애플리케이션 계층
2.6 비디오 스트리밍과 콘텐츠 분배 네트워크
여러 평가기관의 자료에 의하면, 넷플릭스, 유튜브, 아마존 프라임 등을 통한 스트리밍 비디오가 2020년 전체 인터넷 트래픽의 80%를 차지한다. 이 절에서는 오늘날 인터넷에서 널리 사용되는 비디오 스트리밍 서비스가 어떻게 구현되는지에 대한 개요를 제공한다. 캐시와 같은 기능을 하는 애플리케이션 레벨 프로토콜과 서버를 사용하여 구현된 것을 볼 수 있다.
2.6.1 인터넷 비디오
스트리밍 비디오 애플리케이션에서는 미리 녹화된 비디오, 예를 들어 영화, TV 프로그램, 스포츠 경기 또는 유튜브 등에서 볼 수 있는 UCC 비디오 등을 대상으로 한다. 이러한 녹화된 비디오는 서버에 저장되어 사용자가 비디오 시청을 서버에게 온디맨드로 요청한다. 넷플릭스, 유튜브, 아마존, 틱톡 등 많은 인터넷 회사가 비디오 스트리밍을 지원하고 있다.
그러나 비디오 스트리밍에 대한 논의를 시작하기 전에 먼저 비디오 매체 자체에 대한 느낌을 빨리 가져야 한다. 비디오는 이미지의 연속으로서 일반적으로 초당 24개 또는 30개의 이미지로 일정한 속도로 표시된다. 압축되지 않은 디지털 인코딩된 이미지는 픽셀단위로 구성되며, 각 픽셀은 휘도와 색상을 나타내는 여러 비트들로 인코딩된다. 비디오의 중요한 특징을 압축될 수 있다는 것인데, 비디오 품질과 비트 전송률은 서로 반비례한다. 오늘날의 상용 압축 알고리즘은 근본적으로 원하는 모든 비트 전송률로 비디로를 압축할 수 있다. 물론 비트 전송률이 높을수록 이미지 품질이 좋아지고 전반적인 사용자 시청 환경이 향상된다.
네트워킹 측면에서 비디오의 가장 두드러진 특성은 높은 비트 전송률이다. 압축된 인터넷 비디오는 일반적으로 고화질 동영상을 스트리밍하기 위해 100 kbps에서 4Mbps 이상으로 구성된다. 4 K 스트리밍은 10 Mbps 이상의 비트 전송률로 예상된다. 이는 하이엔드 동영상의 경우 트래픽과 스토리지 용량이 엄청나게 필요함을 의미한다. 예를 들어, 지속 시간이 67분인 단일 2 Mbps 비디오는 1 GB의 스토리지 트래픽을 소비한다. 지금까지 스트리밍 비디오에서 가장 중요한 성능 척도는 평균 종단 간 처리량이다. 연속재생을 제공하기 위해, 네트워크는 압축된 비디오의 전송률 이상의 스트리밍 애플리케이션에 대한 평균 처리량을 제공해야 한다.
또한 압축을 사용하여 동일한 비디오를 여러 버전의 품질로 만들 수 있다. 예를 들어 300 kbsp, 1 Mbps, 3 Mbps의 속도로 동일한 비디오의 세 가지 버전을 만들 때 압축을 사용할 수 있다. 사용자는 현재 사용 가능한 대역폭을 선택하여 보고 싶은 버전을 결정할 수 있다. 초고속 인터넷 연결을 가진 사용자는 3 Mbps 버전을 선택할 수 있으며, 스마트폰으로 3G를 통해 동영상을 시청하는 경우 300 kbps 버전을 선택할 수 있다.
2.6.2 HTTP 스트리밍 및 DASH
HTTP스트리밍에서 나오는 비디오는 HTTP 서버 내의 특정 URL을 갖는 일반적인 파일로 저장된다. 사용자가 비디오 시청을 원하면 클라이언트는 서버에게 TCP연결을 설립하고 해당 URL에 대한 HTTP GET 요청을 발생시킨다. 그러면 서버가 기본 네트워크 프로토콜 및 트래픽 조건이 허용되는 대로 HTTP 응답 메시지 내에서 비디오 파일을 전송한다. 클라이언트 쪽에서는 애플리케이션 버퍼에 전송된 바이트가 저장된다. 이 버퍼의 바이트 수가 미리 정해진 임곗값(threshold)을 초과하면 클라이언트 애플리케이션이 재생을 시작한다. 특히 스트리밍 비디오 애플리케이션은 클라이언트 애플리케이션 버퍼에서 주기적으로 비디오 프레임을 가져와서 프레임을 압축해제한 다음 사용자의 화면에 표시한다. 따라서 비디오 스트리밍 애플리케이션은 비디오의 후반 부분에 해당하는 프레임을 수신하고 버퍼링할 때 비디오를 표시한다.
