1. 어떤 특성이 가장 중요한 특성인지 말할 수 있을까?
1907년 영국의 유전학자인 프랜시스 골턴은 재밌는 대회를 하나 개최했다. 바로 황소의 무게를 정확하게 맞히는 사람에게 상금을 주겠다고 한 것이다. 예상 가능하듯이 대회에 참가한 800명 중에 단 한 명도 황소의 무게를 정확하게 맞히지 못했다. 그러나 놀라운 건 800명이 추측한 황소 무게를 모두 더하여 평균을 내보니 전문가들의 추정치보다 더 정확했다는 점이다. 이 이야기는 집단 지성에 대해서 소개할 때 많이 언급되는 사례로, 여러 사람이 힘을 모아 문제를 해결한다면 더 좋은 성과를 낼 수 있음을 보여준다. 문제를 해결하기 위해서 힘을 합치는 사람들처럼, 머신러닝에서도 답을 더 잘 맞히기 위해 여러 모델들을 결합하여 사용한다. 이러한 모델을 앙상블 모델이라고 한다. 데이터 분석이나 머신러닝에 조금이라도 관심있는 사람이라면 한 번 쯤은 들어봤을 랜덤 포레스트(Random Forest)도 앙상블 모델 중 하나이다. 앙상블 모델은 보통 단일 모델보다 성능이 좋기 때문에 많이 사용된다.
그런데 앙상블 모델에는 문제가 하나 있다. 바로 특성이 타겟에 얼마나, 어떻게 영향을 주는지 알기 어렵다는 것이다. coefficient로 특성들의 기여도를 확인할 수 있었던 선형 모델과 달리, 트리 모델에는 coefficient 같은 존재가 없다. 심지어 트리 모델이 여러 개 합쳐져 만들어진 랜덤 포레스트 모델은 각 트리마다 사용된 특성이 다를테니 문제가 더 복잡해진다. 그래서 앙상블 모델에서는 각 특성이 모델 안에서 어떻게 작용하는지 알기 어렵다. 그럼 앙상블 모델을 쓰지 못하는 거냐고? 걱정하지 않아도 된다. 이런 문제점을 해소해 줄 몇 가지 도구가 있기 때문이다. 오늘은 그 중에서 특성에 대한 전역적인 설명을 할 수 있는 순열 중요도(Permutation Importances)와 PDP(Partial Dependence Plots)에 대해서 알아보려 한다.
2. 모델 준비하기
순열 중요도와 PDP에 대해서 알아보기 위해서 간단한 모델을 하나 만드려고 한다. 파이썬 머신러닝 라이브러리인 Scikit-Learn에서 제공하는 데이터셋 중 하나인 boston 데이터셋을 활용하여 보스턴의 집값을 예측하는 모델을 만들어 볼 것이다.
데이터 준비
# 라이브러리 및 패키지 import
import pandas as pd
from sklearn.datasets import load_boston
# 데이터 불러오기
boston = load_boston()
df = pd.DataFrame(boston['data'], columns=boston['feature_names'])
df['price'] = boston['target']
df.columns = [ x.lower() for x in df.columns ]
df.head(3)[Out]
boston 데이터셋에는 집의 방 개수, 찰스강 근처에 위치하고 있는지 여부, 해당 지역의 1인당 범죄율, 집의 가격 등의 정보가 담겨있다.
모델 만들기
이 글의 목적은 순열 중요도와 PDP에 대해 알아보는 것이므로 EDA와 데이터 전처리 과정은 생략하였다. 그러나 좋은 모델을 위해서는 EDA와 전처리를 통해서 좋은 데이터를 사용해야 한다는 것을 잊지 말아야 한다.
