이 글에서는 강화학습에 대한 전반적인 내용을 다룰 예정입니다.
강화학습이란
강화학습(reinforcement learning)은 머신러닝의 한 종류로 어떠한 환경에서 어떠한 행동을 했을 때 보상을 줌으로써 그것이 잘 된 행동인지 잘못된 행동인지를 판단하고 반복을 통해 보상을 최대화하는 방향으로 스스로 학습하게 하는 분야입니다.
강화학습에는 두 가지 구성 요소로 환경(environment)와 에이전트(agent)가 있습니다.
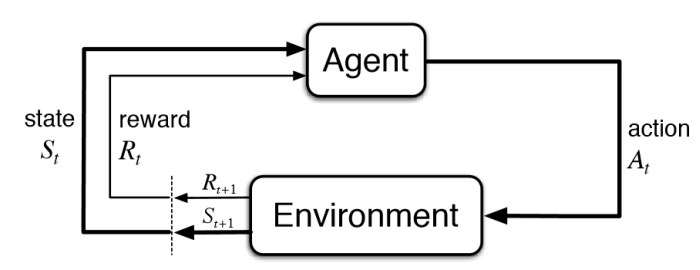
강화학습의 Agent는 MDP(Markov Dicision Process)에서 정의됩니다. 그럼 MDP에 대해서 알아보죠.
마르코프 의사 결정 과정 (MDP)
강화학습은 MDP에 학습의 개념을 넣은 것이라고 할 수 있습니다. 그러므로 MDP에 대해서 이해하는 것은 강화학습을 이해하는 데 있어 매우 중요합니다.
마르코프 가정
마르코프 가정(Markov assumption)이란 어떠한 시점의 상태는 그 시점 바로 이전의 상태에만 영향을 받는다는 가정입니다.현재의 상태가 바로 이전 상태에만 영향을 받는다고 가정하는 것이 어떻게 보면 무리한 가정일 수 있으나 모든 과거를 고려하는 것은 현실적으로 불가능합니다. MDP는 마르코프 가정을 충족합니다.
마르코프 가정은 아래와 같이 정의 됩니다.
마르코프 과정
MDP를 공부하기 전에 간단한 마르코프 과정(Markov Process)부터 살펴 봅시다.
마르코프 과정(Markov Process)은 Markov 가정을 만족하는 연속적인 일련의 확률 과정입니다.
마르코프 과정은 일련의 상태 <>와 상태 전이 확률 (state transition probability) P로 구성된 튜플 입니다.
-
-
상태 전이 확률
상태 전이 확률 는 어떠한 상태가 i일 때 그 다음 상태가 j가 될 확률을 의미합니다.
마르코프 의사 결정 과정
마르코프 의사 결정 과정(Markov decision process)은 마르코프 과정을 기반으로한 의사 결정 모델입니다. 마르코프 과정에 행동 A와 보상 R 그리고 감가율 가 추가된 튜플입니다. MDP를 자세히 정리하면 다음과 같습니다.
- 상태 집합 는 MDP에서 가질 수 있는 모든 상태의 집합을 의미합니다.
- 행동 집합 은 행동 주체인 에이전트가 할 수 있는 모든 행동의 집합을 의미합니다.
- 상태 전이 확률
는 어떠한 상태 s에서 행동 a를 취했을 때 상태 으로 변할 확률을 의미합니다. - 보상 함수는 에이전트가 어떠한 상태에서 취한 행동에 대한 보상을 내리기 위한 함수이다. 특정 상태 에서 라는 행동을 취했을 때 환경(environment)는 에이전트에게 보상을 줍니다.
MDP는 MP와는 다르게 의사 결정 과정이 추가되므로 에이전트는 어떤 상태에 대해서 행동을 결정해야 합니다.
-
에이전트는 어떻한 상태 에서 수행할 행동 a를 정해야 하는데, 이를 정책(policy)라고 한다. 정책은 다음과 같이 정의됩니다.