HTTP 스트리밍은 유튜브 등 많은 시스템에서 실제 적용되고 있으나, 중요한 문제점이 있다. 바로 모든 클라이언트가 그들 사이의 가용 대역폭의 차이에도 불구하고 똑같이 인코딩된 비디오를 전송받는다는 점이다. 가용 대역폭의 차이는 각기 다른 클라이언트들 간에 존재할 뿐만 아니라 동일한 클라이언트에서도 시간에 따른 차이가 발생한다. 이 문제점으로 인해 새로운 형태의 HTTP 기반 스트리밍인 DASH(Dynamic Adaptive Streaming over HTTP) 가 개발되었다. DASH에서 비디오는 여러 가지 버전으로 인코딩되며, 각 버전은 비트율과 품질 수준이 서로 다르다. 클라이언트는 동적으로 서로 다른 버전의 비디오를 몇 초 분량의 길이를 갖는 비디오 조각(chunk) 단위로 요청한다. 가용 대역폭이 충분할 때는 높은 비트율의 비디오 버전을 요청하며, 가용 대역폭이 적을 때는 낮은 비트율의 비디오 버전을 요청한다. 클라이언트는 HTTP GET 요청을 이용해 다른 버전의 비디오 조각을 매번 선택한다.
DASH는 서로 다른 인터넷 접속 회선을 가진 클라이언트들에게 서로 다른 인코딩률을 갖는 비디오를 선택할 수 있도록 허용한다. 저속의 3G 연결을 갖는 클라이언트는 낮은 품질의 비디오를 받을 수 있고, 고속의 광섬유 연결을 갖는 클라이언트는 고품질의 비디오를 받을 수 있다. 또 DASH는 클라이언트에게 세션 유지 중에 시간에 따라 변화하는 종단 간 가용 대역폭에 적응할 수 있도록 허용한다. 이 특성은 이동 사용자에게 특히 중요하며, 이는 이동 중에 접속하는 기지국의 상황에 따라 가용 대역폭이 자주 변화하기 때문이다.
DASH를 사용할 때, 각 비디오 버전은 HTTP 서버에 서로 다른 URL을 가지고 저장된다. HTTP 서버는 비트율에 따른 각 버전의 URl을 제공하는 매니페스트 파일(manifest file) 을 갖고 있다. 클라이언트는 먼저 매니페스트 파일을 요청하여 서버에서 제공되는 다양한 버전에 대해 알게 된다. 이후 클라이언트는 매번 원하는 버전의 비디오 조각 단위 데이터를 선택하여 HTTP GET 요청 메시지에 URL과 byte-range를 지정하여 요청한다. 비디오 조각 단위 데이터를 다운로드하는 동안에 클라이언트는 측정된 수신 대역폭과 비트율 결정 알고리즘을 이용해 다음에 선택할 비디오 조각 단위 데이터의 버전을 결정한다. 클라이언트가 충분한 분량의 버퍼링된 비디오를 갖고 있고 측정된 수신 대역폭이 크다면 당연히 고품질의 비디오 조각 단위 데이터를 선택할 것이다. 반대로 클라이언트가 적은 분량의 버퍼링된 비디오를 갖고 있고 수신 대역폭이 작다면 낮은 품질의 비디오 조각 단위 데이터를 선택할 것이다. 그러므로 DASH는 클라이언트가 서로 다른 품질 수준을 자유롭게 변화시킬 수 있도록 허용한다.
2.6.3 콘텐츠 분배 네트워크(CDN)
오늘날 많은 인터넷 비디오 회사둘은 날마다 수많은 사용자들에게 수 Mbps의 비디오 스트림을 분배하고 있다. 유튜브 같은 회사는 수천만에 이르는 소장 비디오를 가지고 매일 수억 명의 사용자들에게 스트리밍 서비스를 제공한다. 이 엄청난 스트리밍 트래픽을 전세계에 걸친 지점에 끊김 없이 안정적으로 제공하는 일은 매우 큰 문제다.
