1. "A가 범인이야."
화창한 주말 오후, '오랜만에 영화나 한 편 볼까?'하며 영화 리뷰를 확인할 때면 묘한 긴장감에 사로잡힌다. 바로 스포일러(spoiler)를 만날까봐 조심스럽기 때문이다. 범인을 찾는 영화인데 범인이 누구인지 미리 알아버리고 나면 누가 범인일지 마음 졸이며 나홀로 두뇌싸움을 하는 2시간을 빼앗긴 기분이 든다. 그런데 만약 어떤 OTT 서비스나 영화 큐레이션 서비스를 이용할 때 처음으로 스포일러가 담긴 리뷰를 봤다면 그 영화에 대한 흥미가 조금 떨어진 상태에서 영화를 감상한다거나, 다른 영화를 감상하거나 할 것이다. 하지만 만약 동일한 서비스를 이용할 때 이런 경험이 반복된다면 어떨 것 같은가. 점차 해당 서비스를 사용하기가 꺼려질 것이며, 그러다 어느날 자연스레 비슷한 서비스를 제공하는 다른 플랫폼으로 떠나게 될 것이다. 띠리사 OTT 서비스, 영화 큐레이션 서비스 등에서 스포일러가 포함된 리뷰를 처리하는 것은 단순히 고객의 편의를 위한 일이 아니라, 고객 유치와 직결되는 중요한 문제이다.
그런데 만약 스포일러를 포함한 리뷰를 미리 찾아서 블라인드 처리할 수 있다면 어떨까? 사용자가 남긴 리뷰를 영화 줄거리와 비교해서 리뷰가 줄거리와 유사하다면 스포성 리뷰로, 그렇지 않다면 일반 리뷰로 분류할 수 있을 것이다. 만약 딥러닝으로 스포일러 탐지 모델을 만들고, 스포일러 리뷰를 미리 가릴 수 있다면 영화 제작자에게도, 영화 팬들에게도, 그리고 영화 리뷰 서비스를 제공하는 회사에게도 큰 도움이 될 것이다. 그래서 이번 프로젝트로는 딥러닝을 사용해서 영화의 스포일러 리뷰를 탐지하는 모델을 만들어보기로 하였다.
사용한 데이터셋
IMDB Spoiler Dataset: Can you identify which reviews have spoilers to improve user experience?
- Rishabh Misra, 2019. 05.
- doi: 10.13140/RG.2.2.11584.15362
- https://rishabhmisra.github.io/publications
- https://www.kaggle.com/rmisra/imdb-spoiler-dataset?select=IMDB_reviews.json
2. 가설 설정
영화 줄거리와 리뷰 모두 문자로 된 데이터이므로, 자연어 처리 문제이다. 자연어 처리에 대해서 찾아봤을 때 가장 많이 언급된 모델은 BERT(Bidirectional Encoder Representations from Transformers)였다. 구글에서 개발한 자연어 처리 모델로, 특정 과제에 국한되지 않고 범용적으로 사용할 수 있는 모델이라고 한다. 그래서 스포일러 댓글을 찾는 데에도 BERT를 이용할 수 있지 않을까 하여 keras의 'Semantic Similarity with BERT' 튜토리얼을 참고해서 스포일러 리뷰 탐지 모델을 만들어보았다. 그런데 문제가 하나 있었다. 바로 모델이 너무 무겁다는 점이다. 학습 시 BERT 모델을 제외한 다른 layer의 가중치만 학습되도록 설정했음에도 불구하고 한 에포크 당 학습 소요 시간이 약 14시간이라고 예상되었다. 그래서 두 문서의 유사도를 판단하는 모델 중에서 비교적 가벼운 모델을 조사해보았고, Manhattan LSTM(이하 MaLSTM)이 적합해보였다.
MaLSTM은 맨해튼 거리와 LSTM을 사용한 Siamese neural network 구조의 모델로, 아래 그림과 같은 구조로 되어있다.

(이미지 출처: Mueller, J., & Thyagarajan, A. (2015). Siamese Recurrent Architectures for Learning Sentence Similarity. AAAI-16. Arizona, USA.)