-
강화학습은 시행착오를 겪으며 보상을 최대화하는 방향으로 정책을 학습하는 것입니다. 행동의 좋고 나쁨은 episode에서 받은 보상의 합으로 결정 되는데 이것을 return값 로 정의합니다. 이때 episode에서 얻은 시간이 다른 보상의 가중치를 결정하는 것이 감가율 return은 엄밀히 말하면 보상의 가중치 합입니다.
(T는 Terminal)
감가율은 통상적으로 라고 표기합니다. 0부터 1사이의 값으로 설정을 하며,1에 가까울수록 미래의 보상에 많은 가중치를 두는 것을 의미합니다. 강화학습에서 보상을 최대화한다는 것은 하나의 reward가 아니라 return 를 최대화한다는 의미입니다.
가치 함수
강화학습의 목적은 보상(누적 )을 최대화하도록 정책을 학습하는 것입니다. 즉, 에이전트가 특정 상태에서 보상을 최대화할 수 있는 행동을 선택해야 합니다. 여기서 보상을 최대화할 수 있는 행동이란 현재 상태에서 이동할 수 있는 다음 상태 중 가장 가치가 높은 상태로 이동할 수 있는 행동을 의미합니다. 그러면 가치가 높은 상태는 도데체 무슨 의미인가? 가치가 높은 상태는 그 상태의 return값에 대한 기댓값이 높다는 것을 의미합니다.(가치란 그 상태에서 retrun값에 대한 기댓값) 그리고 강화학습은 이 가치를 수식적으로 표현하기 위해 가치 함수라는 개념을 도입합니다.
가치 함수는 상태 가치 함수(state-value function)와 상태-행동 가치 함수(action-value function)이 있습니다.
상태 가치 함수(state-value function)
위 설명한 개념을 정의한 게 상태 가치 함수입니다.
상태 가치 함수 는 어떤 정책 에서 상태 s일 때 return의 기댓값을 반환하는 함수이다.
그런데 과거를 모르면서 미래를 어떻게 알 수 있지? 좋은 질문입니다. 강화학습은 저 문제를 해결하기 위해 나름의 방법들이 있습니다. 차차 소개할 예정이니 기대하셔도 좋습니다.
상태-행동 가치 함수(action-value function)
상태 가치 함수 가 어떤 상태 s로부터 return의 기댓값을 반환하는 함수라면 상태 행동 가치 함수 는 a라는 조건을 하나 더 붙입니다.
상태-행동 가치 함수 는 어떤 정책 에서 상태가 s이고 행동이 a일 때 return의 기댓값을 반환하는 함수이다.
Bellman 방정식
강화학습은 Bellman Equation으로부터 시작하기 때문에 반드시 이해하고 넘어가야 합니다.
우리는 가치 함수에 대해서 알아 보았습니다. 그런데 실제 computation으로 가치함수를 어떻게 구해야 할까요? 이것을 위해 만들어진 것이 Bellman 방정식이고 Bellman 방정식은 재귀적으로 정의가 됩니다. (좀더 엄밀하게 이야기를 꾸려나갈 수 있지만 큰 틀을 다룬다는 방향에 맞게 간단한 그림으로 이해해 봅시다.) 그럼 Bellman 방정식을 음미해 봅시다.
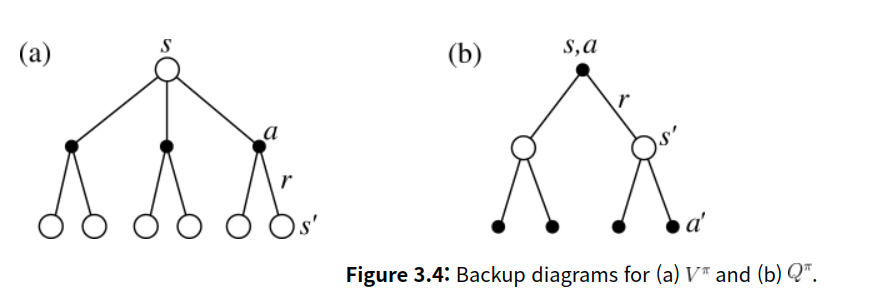
그림 (a)와(b)는 의사 결정 과정을 간단한 이산 diagram으로 표현한 것입니다. root 아래 a는 상태 s에서 에이전트가 선택할 수 있는 모든 행동 a를 의미하고 r은 상태 s,a를 선택했을 때 받게되는 보상을 의미합니다. s,a를 하게 되면 다음 상태로 넘어갑니다.