Step 1) 학습, 검정, 테스트 데이터셋 준비
# train / validation / test 데이터셋으로 분리
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.2, random_state=1)
train, val = train_test_split(train, test_size=0.25, random_state=1)
# feature Matrix, target vector 생성
target = 'price'
features = train.drop(columns=[target]).columns
X_train = train[features]
y_train = train[target]
X_val = val[features]
y_val = val[target]
X_test = test[features]
y_test = test[target]
# 확인
print("feature Matrix: ", X_train.shape, X_val.shape, X_test.shape)
print("target vector: ", y_train.shape, y_val.shape, y_test.shape)Step 2) 기준 모델 확인
from sklearn.metrics import mean_absolute_error
# 모두 평균으로 예측
y_pred = [y_train.mean()] * len(y_val)
# 결과 확인
print('MAE: ', mean_absolute_error(y_val, y_pred))[Out]
MAE: 6.396274875012257회귀 모델의 가장 간단한 기준모델은 모두 평균값으로 예측하는 것이다. 집값을 모두 평균값으로 예측했을 때 MAE는 약 6.4가 나왔다. 앞으로 만들 모델의 MAE가 약 6.4보다 작아야 학습이 잘 된 모델이라고 할 수 있다.
Step 3) 랜덤 포레스트 모델 생성
from sklearn.impute import SimpleImputer
from category_encoders import OrdinalEncoder
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
# 파이프라인 생성 및 학습
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestRegressor(random_state=1, n_jobs=-1)
)
pipe.fit(X_train, y_train)
# 예측
y_pred = pipe.predict(X_val)
# 결과 확인
print('MAE: ', mean_absolute_error(y_val, y_pred))[Out]
MAE: 2.5809702970297006RandomForestRegressor를 사용해서 랜덤 포레스트 회귀 모델을 만들었다. 이 모델의 MAE는 약 2.6으로, 기준모델의 MAE보다 작다. 따라서 학습이 잘 된 모델이라고 할 수 있다. 이제 이 모델을 사용하여 순열 중요도와 PDP에 대해서 알아보자.
3. 순열 중요도(Permutation Importances)
특성의 중요도를 알 수 있는 가장 간단하고 확실한 방법은 해당 특성을 제외한 후 모델을 만들어 성능을 비교하는 것이다. 마치 사람들이 운동 경기를 볼 때 특정 선수가 출전했을 때와 하지 않았을 때 팀의 성과를 비교하며 해당 선수가 중요하다, 아니다 이야기 하는 것처럼 말이다. 그런데 이 방법은 특성 하나를 빼고 모델을 생성하고, 또 다른 특성 하나를 빼고 모델을 생성하는 작업을 반복해야 한다는 단점이 있다. 지금 우리가 만든 모델은 특성이 고작 13개고, 학습할 데이터의 수는 303개 뿐이므로 그렇게 오래 걸리지는 않겠지만, 실제 현장에서 마주칠 데이터 프레임은 이것보다 특성의 수와 학습할 데이터의 수가 훨씬 많을 것이다. 이런 데이터 프레임은 모델 하나를 학습하는 데에도 시간이 오래 걸릴텐데 여러 모델을 만들고 비교해야 한다면 시간이 얼마나 걸릴지 알 수 없다.
그래서 등장한 게 바로 순열 중요도이다. 순열 중요도는 각각의 특성을 무작위로 배열하여 제 기능을 하지 못하게 만든 뒤 결과를 비교하여 각 특성의 중요도를 계산한다. 즉, 특성을 아예 제외하는 건 아니기에 각각의 모델을 학습할 필요가 없으므로 시간이 훨씬 단축된다는 장점이 있다. 순열 중요도는 eli5라는 라이브러리를 통해서 구할 수 있다.