두 문서는 각각 LSTM layer를 통과하며, LSTM layer의 output을 이용해서 맨해튼 거리를 계산하고 e를 밑으로 하는 지수함수에 대입한다. 이때 두 문서가 통과하는 LSTM layer는 가중치를 공유하고 있다. 즉, 왼쪽 입력값과 오른쪽 입력값이 통과하는 layer의 종류가 같고, 각 layer는 가중치를 공유하기 때문에 Siamese neural network라고 하는 것이다. 모델의 결과값은 0 ~ 1 사이에 있으며, 두 문서 사이의 거리가 가까울수록, 즉 두 문서가 유사할수록 1에 가까운 값이 출력되고, 반대로 두 문서 사이의 거리가 멀수록, 즉 두 문서가 유사하지 않을수록 0에 가까운 값이 출력된다. 그리고 이 결과값을 활용하여 결과값이 0.5보다 크면 두 문서가 유사한 경우(스포일러인 경우)로, 그렇지 않으면 유사하지 않은 경우(스포일러가 아닌 경우)로 분류한다면 이진분류 문제를 해결할 수 있다.
MaLSTM은 그림에서 알 수 있듯이 구조가 매우 간단하다. 따라서 학습 및 예측 속도가 비교적 빠를 것이라고 생각했으며, 이 모델을 사용한다면 사용자가 리뷰를 남길 때 해당 리뷰가 스포일러인지 아닌지 빠르게 판단할 수 있을 것이라고 기대하였다. 그런데 모델을 보다보니 MaLSTM은 Embedding layer를 제외하면 결국 은닉층이 하나인 셈이고 우리는 리뷰와 영화 줄거리가 몇 % 유사한지 정확한 수치가 필요한 게 아니라 스포일러인지 아닌지 분류만 하면 되기 때문에 굳이 맨해튼 거리를 계산할 필요 없이 해당 부분을 Fully Connected layer로 대체하여 relu 함수와 sigmoid 함수를 사용하는 게 더 정확도가 높지 않을까 하는 생각이 들었다. 따라서 아래와 같은 가설을 세우고 이를 실험해보았다.
리뷰가 스포일러인지 아닌지 판단하는 이진분류 문제에서는 MaLSTM 모델보다 Siamese neural network 구조와 Fully Connected layer를 사용한 모델의 accuracy가 더 높을 것이다.
3. 가설 검정
1) 데이터 전처리 및 기준 모델 생성
데이터셋이는 영화의 시놉시스와 플롯 요약본, 그리고 리뷰 전문과 요약본이 있었다. 그런데 영화 시놉시스의 경우 평균 글자 수가 약 8,215자나 되었다. 이렇게 긴 문서를 처리하기엔 컴퓨터의 리소스가 부족해서 시놉시스가 아닌 플롯 요약본을 사용하기로 하였다. 플롯 요약본의 평균 글자수는 약 614자이다. 리뷰는 전문을 사용하였다. 그리고 플롯 요약본은 10,000자 이상인 경우, 리뷰는 2,200자 이상인 경우를 이상치로 보고 해당 데이터는 제거하였다. 이상치를 제거하고 남은 문서는 spacy를 사용하여 토큰화한 후에 'Siamese Recurrent Architectures for Learning Sentence Similarity(Mueller, J., & Thyagarajan, A.)'에서 명시한대로 Word2Vec을 사용해서 임베딩하였다. 그리고 train, validation, test 데이터셋을 각각 전체 데이터의 60%, 20%, 20%의 비율로 나누었다.

위 그림은 스포일러인 리뷰와 스포일러가 아닌 리뷰의 비율을 시각화한 것이다. 그림을 보면 알 수 있듯이 스포일러가 아닌 리뷰는 전체의 약 0.77%, 스포일러인 리뷰는 전체의 약 0.23%로 비율 차이가 크다. 따라서 주 분류 성능 평가 지표는 accuracy로 하되, f1 score를 함께 확인하기로 하였다.
기준 모델은 모든 데이터셋을 최빈 클래스인 '스포일러가 아닌 경우(0)'로 예측하는 것이다. validation 데이터셋에 대한 기준 모델의 accuracy는 약 0.7693이고, f1 score는 0이다.