V (state-value function) 재정의
먼저 그림 (a)에서 상태 s에서 3개의 행동을 취할 수 있습니다. 상태 s에 대한 각각의 a는 상태-행동 가치 함수 로 표현할 수 있습니다. 눈치 빠른 분들이라면 눈치 채셨겠죠? 상태 s에서의 상태 가치 함수 는 s에서 선택할 수 있는 a에 대한 상태-행동 가치 함수 로 표현할 수 있습니다.
이것을 수식으로 표현하면 입니다.
우리는 가 정책함수라는 걸 알고 있습니다. 그래서 다시 정리하면
입니다.
정리: 상태 가치 함수 는 상태 s로 부터 가능한 모든 상태-행동 가치 함수 의 기댓값이다.
Q (action-value function) 재정의
그림 (a)에서 Q를 통해 V를 정의했다면 (b)에서 V를 통해 Q를 정의해 봅시다.
MDP에서는 상태 s에서 행동 a를 한다면 다음 상태 로 넘어간다고 했습니다. 하지만 s에서 a을 취했더라도 다음 상태가 늘 같지 않습니다. 왜냐하면 다음 상태를 확률적으로 정의되기 때문입니다. 우리는 이것을 상태 전이 확률이라고 부릅니다.
- 상태 전이 확률
는 어떠한 상태 s에서 행동 a를 취했을 때 상태 으로 변할 확률을 의미합니다.
그림 (b)는 s에서 a를 취했을 때 가능한 모든 다음 상태를 나타랠 겁니다. 각 다음 상태에서는 마찬가지로 그림 (a)의 과정을 계속할 것이구요. 그림 (b)와 그림 (a)가 서로 맞물려서 반복된다? 이것이 bellman 방정식의 핵심입니다. 이런 관계 덕분에 V는 Q로 Q는 V로 정의할 수 있고 이로부터 V와 Q를 재귀적으로 정의한 bellman 방정식이 유도됩니다.
다시 돌아가서 그럼 Q는 다시 정의해 봅시다. 상태-행동 가치 함수 는 다음 상태부터의 상태 가치 함수들로 표현할 수 있습니다.
개념을 간단하게 하기 위해 보상함수는 s,a일 때 deterministic하게 주어진다고 가정하겠습니다. 그러면 reward r(s,a)는 식 밖으로 빼낼 수 있습니다.
정리: 상태-행동 가치 함수 는 가능한 모든 상태로부터의 상태 가치 함수들의 기댓값이다.
Bellman Equation
이제 V와 Q를 재귀적으로 표현해 봅시다. 만드는 방식을 새로 정의한 V와 Q를 이용하면 됩니다.
이렇게 상태 가치 함수와 상태-행동 가치 함수를 벨만 방정식을 통해 재귀적으로 풀어 봤습니다. DP 방식에서는 이 Bellman Equation을 직접 사용해 학습을 진행합니다.
벨만 최적 방정식(Bellman Optimality equation)
최적의 상태 가치와 최적의 상태-행동 가치를 다음과 같이 표현할 수 있습니다. 최적 가치라는 것의 의미는 가장 큰 보상을 받을 수 있는 정책을 따랐을 때 얻을 수 있는 가치를 뜻합니다. 다시 말하면 어떤 MDP 계에서 가장 큰 보상을 얻을 수 있는 정책을 발견했다면 그 정책으로부터 만들어지는 가치를 최적 가치라고 하며 그 계에서 만들어질 수 있는 모든 정책으로 부터의 가치 중에서 가장 큰 값을 가집니다. 강화학습에서 우리가 찾아야 하는 것은 최적 가치를 만드는 최적 정책인 것이죠
MDP를 위한 DP (Dynamic Programming)
위에서 다룬 벨만 방정식을 이용해 MDP를 푸는 동적 프로그래밍을 알아보겠습니다. 동적 프로그래밍은 재귀적인 최적화 문제를 푸는 방법입니다. 동적 프로그래밍은 상태 천이 확률 를 모두 안다는 가정에서 가능한 방법입니다.