인터넷 비디오 회사에서 스트리밍 서비스를 제공하는 가장 단순한 방법은 단일한 거대 데이터 센터를 구축하고 모든 비디오 자료를 데이터 센터에 저장한 뒤 전 세계의 사용자에게 비디오 스트림을 데이터 센터로부터 직접 전송하는 것이다. 그러나 이 방법에는 세 가지의 중대한 문제가 잇다. 첫째, 클라이언트가 데이터 센터로부터 지역적으로 먼 지점에 있는 경우, 서버로부터 클라이언트로의 패킷 경로는 많은 다양한 통신 링크와 ISP를 거쳐 가게 되는데, 이러한 ISP는 각기 다른 대륙에 위치할 수도 있다. 이 링크들 중 하나라도 비디오 소비율보다 낮은 전송용량을 갖는다면 종단 간 처리율이 낮아지고 결국 사용자는 짜증스러운 화면 정지 현상을 겪게 된다(1장에서 배웠듯이 종단 간 처리율이 병목 지점의 링크에 의해 좌우된다는 사실을 기억하라). 종단 간 경로 길이가 길어질수록 이와 같은 현상은 증가한다. 두 번째 문제는 인기 있는 비디오는 같은 통신 링크를 통해 여러 벚 납놉ㄱ적으로 전송될 것이라는 점이다. 이는 네트워크 대역폭의 낭비는 물론이고 인터넷 비디오 회사는 회선을 제공하는 ISP들에게 동일한 바이트를 전송하는 것에 대해 중복 비용을 지불하는 결과를 초래한다. 세 번째 문제점은 단일한 데이터 센터를 구축하면 한 번의 장애로 인해 전체 서비스가 중단될 수 있는 위험이 있다는 것이다. 데이터 센터의 서버나 인터넷과의 연결 링크가 장애를 일으키면 어떠한 비디오 스트리밍 서비스도 불가능해진다.
전 세계의 사용자들에게 엄청난 양의 비디오 데이터를 분배하는 문제를 해결하기 위해 거의 대부분의 비디오 스트리밍 회사들은 콘텐츠 분배 네트워크(Content Distribution Network, CDN) 을 이용한다. CDN은 다수의 지점에 분산된 서버들을 운영하며, 비디오 및 다른 형태의 웹 콘텐츠 데이터의 복사본을 이러한 분산 서버에 저장한다. 사용자는 최선의 서비스와 사용자 경험(user experience)을 제공할 수 있는 지점의 CDN 서버로 연결된다. CDN은 콘텐츠 제공자가 소유한 사설 CDN(private CDN) 일 수 있으며, 예를 들어 유튜브의 비디오는 구글의 CDN을 통해 분배된다. 또는 제3자가 운영하는 CDN을 통해 다수의 콘텐츠 제공자가 서비스할 수도 있는데, Akamai, Limelight, Level-3가 제3자가 운영하는 CDN(third-party CDN) 에 속한다. 현재 CDN을 다룬 읽을 만한 문헌으로는 [Leighton 2009, Nygren 2010]이 있다.
CDN은 일반적으로 서버의 위치에 대해 다음 두 가지 철학 중 하나를 채용하고 있다.
- Enter Deep: 첫 번째 철학은 Akamai에 의해 주창된 것으로서 서버 클러스터를 세계 곳곳의 접속 네트워크에 구축함으로써 ISP의 접속 네트워크로 깊숙이 들어가는 것이다(접속 네트워크에 관해서는 1.3절을 참고하라). Akamai는 수천 개의 지점에 서버 클러스터를 구축함으로써 이 방식을 구현했다. 이 방식의 목적은 서버를 최대한 사용자 가까이에 위치시켜 사용자와 CDN 서버 사이의 링크 및 라우터 수를 줄이고, 사용자가 경험하는 지연 시간 및 처리율을 개선하는 것이다. 문제는 고도로 분산된 설계로 인해 서버 클러스터를 유지 관리하는 비용이 커진다는 점이다.
- Bring Home: 두 번째 철학은 Limelight와 다른 회사들에 의해 적용된 것으로 좀 더 적은 수의 핵심 지점에 큰 규모의 서버 클러스터를 구축하여 ISP를 Home으로 가져오는 개념이다. 접속 ISP에 연결하는 대신, 이러한 CDN들은 일반적으로 그들의 클러스터를 인터넷 교환 지점(Internet Exchange Point, IXP)에 배치된다. 첫 번쨰 철학인 Enter Deep에 비해 이 두 번째 방식은 클러스터 유지 및 관리 비용이 줄어드는 대신에 사용자가 느끼는 지연 시간과 처리율은 상대적으로 나빠진다.
서버 클러스터의 위치가 정해지면 CDN은 콘텐츠의 복사본을 이들 클러스터에 저장한다. CDN은 각 클러스터마다 모든 비디오의 복사본을 전부 유지할 필요는 없는데, 이는 어떤 비디오는 인기가 거의 없거나 일부 특정 국가에서만 인기가 있을 수 있기 때문이다. 실제로 CDN은 클러스터에 대해 푸시(push) 방식이 아닌 풀(pull) 방식을 사용한다. 어떤 사용자가 지역 클러스터에 없는 비디오를 요청하면, 해당 비디오를 중앙 서버나 다른 클러스터로부터 전송받아 사용자에게 서비스하는 동시에 복사본을 만들어 저장한다. 2.2.5절에게 본 인터넷 캐시와 마찬가지로 클러스터의 저장 공간이 가득 차면 자주 사용되지 않는 비디오 데이터는 삭제된다.
