서는 Exploration을 Entropy로 정
7.Actor-Critic Instance Segmentation - 논문 리뷰
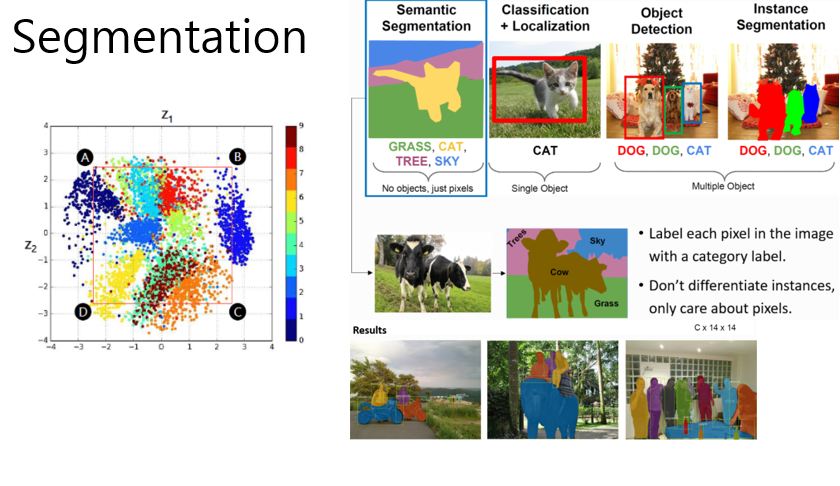
논문 출처: https://ieeexplore.ieee.org/document/8954189이번에는 강화학습 알고리즘 중에 하나인 Actor-Critic의 DDPG 알고리즘을 이용해 Segmentation의 끝판왕인 Instance Segmentation 을
8.Automtic Inside Point Localization with Deep Reinforcement Learning for Interactive Object Segmentation - 논문 리뷰

논문 출처: https://www.mdpi.com/1424-8220/21/18/6100Li G, Zhang G, Qin C. Automatic Inside Point Localization with Deep Reinforcement Learning for In
9.Deep Ensemble Reinforcement Learning with Multiple Deep Deterministic Policy Gradient Algorithm - 논문 리뷰

논문 링크: https://www.semanticscholar.org/paper/Deep-Ensemble-Reinforcement-Learning-with-Multiple-Wu-Li/dcc02065f3f51a6bc4117adc431801e3be8a2362Wu,
10.Ensemble Bootstrapped Deep Deterministic Policy Gradient for vision-based Robotic Grasping -논문 리뷰
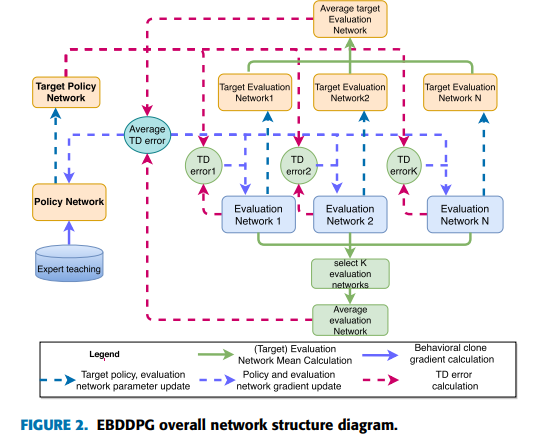
논문 링크
11.논문 리뷰 D2RL: Deep Dense ARCHITECTURE IN REINFORCEMENT LEARNING
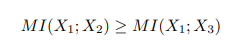
기존 RL에 사용하는 신경망은 단순하게 fully-connected layer를 1~2층으로 연결하는 것으로 구성되었다. 하지만 이런 단순한 구조로 학습한 agent는 복잡하고 연속적인 state , action space 에 대한 exploration 의 한계가 명확