DP는 정책 반복(policy iteration)과 가치 반복(value iteration)으로 이루어져 있습니다.
정책 반복 (Policy Iteration)
정책 반복 (Policy Iteration)은 정책 평가와 정책 개선을 적용해 Bellman 방정식을 푸는 알고리즘이다.
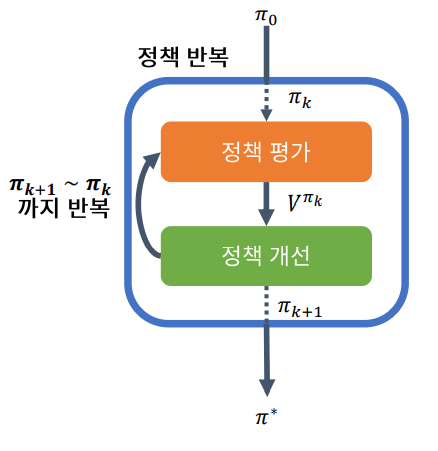
이 루프를 계속 진행하며 정책 평가를 계속 반복하면 V는 최적 가치 에 수렴하고 이것은 바나흐 고정점 정리로 증명 되었습니다.
즉, MDP를 DP를 활용해서 효율적으로 풀 수 있다.
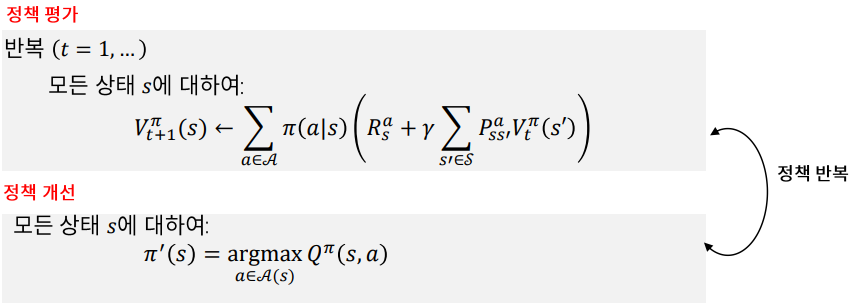
가치 반복 (Value Iteration)
가치 반복은 정책 반복과 유사합니다.
정책 반복에서는 다음 상태의 가치를 정책 함수의 확률과 곱해 모두 더했지만 , 가치 반복에서는 탐욕적으로 가장 큰 다음 가치를 선택합니다.
정책 반복은 정책 평가 정책 개선 2개의 loop를 돌아야 하지만 정책 반복은 1개의 loop를 돌면 되기 때문에 계산 복잡도가 정책 반복보다 낮아 수렴 속도가 더 빠릅니다.

DP의 한계
동적 프로그래밍은 MDP의 상태 전이 확률과 보상 함수가 명확하게 주어져야 하므로 현실적으로 상태 전이 확률과 보상 함수를 미리 알 수 없는 대부분의 real-world problem에는 적용하기 어렵습니다. 그러므로 다른 방법이 필요합니다.
Model-based vs Model-free
real-world에서는 상태 전이 확률과 보상 함수를 알기 어렵습니다. MDP에서 이 상태 전이 확률과 보상 함수를 model이라고 부릅니다.
상태 전이 확률과 보상 함수를 정할 수 있는 경우를 model-based 라고 부르고 그렇지 않은 경우를 model-free라고 부릅니다. 많은 강화학습 알고리즘들은 model-free 알고리즘입니다.
예측(Prediction) 와 제어 (Control)
예측(Prediction)은 에이전트가 주어진 정책에 따라 환경과의 소통을 통해 가치 함수를 학습시키는 것입니다. 우리의 목표는 최적 가치 함수에 수렴할 때까지 가치 함수를 학습시키는 것이죠. 예측의 방법으로는 몬테카를로(Monte-Carlo) 방식과 시간차 예측(temporal-difference) 방식이 있습니다.