CDN 동작
CDN을 구축하는 두 가지 방식을 살펴봤으니, 이제 CDN의 구체적인 동작을 알아보자. 사용자 호스트의 웹 브라우저가 URL을 지정함으로써 특정 비디오의 재생을 요청하면 CDN은 그 요청을 가로채 (1) 그 시점에서 클라이언트에게 가장 적당한 CDN 클러스터를 선택하고, (2) 클라이언트의 요청을 해당 클러스터의 서버로 연결한다. 우리는 CDN이 가장 적당한 클러스터를 어떻게 결정하는지 논의할 것이다. 그러나 그전에 먼저 사용자의 요청을 가로채고 다른 곳으로 연결하는 절차를 살펴보자.
대부분의 CDN은 사용자의 요청을 가로채고 다른 곳으로 연결하는 데 DNS를 활용한다(DNS의 활용에 관한 재미있는 논의는[Vixie 2009] 참고). DNS가 어떻게 이 과정에 개입하는지 알기 위해 전형적인 간단한 예를 살펴보자. NetCinema라는 콘텐츠 제공자가 KingCDN이라는 CDN 업체를 이용해 비디오를 고객에게 분배한다고 하자. NetCinema의 웹 페이지에서는 각 비디오가 'video'라는 문자열과 고유한 ID를 포함하는 URL을 할당받는다. 예를 들어 '트랜스포머 7' 비디오는 http://video.netcinema.com/6Y7B23V라는 URL을 할당받는다. 아래 그림과 같이 6단계의 과정이 일어난다.
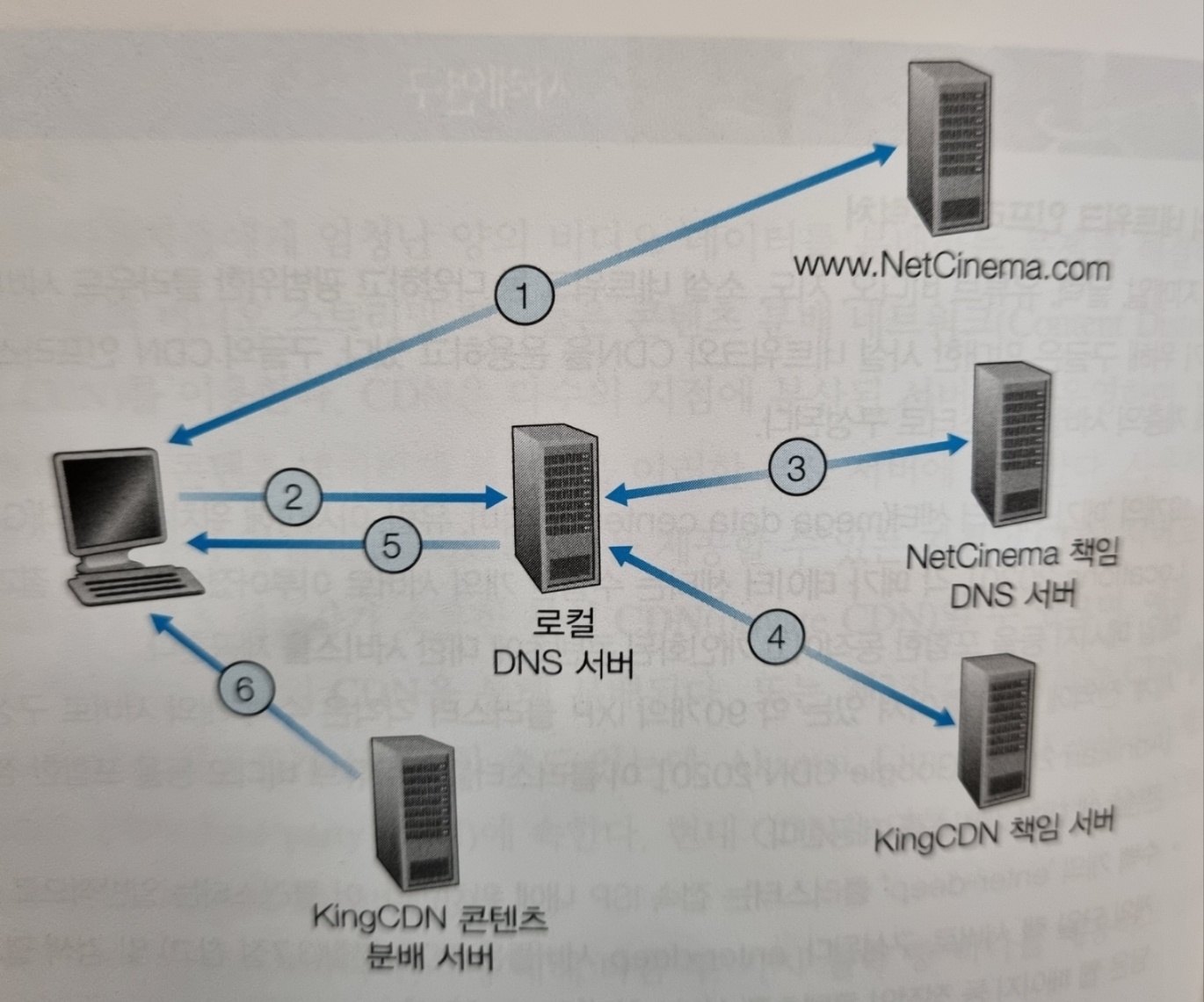
- 사용자가 NetCinema의 웹 페이지를 방문한다.