import eli5
from eli5.sklearn import PermutationImportance
# permuter 생성
permuter = PermutationImportance(
pipe,
scoring='neg_mean_absolute_error',
n_iter=3,
random_state=1)
# permutation importance 계산
permuter.fit(X_val, y_val)
# 결과 확인
feature_names = list(X_val.columns)
pd.Series(permuter.feature_importances_, feature_names).sort_values(ascending=False)[Out]
lstat 4.127152
rm 1.253970
nox 0.435436
crim 0.336284
age 0.176056
dis 0.133964
ptratio 0.126759
indus 0.092835
tax 0.061842
b 0.056297
chas 0.007832
rad 0.000762
zn -0.005069
dtype: float64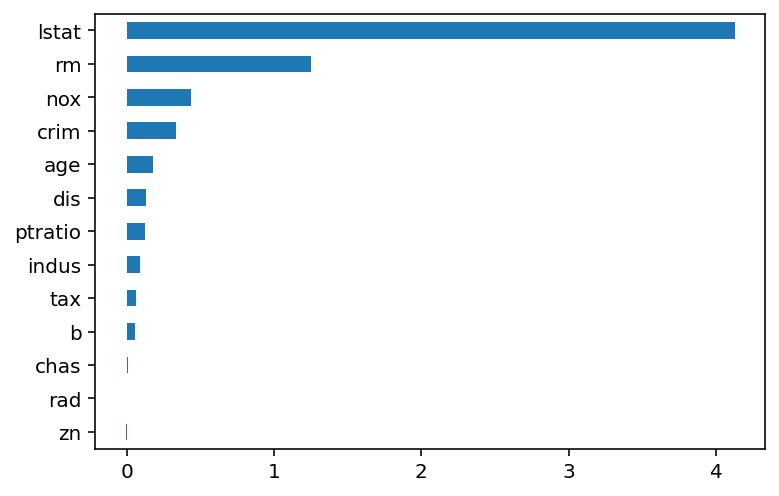
우리가 만든 모델에서 가장 중요한 특성은 lstat(하위 계층의 비율)이고, 다음으로 중요한 특성은 rm(방의 개수)이다.
4. PDP(Partial Dependence Plots)