2) 모델 성능 비교
MaLSTM과 Siamese neural network를 활용한 새로운 모델을 만든 뒤 accuracy와 f1 score를 비교하였다. 이때 맨해튼 거리를 사용하는 것과 Fully Connected layer를 사용하는 것의 효과를 비교하기 위해서 모델의 구조 외에 임베딩 방식, batch size, optimizer 등은 모두 통일하였다.
MaLSTM
먼저 'How to predict Quora Question Pairs using Siamese Manhattan LSTM'을 참고해서 MaLSTM 모델을 만들었다. MaLSTM 모델의 구조는 아래와 같다.
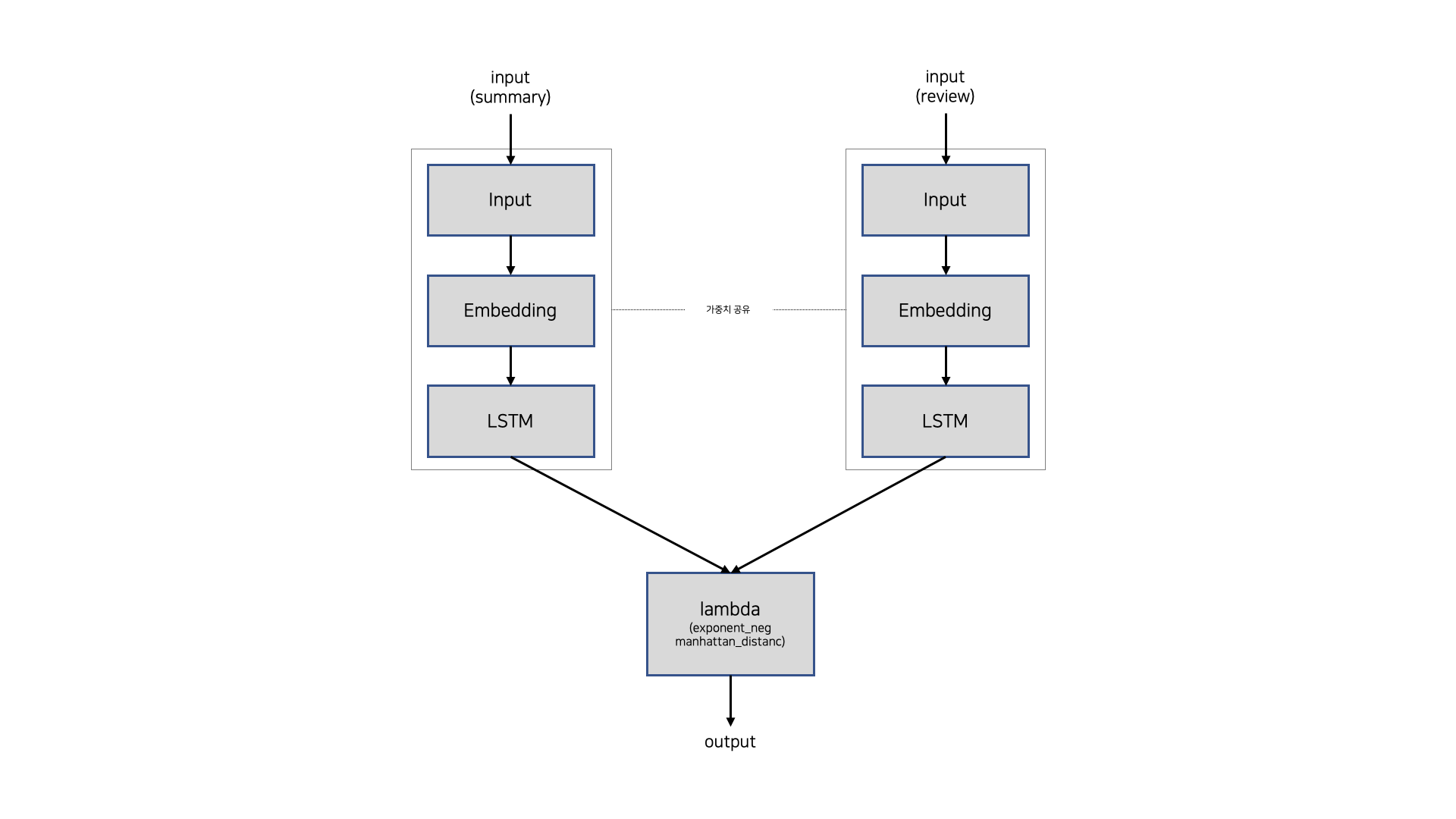
MaLSTM 모델의 validation 데이터셋에 대한 accuracy는 약 0.7731, f1 score는 약 0.2635이다. 기준 모델의 accuracy(약 0.7693), f1 score(0)보다 높으므로 학습이 잘 된 의미있는 모델이라고 할 수 있다. 하지만 모델의 성능이 생각만큼 좋지는 않았다. 혹시 thresholds를 0.5로 설정해서 그런 건 아닐까, thresholds를 변경하면 성능이 좋아지지 않을까 하여 아래와 같이 출력값과 실제 클래스를 시각화해보았으나, 출력값의 분포가 클래스 별로 차이가 없는 것으로 보아 thresholds의 문제는 아닌 것으로 보인다.