- 사용자가 http://video.netcinema.com/6Y7B23V 링크를 클릭하면, 사용자의 호스트는 video.netcinema.com에 대한 DNS 질의를 보낸다.
- 사용자의 지역 DNS 서버(LDNS)는 호스트 이름의 'video' 문자열을 감지하고는 해당 질의를 NetCinema의 책임 DNS 서버로 전달한다. NetCinema 책임 DNS 서버는 해당 DNS 질의를 KingCDN으로 연결하기 위해 IP 주소 대신에 KingCDN의 호스트 이름(예:a1105.kingcdn.com)을 LDNS에게 알려준다.
- 이 시점부터 DNS 질의는 KingCDN의 사설 DNS 구조로 들어가게 된다. 사용자의 LDNS는 a1105.kingcdn.com에 대한 두 번째 질의를 보내고 이는 KingCDN의 DNS에 의해 KingCDN 콘텐츠 서버의 IP 주소로 변환되어 LDNS에게 응답된다. 이때 클라이언트가 콘텐츠를 전송받게 될서버가 결정된다.
- LDNS는 콘텐츠를 제공할 CDN 서버의 IP 주소를 사용자 호스트에게 알려준다.
- 클라이언트는 KingCDN 서버의 IP 주소를 얻고 나면, 해당 IP 주소로 직접 TCP 연결을 설정하고 비디오에 대한 HTTP GET 요청을 전송한다. 만약 DASH가 사용된다면 서버는 먼저 각기 다른 버전의 비디오에 대한 URL 목록을 포함하는 매니페스트 파일을 클라이언트에게 전송하고 클라이언트는 동적으로 각기 다른 버전의 비디오 조각 단위 데이터를 선택할 수 있다.
클러스터 선택 정책
CDN 구축의 핵심 중 하나를 클러스터 선택 정책(cluster selection strategy) 이다. 이는 클라이언트를 동적으로 어떤 서버 클러스터 또는 CDN 데이터 센터로 연결하는 방식이다. 앞에서 봤듯이 CDN은 클라이언트가 DNS 서비스를 수행하는 과정에서 클라이언트의 LDNS 서버의 IP 주소를 알게 된다. IP 주소를 알아낸 CDN은 해당 IP 주소에 기초해 최선의 클러스터를 선택할 필요가 있다. 일반적으로 CDN은 각기 고유한 클러스터 선택 정책을 사용한다. 여기서는 일반적인 클러스터 선택 기법과 장단점을 살펴본다.
간단한 클러스터 정책의 하나로 클라이언트에게 지리적으로 가장 가까운 클러스터를 할당하는 기법이 있다. Quova[Quova 2020]나 MaxMind[MaxMind 2020] 같은 상용 지리정보 데이터베이스를 이용하면 LDNS의 IP 주소는 지리적으로 매핑될 수 있다. DNS 질의가 특정 LDNS로부터 도착하면 CDN은 해당 LDNS에서 가장 가까운 클러스터를 선택한다. 이 간단한 방법은 대부분의 클라이언트를 대상으로 상당히 잘 동작한다[Agarwal 2009]. 그러나 일부 클라이언트에게는 잘 동작하지 않는데, 그 이유는 지리적으로는 가장 가까운 클러스터가 네트워크 경로의 길이 홉(hop)의 수에 따라 가장 가까운 클러스터가 아닐 수 있기 때문이다. 또한 DNS 기반 방법에 내재된 문제로서, 일부 사용자는 상당히 멀리 있는 DNS 서버를 LDNS로 사용하도록 설정할 수 있다. 이 경우 LDNS의 IP 주소를 기반으로 선택한 클러스터는 사용자 호스트로부터 멀리 위치하게 된다. 게다가 이 방법은 인터넷 경로의 지연이나 가용 대역폭의 변화 등은 무시하고 항상 같은 클러스터를 클라이언트에게 할당하게 된다.