순열 중요도가 모든 특성들이 타겟에 어떻게 작용하는지 알아볼 수 있는 도구라면, PDP(Partial Dependence Plots)는 개별 특성이 타겟에 어떻게 작용하는지 알아볼 수 있는 도구이다. PDP는 pdpbox라는 패키지를 통해서 쉽게 그릴 수 있다.
from pdpbox.pdp import pdp_isolate, pdp_plot
from pdpbox import pdp
# 방의 개수에 대한 PDP
selected_feature = 'rm'
pdp_dist = pdp_isolate(
model=pipe,
dataset=X_val,
model_features=X_val.columns,
feature=selected_feature
)
pdp.pdp_plot(pdp_dist, selected_feature);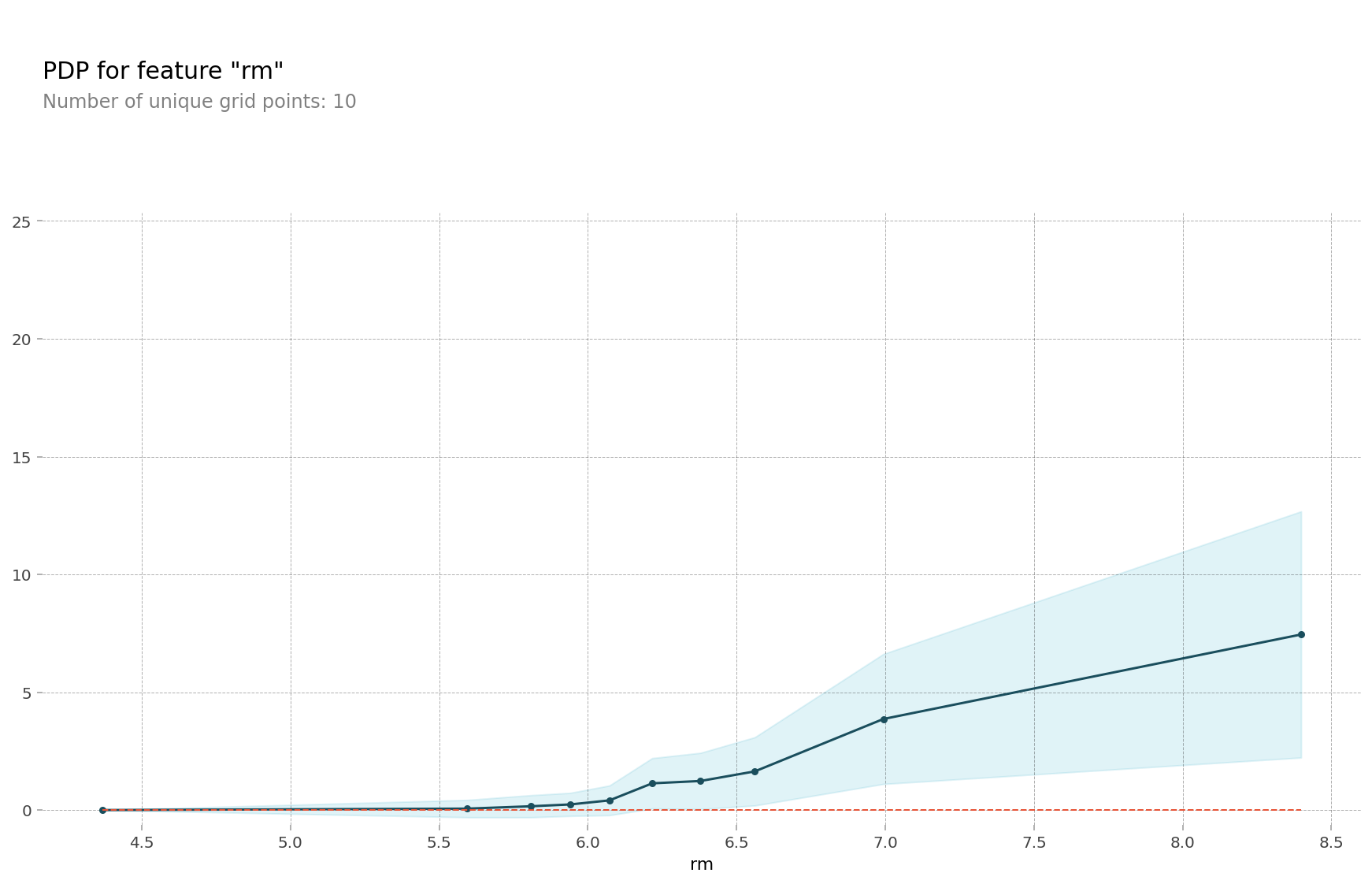
위 그림은 방의 개수에 대한 PDP이다. x축은 방의 개수, y축은 집값의 변화를 나타낸다. 그림을 통해서 방의 개수가 많아질수록 집 값이 비싸진다는 것을 알 수 있다.
# 이산화질소 농도에 대한 PDP
selected_feature = 'nox'
pdp_dist = pdp_isolate(
model=pipe,
dataset=X_val,
model_features=X_val.columns,
feature=selected_feature
)
pdp.pdp_plot(pdp_dist, selected_feature);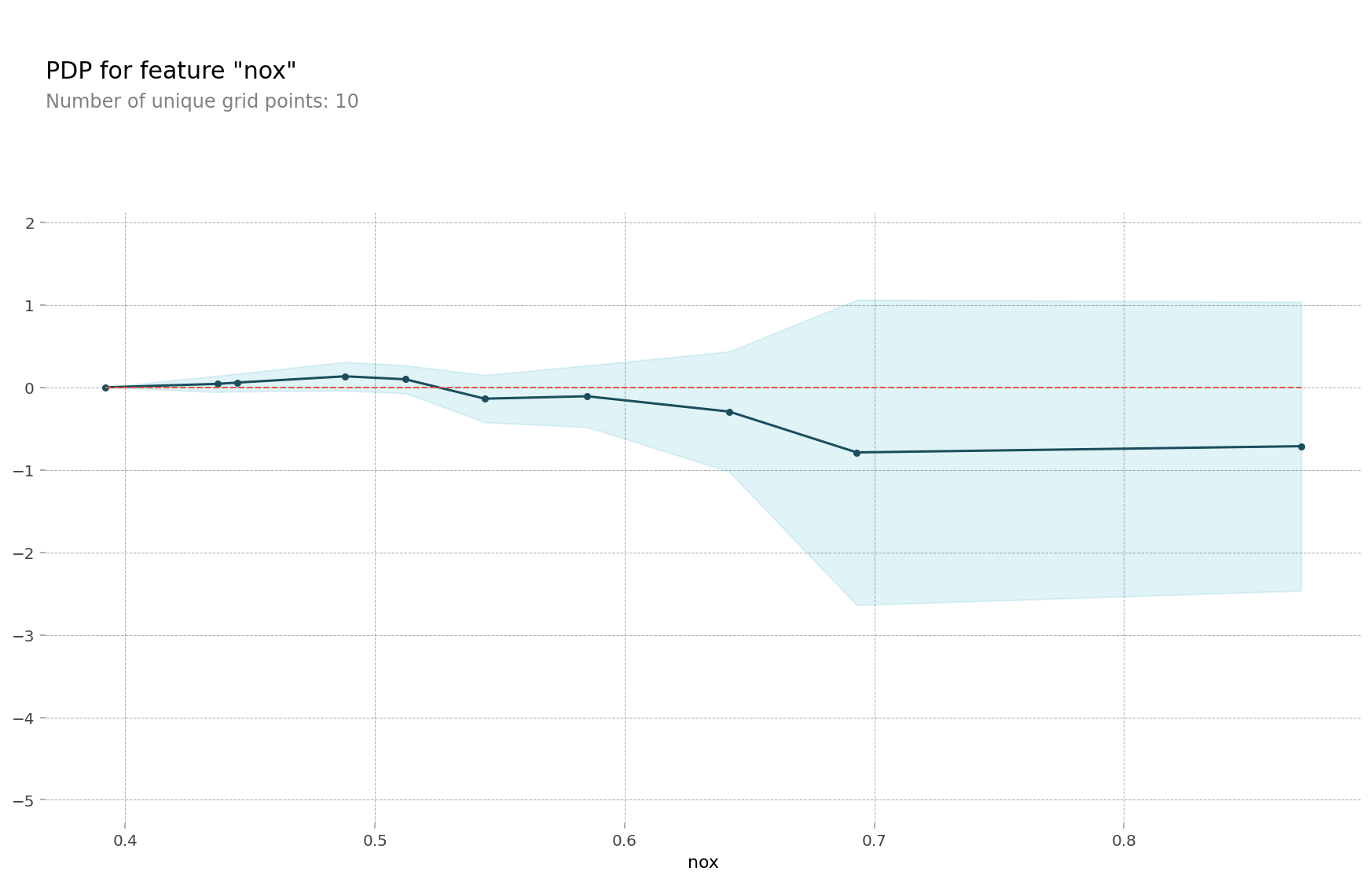