Siamese neural network LSTM + FC layer
이번에는 MaLSTM의 구조를 변형해서 새로운 모델을 만들어보았다. 새로 만든 모델의 구조는 아래와 같다.
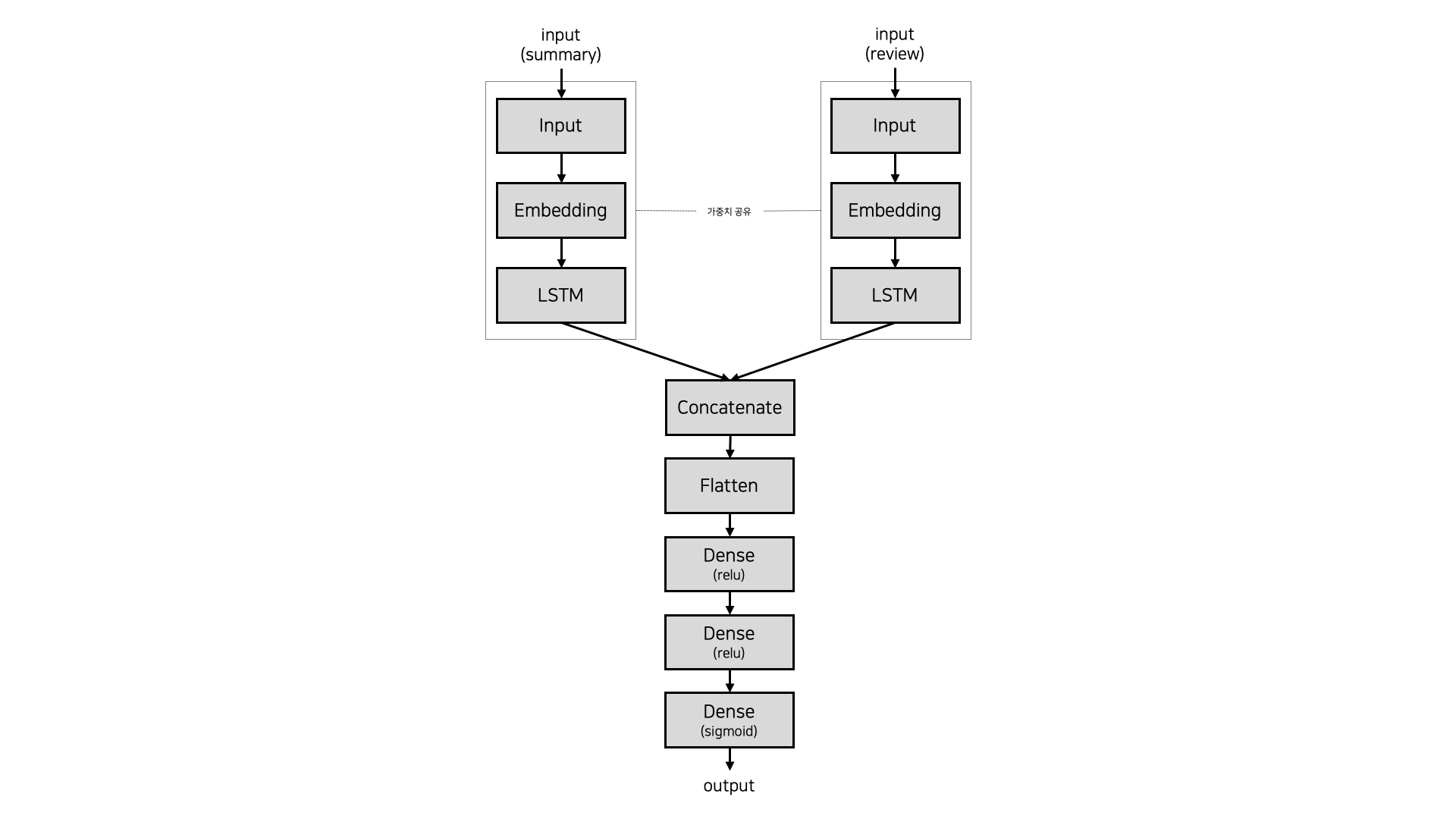
MaLSTM과 마찬가지로 Embedding layer, LSTM layer를 설정한 후에, 맨해튼 거리를 이용해서 두 문서 간 유사도를 측정하는 대신 Flatten을 거친 후 3번의 Fully Connected layer를 지나도록 하였다. Fully Connected layer의 활성화 함수는 각각 순서대로 relu, relu, sigmoid이다.