현재의 네트워크 트래픽 상황을 반영한 최선의 클러스터를 선택하기 위해 CDN은 주기적으로 클러스터와 클라이언트 간의 지연 및 손실 성능에 대한 실시간 측정(real-time measurements) 을 수행하기도 한다. 예를 들어, CDN은 각 클러스터가 ping이나 DNS 질의 같은 프로브 메시지를 주기적으로 LDNS들에게 전송하게 할 수 있다. 문제는 많은 LDNS가 이와 같은 메시지에 응답하지 않도록 설정되어 있다는 점이다.
2.6.4 사례연구: 넷플릭스, 유튜브
스트리밍 저장 비디오에 대한 논의를 두 가지 성공적인 적용 사례를 살펴보는 것으로 정리하고자 한다. 이 사례들은 넷플릭스와 유튜브로서, 이들 시스템이 서로 상당히 다른 접근 방법을 취하고 있으나 동시에 이 절에서 다루었던 많은 원칙을 기반으로 하고 있음을 보게 될 것이다.
넷플릭스
넷플릭스는 2020년 현재 미국의 온라인 영화 및 TV 시리즈를 제공하는 선두 서비스 업체다. 앞서 논의한 것처럼 넷플릭스 비디오 배포에는 두 가지 주요 구성요소인 아마존 클라우드와 자체 CDN 인프라가 있다.
넷플릭스에는 사용자 등록 및 로그인, 결제, 영화 장르 검색, 영화 추천 서비스 등 다양한 기능을 처리하는 웹사이트가 있다. 아래 그림에서 볼 수 있듯이, 웹사이트(및 백엔드 데이터베이스)는 아마존 서버 안에 있는 아마존 클라우드에서 모든 것이 실행된다.
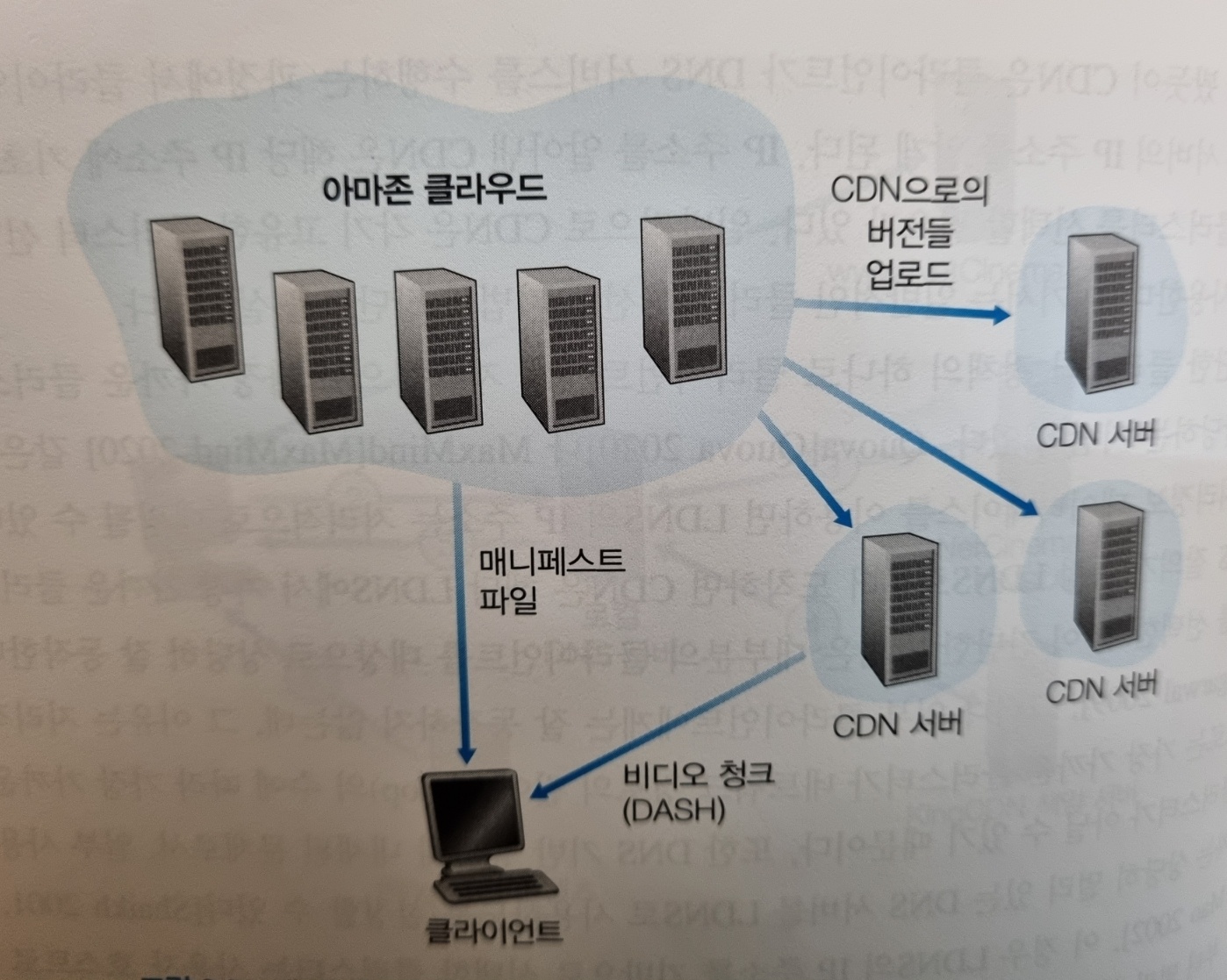
또한 아마존 클라우드는 다음과 같은 중요한 기능을 처리한다.