제어는 예측을 통해 학습한 가치 함수를 기반으로 정책을 학습시키는 것입니다.
위 두 과정은 예측은 정책 반복에서는 정책 평가 제어는 정책 개선과 유사합니다.
On-policy vs Off-policy
On-policy 는 행동을 결정하는 정책(policy)과 학습할 정책이 같은 것을 말합니다. 다시 말해 On-policy 강화학습은 정책이 업데이트 되면 업데이트에 사용된 데이터를 다시 사용할 수 없습니다.
반대로 Off-policy는 행동하는 정책과 학습하는 정책이 달라도 상관 없습니다. 그러므로 replay-buffer에 데이터를 담고 batch 사이즈만큼 데이터를 가져와 학습시킬 수 있습니다. 데이터 효율 관점에서는 버리지 않아도 되는 Off-policy방식이 더 좋다고 볼 수 있습니다.
가치 추산
가치 함수를 학습하는 것을 예측(prediction)이라고 하였고 MC(Monte-Carlo)와 TD(Temporal-Difference) 방식이 있다고 소개해 드렸습니다. 이제 더 자세히 살펴보죠.
Monte Carlo
가치 함수는 그 정의에서 확인할 수 있듯이 Expectatoin으로 정의됩니다.
(Episode가 끝나는 Terminal까지 지속한다는 의미)
Monte Carlo는 모집단의 확률 밀도 함수를 모를 때 Expectation을 추정하기 위해 사용되는 가장 대표적인 방법이고 최초 방문만 따질 것인가 모든 방문에서 따질 것인가에 따라 또 2가지로 나뉩니다. 말로 하면 와닿지 않으니 예시를 들고 직접 계산하며 Monte Carlo 방식을 이해해 봅시다.
(\gamma=1이라고 가정 계산의 편의를 위해)
First-Visit Monte Carlo Policy Evaluation
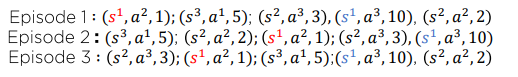
Episode 1:
Episode 2:
Episode 3:
Every-Visit Mlonte Carlo Policy Evaluation
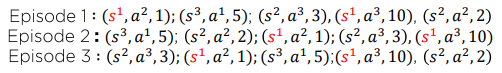
Episode1:
Episode2:
Episode3:
Monte Carlo 방식을 사용한다면 First-Visit Monte Carlo Policy Evaluation 보다는 Every-Visit Mlonte Carlo Policy Evaluation가 풍부한 데이터를 사용하기 때문에 더 많이 사용됩니다.
하지만 고정된 데이터를 가지고 가치를 추정하는 Offline-Learning(위 예시처럼)이 아니라 지속적으로 데이터가 생기는 Online-Learning이라면 위 방식은 매우 비효율적입니다. 값을 모두 저장해야 하기 때문이죠.
배치 산술평균을 온라인 평균기법으로 변환하는 방법을 배워 봅시다.
온라인 평균

기존의 알고 있는 지식을 새로운 관측은 로 보면 됩니다. 이렇게 되면 가치 함수를 갱신하는 데 사용된 G_t는 이제 버려도 되기 때문에 메모리 효율이 증가합니다. 온라인 평균은 확장되어 Incremental MC Policy Evaluation으로 정의됩니다.
Incremental MC Policy Evaluation
- G_t새롭게 알게된 지식
- V(s): 기존에 알고 있는 지식
*: Learning Rate
위 식과 차이점은 이 매우 작은 양수 값로 정의 되었습니다. 실제 RL을 적용할 때 State Space의 크기가 매우 크기 때문에 Learning rate로 대체하였고 "적당히 작은 에 대해서 참값으로 수렴함이 증명 되었습니다" Monte Carlo를 이용한다는 말은 바로 위 식을 이용해 가치함수를 추정해 간다는 말과 동치라고 생각해도 좋습니다.