이 모델의 validation dataset에 대한 정확도는 약 0.7844, f1 score는 약 0.2801로 기준 모델보다 높기 때문에 학습이 잘 된 의미있는 모델이라고 할 수 있다. 또한 MaLSTM 모델보다도 accuracy와 f1 score가 높다. 이를 통해 '리뷰가 스포일러인지 아닌지 판단하는 이진분류 문제에서는 MaLSTM 모델보다 Siamese neural network 구조와 Fully Connected layer를 사용한 모델의 accuracy가 더 높을 것이다.'라는 가설이 맞았음을 확인할 수 있다. 다만, 맨해튼 거리를 사용했던 게 문제라기보다는 해결하고자 하는 문제가 이진분류였고, 또 은닉층의 수가 늘어났기에 성능이 좋아질 수 있었던 게 아닌가 하고 추측하였다.
4. 모델 발전시키기
1) 모델 구조 정하기
가설이 맞음은 확인하였지만 새로 만든 모델의 accuracy나 f1 score가 실제 현장에서 사용하기에는 너무 낮아보였다. 따라서 모델을 발전시켜보기로 하였다. 주어진 문제는 맨해튼 거리보다는 Fully Connected layer를 사용하는 게 더 성능이 좋다는 것을 위에서 확인하였으므로, 우선 새롭게 만든 모델의 기본적인 구조는 유지한 채 사용하는 RNN의 종류를 GRU, BiLSTM, BiGRU로 변경해서 모델을 생성한 후 그 결과를 비교하였다. 물론 이번에도 임베딩 방식, batch size, optimizer 등은 모두 통일하였다.
| accuracy | f1 score | |
|---|---|---|
| LSTM | 0.7844 | 0.2801 |
| GRU | 0.7889 | 0.3153 |
| BiLSTM | 0.7867 | 0.2972 |
| BiGRU | 0.7910 | 0.3438 |
실험 결과, 모든 모델의 accuracy와 f1 score가 기준 모델의 accuracy(약 0.7693), f1 score(0)보다 높았다. accuracy와 f1 score가 가장 높은 모델은 BiGRU를 사용한 모델로, 정확도는 약 0.7910, f1 score는 약 0.3438이다. 그리고 대체로 LSTM을 사용했을 때보다 GRU를 사용했을 때가 accuracy와 f1 score가 더 높았다.
또한 Siamese neural network에 대해서 알아보던 중에 'Predicting the Semantic Textual Similarity with Siamese CNN and LSTM'을 읽게 되었다. Convolution layer는 이미지 데이터를 다룰 때만 사용하는 줄 알았는데 자연어 처리에도 활용할 수 있다는 점이 신기해서 적용해보고 싶었다. 그래서 논문을 참고해서 위에서 만든 모델의 Embedding layer와 LSTM layer 사이에 Conv1D layer를 추가해보았다. 다만, 논문에서는 최종 출력값 산출 시 맨해튼 거리를 활용하고 있으나 이 부분은 변경해서 위와 동일하게 Fully Connected layer 3개를 사용하였다. 만든 모델의 accuracy, f1 score는 아래와 같다.