- 콘텐츠 수집(content ingestion): 넷플릭스는 고객들에게 비디오를 분배하기 전에 먼저 영화를 수집하고 처리해야 한다. 넷플릭스는 영화의 스튜디오 마스터 버전을 받아서 아마존 클라우드 시스템의 호스트에 업로드한다.
- 콘텐츠 처리(content processing): 아마존 클라우드 시스템의 기기에서는 데스크톱 컴퓨터, 스마트폰, TV에 연결된 게임 콘솔 등 고객들의 다양한 플레이어 기기 사양에 적합하도록 각 영화의 여러 가지 형식의 비디오를 생성한다. 또한 DASH를 이용한 HTTP 적응적 스트리밍 서비스를 위해 각 형식별로 다양한 비트율의 여러 가지 버전을 생성한다.
- CDN으로의 버전 업로드: 일단 영화의 다양한 버전이 생성되면 아마존 클라우드 시스템의 호스트는 이러한 버전을 CDN으로 업로드할 수 있다.
2007년 넷플릭스가 처음으로 비디오 스트리밍 서비스를 시작했을 때, 3개의 CDN 회사가 비디오 콘텐츠를 배포했다. 이후 자사의 모든 비디오를 스트리밍할 수 있는 자체 프라이빗 클라우드를 구축했다. 자체 CDN을 구축하기 위해 넷플릭스는 IXP 및 거주용 ISP 자체에서 서버 랙을 설치했다. 현재 IXP 위치에 200대 이상의 서버 랙과 서버 랙을 수용하는 수백 개의 ISP 장소도 보유하고 있다. 넷플릭스 랙이 있는 IXP의 현재 목록은 [Bottger 2018]과 [Netflix Open Connect 2020]을 참고하라. 넷플릭스는 잠재적인 ISP 파트너에게 네트워크를 위한(무료)랙 설치 지침을 제공한다. 각각의 랙 서버에는 10 Gbps 이더넷 포트와 100테라바이트 이상의 스토리지가 있다. 랙에 있는 서버의 수는 다양하다. IXP 설치에는 수십 개의 서버와 DASH를 지원하는 여러 버전의 비디오를 포함한 전체 스트리밍 비디오 라이브러리가 포함되어 있다. 넷플릭스는 풀 캐싱(pull-caching)을 사용하여 IXP 및 ISP의 CDN 서버를 채운다. 대신 사용량이 적은 시간에 비디오를 CDN 서버에 푸시하여 배포한다. 전체 라이브러리를 보유할 수 없는 위치의 경우 매일매일 가장 많이 결정되는 비디오만 푸시한다. 넷플릭스 CDN 디자인은 유튜브 비디오 [Netflix Video 1] 및 [Netflix Video 2]에 자세히 설명되어 있다. 또란 {Bottger 2018]을 참고하라.
넷플릭스 구조의 기본 구성요소에 대한 지식을 바탕으로 영화 전송에 관련된 다양한 서버와 클라이언트 간의 동작을 좀 더 자세히 살펴보자. 앞서 언급한 것과 같이 넷플릭스 비디오 라이브러리를 탐색하는 웹 페이지는 아마존 클라우드 서버에서 제공된다. 사용자가 재생할 영화를 선택하면 아마존 클라우드에서 실행 중인 넷플릭스 소프트웨어가 먼저 해당 영화 사본을 갖고 있는 CDN 서버를 결정한다. 영화가 있는 서버 중에서 소프트웨어는 클라이언트 요청에 '최적의' 서버를 결정한다. 클라이언트가 해당 ISP에 설치된 CDN 서버 랙에 있는 로컬 ISP를 사용하고 있고, 이 랙에 요청된 사본이 있는 경우 일반적으로 이 랙 서버가 선택된다. 그렇지 않은 경우 근처에 있는 IXP 서버가 선택된다.