우리는 Monte Carlo 방식을 활용하여 가치함수를 추정하는 방법에 대해서 알아보았으니 장단점에 대해서 짚고 TD 법으로 넘어갑시다.
장점
- 환경에 대한 지식이 필요 없다.
- 모아서 평균이기 때문에 직관적이다.
- 데이터 수집이 Unbiased하기 때문에 참값에 충분히 많은 시뮬레이션이 보장된다면 수렴한다.
- 문제가 정확한 Markovian이 아니더라도 사용이 가능하다.
단점
- Episode가 끝나야 가능하다.
- 오직 보상 정보만 사용한다.
- 많은 시뮬레이션이 필요하다.
- 편향이 적은 대신 분산이 크다. (강화학습은 조금의 변화가 누적되어 Episode 길이가 길어질 수록 Episode간 분산이 매우 커진다.)
Temporal Difference (TD) 정책 추정
Incrmental MC
MC의 단점은 G_t를 계산하기 위해서는 Episode가 끝나야 한다는 점입니다. 이럴 필요 없이 G_T를 근사시켜 조금의 데이터만 가지고 Value Function을 갱신 추정해 나갈 수 있는 방법을 Temporal Difference 기법이라고 합니다.
Temporal Difference (TD)기법
이것을 TD-Target라고 한다.
를 TD-Error라고 하며
Increnetal MC는 다음과 같은 식으로 다시 정의됩니다.
이제 Episode가 끝나지 않더라도 훈련을 진행하며 지속적으로 가치함수를 갱신할 수 있습니다. 하지만 여기에도 단점이 있는데 그 내용은 MC 와 TD를 전반적으로 비교하는 파트에서 설명하겠습니다.
TD 기법은 MC의 변형으로 Episode가 끝나지 않더라도 계속 훈련이 가능하게 하는 MC의 변형 부분이다. TD의 뿌리는 MC에서 기원한다.
MC vs TD

- MC 기법은 Episode의 Terminal까지 데이터를 수집해서 가치를 추산하기 때문에 편향은 없습니다. 하지만 앞에서 언급한 것처럼 Episode 길이가 클수록 데이터간 분산이 크기 때문에 수렴하기 위해서는 많은 데이터가 필요 합니다. (많은 시뮬레이션 필요)
- TD 기법은 적은 데이터로 가치를 갱신하기 때문에 EPisode 길이가 상대적으로 MC보다 짧아 데이터간 분산이 적습니다. 하지만 많은 데이터를 참고하지 않기 때문에 알고리즘 자체에 Biased를 내재하기 때문에 참값에 수렴한다는 보장이 없습니다. (빠른 속도로 충분히 괜찮은 추정치를 얻을 수 있다.)
정리하자면
MC 기법은 주어진 문제가 정확하게 Markovian이 아니어도 정확한 추산치를 계산할 수 있다. 하지만 효율이 떨어진다.
TD기법은 주어진 문제가 Markovian이 아니면 정확한 추산치를 계산 할 수 없다. 하지만 빠르게 그리고 괜찮은 추산치를 얻을 수 있다.
Graph Visualization
마지막으로 Dynmaic Programming과 MC 그리고 TD가 가치를 추정하는 방식을 시각화하였습니다.