| accuracy | f1 score | |
|---|---|---|
| Conv1D + LSTM | 0.7932 | 0.4079 |
| Conv1D + GRU | 0.7918 | 0.3719 |
| Conv1D + BiLSTM | 0.7923 | 0.4123 |
RNN layer의 종류와 상관없이 Conv1D layer를 사용했을 때의 accuracy와 f1 score가 사용하지 않았을 때보다 높았다. 그런데 Conv1D layer를 사용할 때는 GRU를 사용했을 때보다 LSTM을 사용했을 때가 accuracy와 f1 score 더 높았다는 차이가 있었다. 가장 성능이 좋은 모델은 Conv1D와 LSTM layer를 사용했을 때이며, accuracy는 약 0.7932, f1 score는 약 0.4079이다.
마지막으로 Siamese CNN and LSTM에 대해서 알아보던 중에 클린봇 2.0: 문맥을 이해하는 악성 댓글(단문) 탐지 AI라는 네이버 기술 블로그 글을 읽게 되었는데, 문제가 다르기에 모델 구조는 다르지만 스포일러 리뷰를 찾는 문제도 Convolution, BiLSTM, LSTM layer를 함께 사용한다면 모델의 성능이 더 올라가지 않을까 궁금해졌다. 그래서 Conv1D layer와 BiLSTM, LSTM을 모두 활용해서 모델을 만들어보았다. 다만 단순히 layer의 추가 때문에 성능이 좋아진 것인지, BiLSTM과 LSTM의 순서가 중요한 것인지 알아보기 위해서 아래와 같은 3가지 종류의 모델을 만들어보았다.
| accuracy | f1 score | |
|---|---|---|
| Conv1D + BiLSTM + LSTM | 0.7955 | 0.3689 |
| Conv1D + LSTM + LSTM | 0.7969 | 0.3530 |
| Conv1D + LSTM + BiLSTM | 0.7967 | 0.3926 |
실험 결과, 은닉칭이 하나 더 추가되어서인지 모든 모델이 이전 모델보다 accuracy가 올라갔다. 다만 f1 score는 조금 떨어졌다. 그리고 가장 성능이 좋은 모델은 Conv1D, BiLSTM, LSTM layer를 사용한 모델이 아니라 Conv1D와 LSTM layer 2개를 사용한 모델이었다. 이 모델의 accuracy는 약 0.7969로 만들었던 모델 중에서 가장 accuracy가 높다.
2) cv를 사용한 하이퍼 파라미터 튜닝
만들었던 모델 중 가장 accuracy가 높았던 모델인 Conv1D layer와 LSTM layer 2개를 사용한 모델을 cv를 이용해서 하이퍼 파라미터 튜닝을 하여 최종 모델을 만들었다. LSTM layer를 2개를 썼더니 RNN 계열 layer를 하나만 썼을 때보다 떨어진 게 조금 마음에 걸렸으나 가설 검정 전에 주 평가 지표는 accuracy로 정했었고, 또 기준 모델의 f1 score(0)과 MaLSTM 모델의 f1 score(약 0.2635)보다는 높기 때문에 이 모델을 선택하였다. 하이퍼 파라미터의 튜닝 순서와 cv 결과 설정된 각 하이퍼 파라미터의 값은 아래와 같다.
- optimizer learning rate: 0.001
- Conv1D layer filter_size: 2
- LSTM layer units
- 첫번째 layer: 50
- 두번째 layer: 100
- dropout 비율: 0.2
- Fully Connected layer units
- 첫번째 layer: 128
- 두번째 layer: 64
- batch size: 128
만들어진 최종 모델의 구조는 아래와 같다.