위 그림은 이산화질소 농도에 대한 PDP이다. 이산화질소 농도가 0.6이하일 때는 집 값에 미치는 영향이 비교적 미미하다. 그러나 이산화질소 농도가 0.6보다 높아지면 집 값이 떨어지게 된다.
5. 마치며
지금까지 순열 중요도와 PDP에 대해서 알아보았다. 순열 중요도를 사용하면 특성들의 중요도를 확인할 수 있으며, PDP를 사용하면 각 특성이 모델에서 어떻게 작용하는지 조금 더 구체적으로 알 수 있다. 모델을 만들고 사용하는 것만큼 중요한 건 바로 모델을 해석하는 것이다. 단순히 모델을 만드는 것은 어렵지 않다. 위에서 봤듯이, 코드 몇 줄만 입력하면 금방 모델 하나가 만들어진다. 만들어진 모델을 사용하는 건 모델을 만드는 것보다 더 쉽다. 모델을 사용하기 위해서는 코드를 몇 줄도 아니고 한 줄만 입력하면 되었다. 그러나 단순히 모델을 만들고 사용하는 것에서는 아무런 인사이트를 얻지 못한다. 각각의 특성들이 타겟에 어떤 방향으로, 얼마나 영향을 주었는지 해석할 수 있어야 인사이트도 도출해낼 수 있다. 그러므로 순열 중요도, PDP를 비롯한 여러 도구들을 적절하게 활용해서 모델을 잘 해석할 수 있는 시각을 키우도록 하자.
참고한 자료
- '전문가도 깜짝 놀라는 집단 지성의 힘과 지혜', 전지현 기자, 매일경제, 2015.10.30
https://www.mk.co.kr/news/culture/view/2015/10/1036384/

안녕하세요.. 궁금한게 있습니다. 혹시 순열중요도에서 -와 +의미를 알수 있나요