-
Dynamic Programming
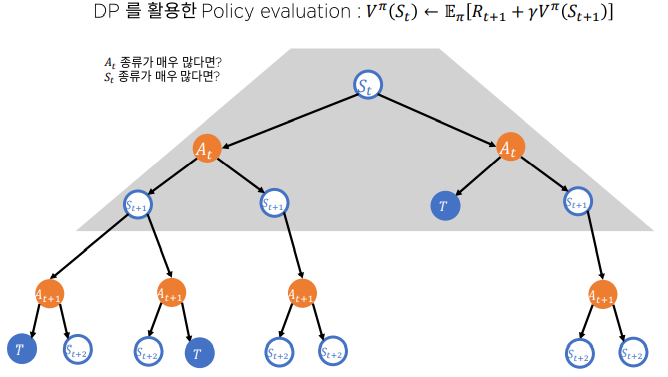
-
Monte Carlo
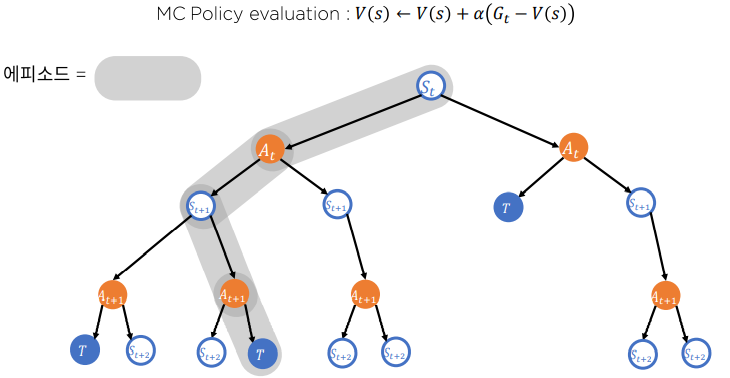
-
Temporal Difference
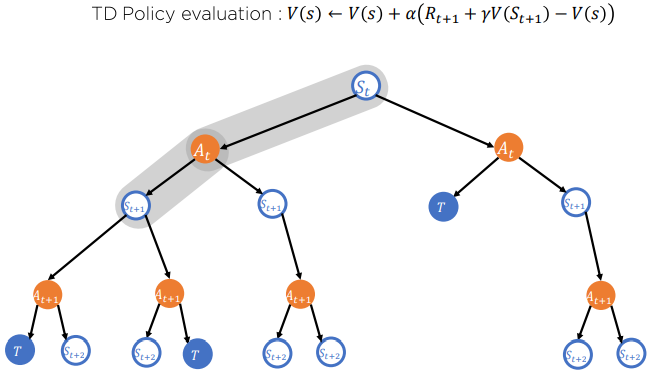
우리는 지금까지 가치를 추정하는 방법에 대하여 알아보았습니다. MDP 환경을 알고 있는 상황에서는 Dynamic Programming을 통해 가치를 추정할 수 있지만 환경에 대하여 모를 때 즉 Model-Free상황에서는 Monte-Carlo 방식과 TD 방식이 사용됩니다.
Monte Carlo
Temporal Differnce
강화학습의 주요 알고리즘
강화학습의 주요 알고리즘에 대해 몇 가지 소개시켜 드리겠습니다. 자세한 설명은 빼고 개괄적으로만 설명할 예정입니다. 궁금하신 분은 관련 알고리즘에 관한 논문을 읽거나 블로그 글을 보시는 걸 추천 드립니다.
Q-Learning 과 DQN
Q-Learning은 TD의 Off-Policy 방식입니다. (가치 함수 추정으로 Temporal Difference를 사용하고 이전 정책으로 만든 데이터를 사용할 수 있다.)
다음 상태 s`에서 가장 큰 Q값을 이용해 Q함수를 갱신합니다. 행동을 결정할 때는 Q값이 높은 행동을 선택하면서도 충분한 탐험을 수행합니다. 탐험은 학습 초기에는 많이 하고 학습 후반으로 갈수록 적게하는 기법을 많이 사용합니다. 이런 방식은 라고 부릅니다.
여기서 Q함수를 심층 신경망으로 정의한 것이 DQN 방식입니다.
SARSA
TD에서 Q함수를 적용하고 탐험을 추가해 제어하면 SARSA(state-action-reward-state-action)가 됩니다.
SARSA는 다음 상태에 대한 행동을 알고 있어야 하기 때문에 행동을 결정하는 정책과 학습 정책을 분리할 수 없으므로 On-policy 방식입니다.