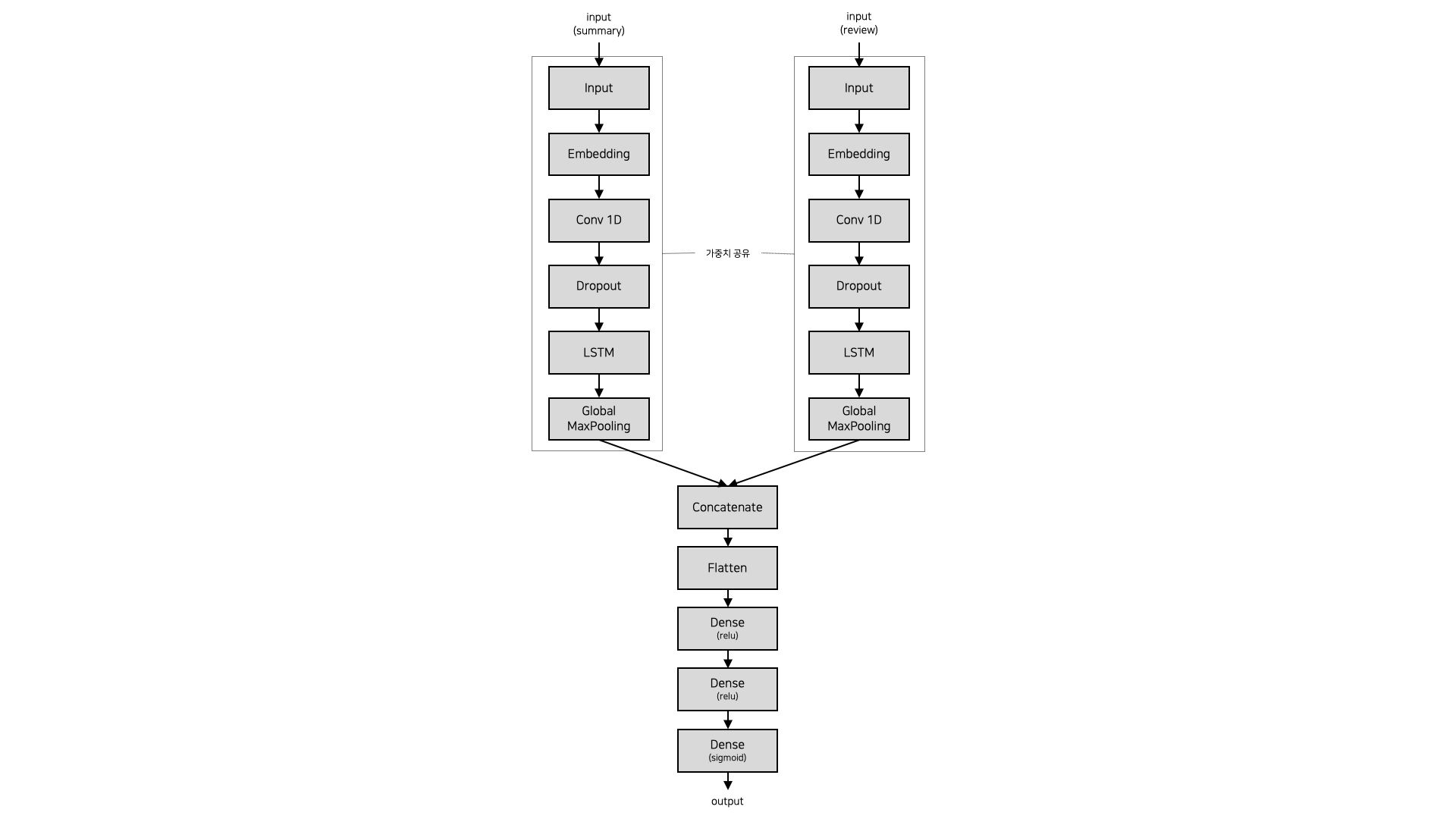
3) 최종 모델의 test 데이터셋에 대한 결과
precision recall f1-score support
0 0.82 0.96 0.88 58910
1 0.67 0.28 0.40 17664
accuracy 0.80 76574
macro avg 0.74 0.62 0.64 76574
weighted avg 0.78 0.80 0.77 76574최종 모델의 test 데이터셋에 대한 accuracy는 약 0.8025이고, f1 score는 약 0.4000이다.
5. 모델 성능에 대한 고찰
지금까지의 과정을 통해서 기준 모델보다 성능이 좋은 모델을 만들긴 하였지만, 아직 아쉬운 점이 많다. test 데이터셋에 대한 예측 결과만 봐도 recall이 약 0.28로 전체 스포일러 리뷰 중에서 스포일러라고 예측된 리뷰는 약 28%밖에 되지 않는다. 그래서 모델을 만들기 위해 고민해야 할 부분과 모델의 성능을 올릴 수 있는 방안에 대해서 생각해보았다.