일단 넷플릭스가 콘텐츠를 전달할 CDN 서버를 결정하면 클라이언트는 요청된 영화의 다른 버전에 대한 URL을 가진 매니페스트 파일과 특정 서버의 IP 주소를 보낸다. 그러면 클라이언트와 해당 CDN 서버는 독점 버전의 DASH를 이용하여 직접 상호작용한다. 2.6.2절에 기술한 것처럼 클라이언트는 HTTP GET 요청 메시지의 byte-range 헤더를 이용해 각기 다른 버전의 비디오 조각 단위 데이터를 요청할 수 있다. 넷플릭스는 대략 4초 분량의 비디오 조각 단위 데이터를 사용한다. 클라이언트는 비디오 조각 단위 데이터를 다운로드하는 동안 수신 처리율을 측정하고 전송률 결정 알고리즘을 이용해 다음에 요청할 비디오 조각 단위 데이터의 품질을 결정한다.
넷플릭스는 적응적 스트리밍과 CDN을 포함하여 이 절의 전반부에서 논의한 여러 가지 기술을 사용한다. 그러나 넷플릭스는 비디오(웹 페이지 제외)만 배포하는 자체 CDN을 사용하고 있기 때문에 CDN 디자인을 단순화하고 조정할 수 있다. 특히 넷플릭스는 특정 클라이언트를 CDN 서버에 연결하기 위해 2.6.3절에서 설명한 것처럼 DNS 리다이렉션을 사용할 필요가 없다. 대신 아마존 클라우드에서 실행되는 것처럼 넷플릭스 소프트웨어는 클라이언트에게 특정 CDN 서버를 사용하도록 알려준다. 또한 넷플릭스 CDN은 풀 캐싱(pull-caching)보다 푸시 캐싱(push-caching)을 사용한다. 콘텐츠는 캐시 미스(cache miss) 중에 동적으로 사용되는 것이 아니라 사용량이 적은 시간 중 예약된 시간에 서버에 푸시한다.
유튜브
매일 수백 시간 분량의 동영상을 유튜브에 업로드하고 하루에 수십억 개의 동영상을 볼 수 있다. 2005년 4월에 서비스를 시작한 유튜브는 2006년 11월에 구글에 합병되었다. 비록 구글/유튜브가 디자인 및 프로토콜은 독점적이지만 몇 가지 독립적인 측정 노력을 통해 유튜브의 운영 방식에 대한 기본적인 이해를 얻을 수 있다 넷플릭스와 마찬가지로 유튜브는 비디오의 분배에 CDN을 적극적으로 활용한다. 넷플릭스와 유사하게 구글은 자체 비공개 CDN을 사용하여 유튜브 동영상을 배포하고 수백 가지의 IXP 및 ISP 위치에 서버 클러스터를 설치했다. 이러한 위치에서 거대한 데이터 센터에서 직접 동영상을 배포한다. 구글 역시 2.2.5절에서 설명한 대로 사용자를 특정 서버 클러스터와 연결하는 데 DNS를 사용한다. 대부분의 경우 구글의 클러스터 선택 정책은 클라이언트와 클러스터 간의 RTT가 가장 적은 곳을 연결하는 것이다. 그러나 떄로는 클러스터들 가느이 균형 있는 작업 부하를 위해 클라이언트가 DNS를 통해 좀 더 멀리 있는 클러스터에 연결되기도 한다.
유튜브는 HTTP 스트리밍을 채용하고 있다. 유튜브는 보유한 비디오에 대해 각기 다른 비트율과 품질을 갖는 여러 단계의 버전을 생성하여 제공한다.2011년에 유튜브는 DASH 같은 적응적 스트리밍 대신에 사용자가 스스로 버전을 선택하게 했다. 재생 위치 조정과 조기 종료로 인한 대역폭과 서버 자원의 낭비를 줄이기 위해 유튜브는 HTTP byte-range 헤더를 이용해 목표한 분량의 선인출 데이터 이후에 추가로 전송되는 데이터 흐름을 제한한다.
유튜브에는 매일 수백만 개의 비디오가 업로드된다. 유튜브는 서버로부터 클라이언트로의 비디오 전송 뿐만 아니라 사용자로부터 서버로의 비디오 업로드에도 HTTP 스트리밍을 사용한다. 유튜브는 업로드된 각각의 비디오를 자신들의 형식으로 변환하고 여러개의 버전으로 생성한다. 이러한 과정은 전적으로 구글 데이터 센터 내에서 이루어진다.