정책 경사(Policy Gradient PG)
정책 경사는 심층 강화학습의 fundamental 한 이론이라고 해도 과언이 아닙니다. 정책 경사를 기반으로 Actor Critic 방식이 나왔기 때문이죠. 정책 경사는 policy를 신경망으로 정의합니다. 딥러닝을 공부한 분이시라면 loss함수를 정의하고 경사 하강법을 통해 loss를 최소화하는 방향으로 model을 최적화하는 딥러닝의 큰 흐름을 알고 계실 겁니다. 하지만 정책 경사는 최소가 아니라 최대화하는 방향으로 경사 상승법을 이용해 정책 신경망을 최적화 합니다. 그럼 무엇을 최대화 하는 것일까요? 기대 누적 보상을 최대화합니다. 그러므로 정책 신경망의 loss 함수는 return의 기댓값으로 정의됩니다.
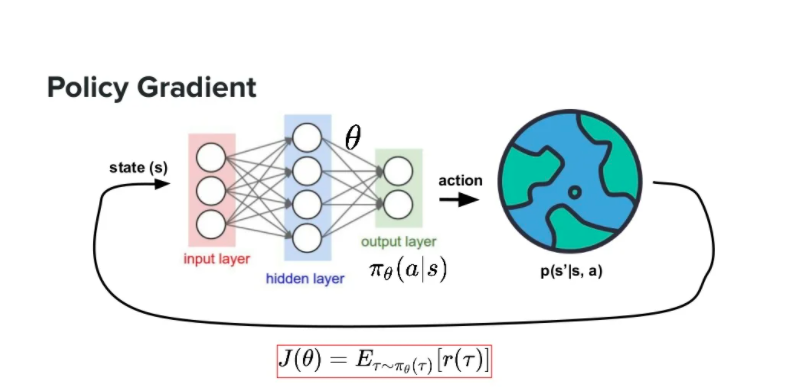
정책 경사를 요약하면 아래 두 식으로 표현할 수 있습니다.
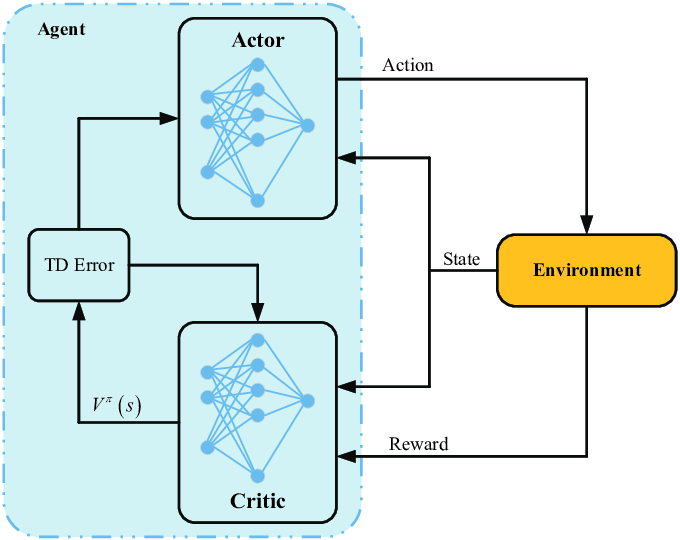
Actor-Critic
Q-learning이나 PG는 단일 신경망을 이요한 강화학습 방식입니다. 반면 Actor Critic은 두 개의 신경망으로 구성 됩니다. Actor는 정책 경사 모델을 사용해 정책을 학습시키고, Critic은 수행한 행동을 평가하는 가치 함수를 학습시킵니다. 이렇게 하면 단일 모델을 사용했을 때 발생하기 쉬운 high variance 문제를 완화할 수 있습니다.
마치며
이상으로 강화학습의 전반적인 내용에 대해 소개해 드렸습니다. 하지만 제가 소개한 것 말고도 강화학습에는 많은 알고리즘과 기법들이 있습니다. 이 장에서 다루기는 너무 양이 많으니 앞으로 심층 강화학습관련 게시글에서 따로 소개해 드리겠습니다. 긴 글 읽어 주셔서 감사합니다.
참고
- 파이썬을 이용한 딥러닝/강화학습 주식투자(퀀티랩)
- Sergey Levine Deep Reinforcement Learning Lecture Note
- 수학으로 풀어보는 강화학습 원리와 알고리즘 (박성수)
- 모델 성능 개선으로 익히는 강화학습 A to Z