1) 스포일러에 대한 명확한 정의가 필요하다.
모델을 만들 때 input으로 플롯 요약본과 리뷰 전문을 사용하였다. 플롯 요약본은 말 그대로 영화 내용을 처음부터 끝까지 요약해놓은 것이다. 그런데 영화를 보기 전에 모두가 이미 알 수 있는 내용도 있다. 예를 들어, 아래 내용은 네이버가 제공하는 해리 포터와 비밀의 방(2002) 영화 소개 일부를 발췌한 것이다.
... 개학을 앞두고 학교에 가는 날, 론과 해리는 뭔가의 방해로 9와 3/4 승강장에 못 들어가는 바람에 개학식에 지각할 위기에 처한다. 결국 하늘을 나는 자동차 포드 앵글리아를 타고 천신만고끝에 학교에 도착했으나 공교롭게도 차가 학교 선생님들이 소중히 여기는 '커다란 버드나무' 위에 불시착하는 바람에 화가 난 스네이프 교수로부터 퇴학 경고를 받게 된다. ...
https://movie.naver.com/movie/bi/mi/basic.nhn?code=33930
해리 포터와 비밀의 방을 보기 전에도 위 영화 소개 때문에 누구라도 해리 포터가 개학식날 하늘을 나는 자동차를 타고 학교에 갈 것이라는 걸 알 수 있다. 그런데 만약 리뷰에 '해리 포터가 자동차를 타고 하늘을 나는 장면에서 동심으로 돌아간 것 같았어요.'라는 리뷰를 남겼다면 이 리뷰를 스포일러라고 해야 할까, 아니라고 해야할까? 만약 영화의 어떠한 부분이라도 언급하면 스포일러로 간주하기로 결정했다면 위 리뷰도 스포일러이지만, 영화 소개에서 알 수 있는 내용은 스포일러가 아니라고 하기로 결정했다면 영화 소개에 있는 내용은 제외한 후에 리뷰와 비교를 해야 하며, 스포일러라고 생각되는 부분에 대한 자세한 서술이 필요하다. 즉, 스포일러의 정의에 따라서 사용할 데이터의 내용이 바뀌어야 한다. 프로젝트를 할 때는 컴퓨터 리소스 때문에 평균 글자 수가 614인 플롯 요약본을 사용하였다. 플롯 요약본은 말 그대로 요약본이므로 영화의 모든 내용을 자세하게 담고 있지 않으며, 영화 소개에는 나오지 않는 결말에 대해서 자세하게 서술하고 있는 것도 아니기 때문에 스포일러에 대한 정의가 무엇이든 플롯 요약본만으로 스포일러 리뷰를 잡아내는 건 어렵지 않았을까 하는 생각이 든다.
2) 임베딩 방법을 바꿔보자.
이번 프로젝트의 가설은 MaLSTM 모델과 새로 만든 모델의 성능을 비교하는 것이었고, 정확한 비교를 위해서 임베딩 방식을 통일하느라 MaLSTM을 설명한 논문인 'Siamese Recurrent Architectures for Learning Sentence Similarity.'에서 언급한대로 Word2Vec을 사용해서 임베딩하였다. 하지만 자연어 처리는 임베딩을 어떻게 하느냐에 따라서 결과가 크게 달라진다. 따라서 GloVe 임베딩과 같은 다른 방식을 사용한다면 모델의 성능을 개선할 수 있을 것이라고 생각한다.
참고 문헌
-
Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1746–1751.
https://arxiv.org/abs/1408.5882 -
Mueller, J., & Thyagarajan, A. (2015). Siamese Recurrent Architectures for Learning Sentence Similarity. AAAI-16. Arizona, USA.
-
Pontes, E., & Huet, S., & Linhares, A., Torres-Moreno, J. (2018). Predicting the Semantic Textual Similarity with Siamese CNN and LSTM. Traitement Automatique des Langues Naturelles (TALN), 1, 311–320.
https://arxiv.org/abs/1810.10641
